Got Technical Debt? Track Technical Debt to Improve Your Development Practices

What is technical debt? Why identify technical debt? Shouldn't it be captured as defects and bugs? Concretely communicating technical debt and its consequences is of interest to both researchers and software engineers. Without validated tools and techniques to achieve this goal with repeatable results, developers resort to ad hoc practices, most commonly using issue trackers or backlog-management practices to capture and track technical debt. We examined 1,264 issues from four issue trackers used in open-source industry and government projects and identified 109 examples of technical debt. Our study, documented in the paper Got Technical Debt? Surfacing Elusive Technical Debt in Issue Trackers, revealed that technical debt has entered the vernacular of developers as they discuss development tasks through issue trackers. Even when developers did not explicitly label issues as technical debt, it was possible to identify technical debt items in these issue trackers using a classification method we developed. We use our results to motivate an improved definition of technical debt and an approach to explicitly report it in issue trackers. In this blog post, we describe our classification method and some implications of tracking debt for both practice and research.
Identify and Classify Technical Debt
To understand how software developers use issue trackers to communicate technical debt, we conducted an exploratory study of four issue trackers: the Chromium and CONNECT Health IT Exchange open-source projects and two government IT projects. We found that when determining whether an issue represents technical debt, experts apply unspoken and informal rules and practices. We observed this in a manual examination of 1,264 issues from the four issue trackers, as well as from the technical debt literature (for example, Guo 2011, Li 2014, Potdar 2014, and Ernst 2015). Our goal in developing a classification method for technical debt is to make identification of it explicit and to enable repeatable classification of issues. Here we summarize the key decision points in our process:
- Executable or data related: One source of confusion about technical debt is overgeneralizing the concept by including project management activities, such as documentation, requirements analysis, and quality assessment. For development teams to act on technical debt, it must be related to concrete development artifacts, such as code, implementation units, data models, build scripts, and unit tests. We classified any issue that did not mention a concrete development artifact as not technical debt. Classification from this point onward requires articulation of fuzzy concepts, such as defect, bug, and design concerns. Defects and bugs are incorrect functionalities visible to end users; technical debt tends to result from design and system issues not visible to the user. We separated defects from system improvement issues. Similarly, we separated new features, a type of system improvement, from cases where underlying design limitations resulted in feature requests.
- Type > Defect type > Incorrect functionality: We found many examples of defects that are describing how the system is not behaving as specified or expected. For example, a button doesn't work in the user interface or the system crashes. We classified these issues as not technical debt.
- Type > Defect type > Design consideration: Several defects affected a quality attribute, such as availability, security, or performance; in other items, cleanup activities affected maintainability. We classified these issues as design considerations. If we also found evidence of accumulation of unintended side effects, or an estimate that they would accumulate; we classified these issues as technical debt. Examples include duplicate code, nonstandard binding, type mismatches, inconsistent implementation, and unused classes.
- Type > Improvement type > Feature: We classified new features that were system improvements, such as adding a new node to a sensor component or removing a drop-down box, as not technical debt.
- Type > Improvement type > Design limitation: Some issues described system improvements to remedy design limitations, such as the inability to add a new feature quickly, maintainability issues, or consequences of refactoring. To handle such cases, we introduced the design limitation category. When evidence of side effects was not clear, even for issues that clearly mentioned refactoring to remedy a design limitation, we classified the issue as not technical debt.
Our classification method therefore refines the definition of technical debt as "design work related to software units that may carry present or anticipated accumulation of extra work." We use the term "design work" in the general sense to mean that some aspect of the problem is caused by the structure or quality of the software design, (and so we include implemented system design under this definition). Figure 1 illustrates our current understanding of the categories and a flow tree for classifying technical debt. The approach we used to classify technical debt in issue trackers can also help practitioners define and identify technical debt in their development projects.
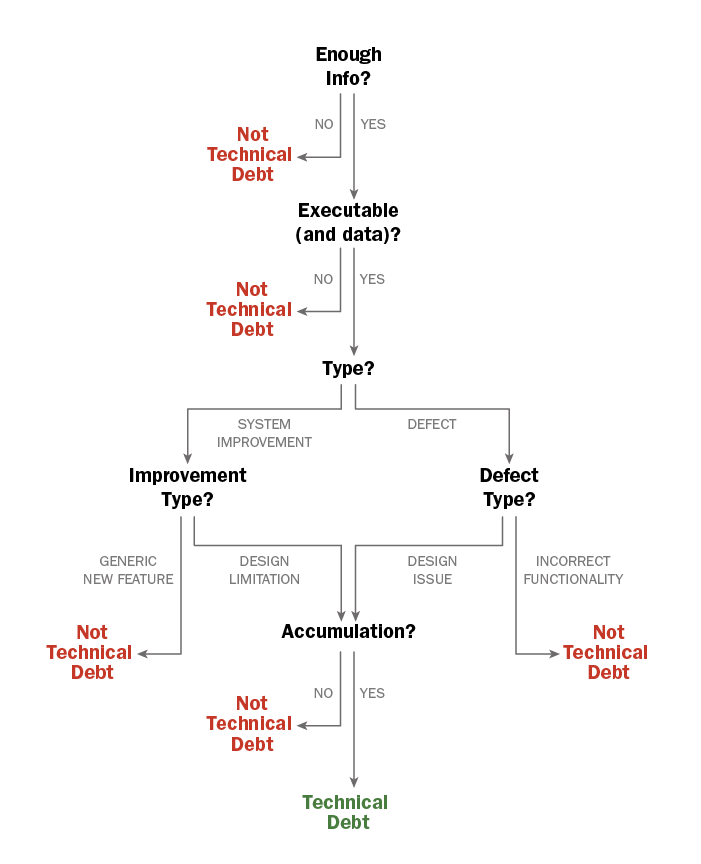
Figure 1: How we worked through the process of identifying and classifying technical debt.
Improve Development Practices with a Method for Recognizing Technical Debt
Issue trackers serve as an entry point for communicating technical debt because developers use them to manage task priorities. Survey feedback from developers indicated that even when they include details about technical debt in an issue tracker, they may not prioritize paying back the debt or they may address its symptoms but not the underlying causes. Our findings offer some practical improvements to make technical debt more visible.
There are standards (such as ISO/IEC 25010:2011) for providing bug reports with enough information so they can be reproduced and fixed. These essential properties are encoded in predefined fields in issue trackers. These fields are necessary but not sufficient for describing technical debt. Recent research (such as Zazvorka 2013 and Li 2014) on technical debt has offered templates for reporting technical debt. This work has similar goals to our work, but the templates use concepts driven by the financial analogy, such as estimating principal and interest, that do not overlap with the daily tasks of developers.
Our analysis demonstrates that technical debt becomes concrete when it relates to software units, as opposed to software process artifacts, such as requirements or documentation. This refined scope helps developers and their stakeholders understand technical debt as the accumulation of technical debt items associated with a software-reliant system.
A technical debt item is a single element of technical debt that connects a set of development artifacts. It has consequences for the quality, value, and cost of the system. Likewise, it is triggered by causes related to process, management, context, and business goals. A technical debt item should be described using the properties in Table 1, which are based on the concepts for classifying technical debt (shown in bold).

Introducing these properties can help developers understand tradeoffs and the longer-term consequences of technical debt. It can also help them make a case for additional resources when communicating to management. We suggest that developers use these properties to write issue descriptions that make technical debt visible and to increase the degree of automation possible in classifying issues as technical debt. Table 2 shows an example of organizing the issue text according to these properties from a CONNECT issue.

The properