What Is Enterprise Technical Debt?

During architecture evaluations, we typically identify technical-debt issues within a single system or project. However, the impact of technical debt often reaches beyond the scope of a single system or project. In our work, we refer to this form of technical debt as enterprise technical debt. Like all technical debt, enterprise technical debt consists of choices expedient in the short term, but often problematic over the long term. Ignoring enterprise technical debt can have significant consequences, so architects should be alert for it, and they should not let it get overlooked or ignored when they come across it. In this post, I provide examples of enterprise technical debt (and the risk it represents) taken from real-world projects.
As architecture evaluators, we have the unique opportunity to view architectural risks from more of an enterprise perspective (as opposed to project-level), particularly if we are participating in evaluations for a portfolio of projects. Over the past several years, the SEI has leveraged SEI technical-debt research to institutionalize technical-debt practices at an organization with a large portfolio of systems valued at over $100 million. This organization has a portfolio of more than two dozen business applications and follows a decentralized IT governance model. The examples in this post came from our work as architecture evaluators on these projects.
To make enterprise technical debt more concrete to readers, I provide three examples of enterprise technical debt items and consequences. In a future post, I will go into greater detail about documenting and remediating enterprise technical debt.
Example 1: A Brittle System-Integration Solution
In this example (Figure 1), project requirements called for exchanging data between Applications A and B. The project teams made an architectural decision to use a shared database schema as the data-exchange mechanism. This approach was appealing to the teams at the time since it was easy to implement, but later it became evident that this solution was brittle. In particular, when Team A made an independent change to shared schema without coordinating with Team B, Application B had to also make changes to accommodate and vice versa.
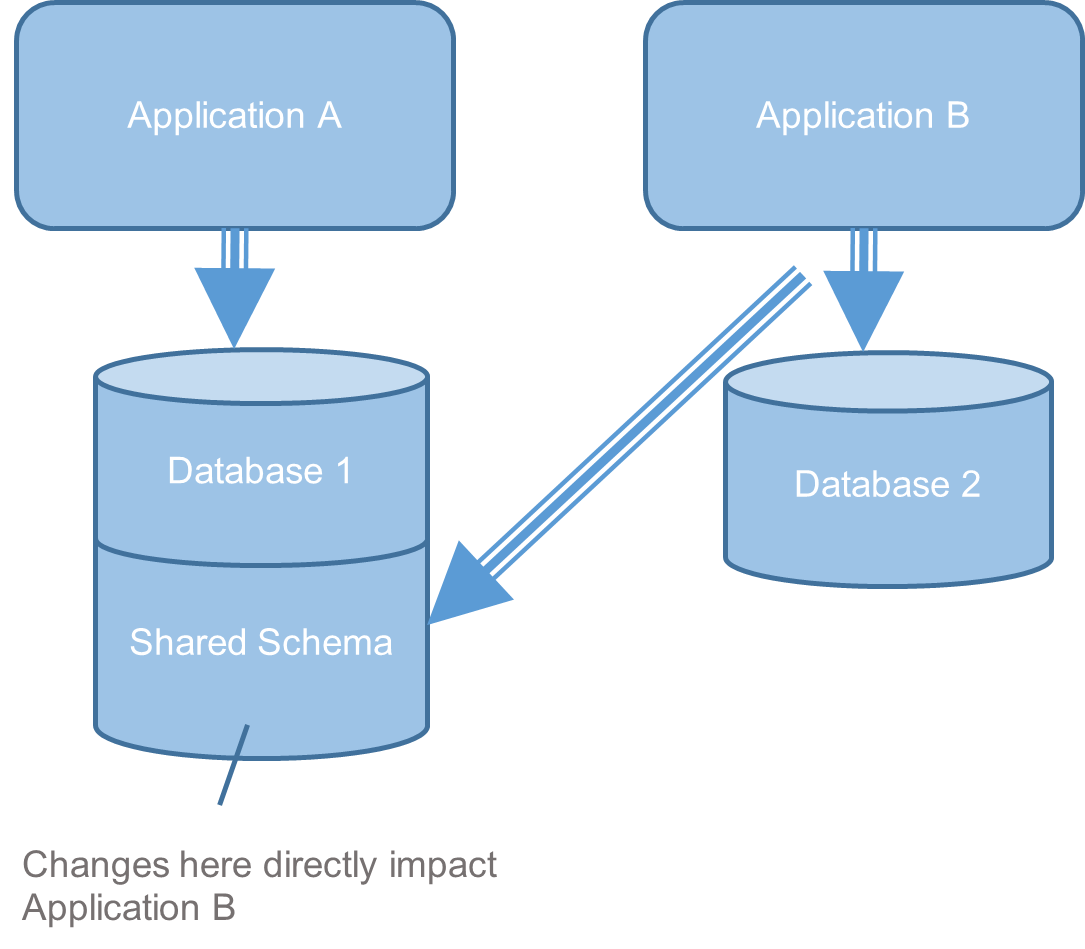
The teams came up with a workaround that made matters worse. The developers copied data in their local environments to avoid changing the schema. The teams created extract, transform, load (ETL) jobs to keep data synchronized that were unreliable. When an ETL job failed, data was left in an inconsistent state. For example, after failures, users would get different historical query responses from Application A and Application B. Project feature delivery also slowed because schema changes required time-consuming analysis.
Both teams were satisfied with the shared schema—at least in the short term. However, from our architecture evaluation, which gives us an external and enterprise-level perspective, we could see that the negative consequences of this solution were likely to increase over time as functionality grew. For this reason, we recommended replacing the brittle shared-schema solution with an application programming interface (API) for application data exchange.
The teams readily accepted the proposed technical solution, but the organization did not act to fix the issue initially for several reasons. First, in this decentralized governance environment, neither team felt responsible for the refactoring work. Second, fixing a brittle integration solution was not viewed as a priority to the business. Therefore, the product owners would not allocate project funds to the redesign effort. Although no action would be taken in the near term, we created a technical debt item—a written description of the issue and consequence. Documenting the issue as a technical debt item allowed the organization to make it visible and work on a longer-range strategy to rework the solution. I will provide examples of these technical debt items we created in a future blog post.
Example 2: Heterogeneous Access and Authentication-Control Solutions
As architecture evaluators for this organization, we reviewed several project architectures in which the teams were implementing duplicative authentication and access-control capability. Duplicative capabilities included
- ability to store role and permission information
- administrative capability to add, change, and delete user permissions
- secure token generation
- ability to set and enforce access-control policies for software services (API calls)
A common access and authentication capability was not provided, so the individual teams implemented this capability in a heterogeneous manner. Figure 2 depicts three different implementation styles we observed.
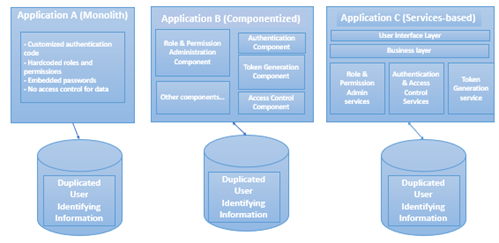
- Application A is a legacy application developed as a monolith, which is outdated and has several drawbacks. For example, the teams wrote custom authentication code instead of using secure, verified vendor components. We also found that roles and permission information were hard-coded, and less secure password credentials were used instead of tokens for certification. Finally, there was no application-level security check at the data-access layer.
- Application B was a more modern implementation with a component-based architectural style. In this implementation, there was separation of authentication and access-control capability into components (e.g., roles and permissions administration, authentication, token generation, access control). These components were shareable by multiple consumers.
- Application C had a service-oriented architecture. Services used were role and permission administration, authentication, token generation, and access control.
These heterogeneous authentication and access-control solutions ultimately resulted in increased security and maintenance risk. For example, without a common administration module, user accounts were deactivated (rather than deleted), leaving the organization open to impersonation attacks. In addition, changing user permissions involved running error-prone manual database scripts to update several databases. Instead of storing user-identifying data in a single secure, authoritative data source, that data was stored haphazardly in various operational project databases.
Again, the project teams saw no problems with this situation. When viewed from the enterprise perspective, however, the security and maintenance risks were clear. To make this debt visible, we created a technical debt item and worked with the organization to get it prioritized. I will share the technical debt item we created for this example in the next post.
Example 3: Data-Warehouse Refresh Issue
Years ago, the organization invested in building an extensive data warehouse. During architecture evaluations, we found that several teams were not using the data-warehouse reporting. Rather, they were running many complex nightly database jobs to copy historical data to their local databases. We found that the root cause for this approach was a 48-hour lag in updating data to the data warehouse. Users were not satisfied with viewing stale data, which left the data warehouse underutilized and added unnecessary complexity to the ecosystem.
Once again, this situation was fine with the project teams. When analyzed from the enterprise perspective, however, the business and maintenance/cost risks became clear. For example, the data copying caused an explosion in data-storage usage. Complying to records-management requirements became a nightmare after extensive copying made authoritative data sources unclear. Operations and maintenance staff complained about spending time monitoring and updating the complex web of ETL synchronization jobs. As a result, we created a technical debt item documenting the problem and recommended a redesign to reduce data-warehouse lag time.
Looking Ahead
In this post, I described three examples of enterprise technical debt. We illustrated, through example, the elusive nature of enterprise technical debt and the potential impact unchecked enterprise technical debt can have on an organization. In our examples the impact of ETD items wasn’t felt at the technical level. However, ignoring it resulted in multi-project or organization-wide risks. These in turn increased cost, efficiency, or security risks for the organization. I also discussed the architect’s role in applying technical debt practices to track and remediate technical debt. In my next post, I will describe how we remediated these examples and how we guided teams to apply technical debt and governance practices to motivate action.
Additional Resources
Learn more about the SEI’s research on technical debt by visiting our Technical Debt Project Page.
Read the SEI Blog post Experiences Documenting and Remediating Enterprise Technical Debt.
Written By

More By The Author
More In Software Architecture
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed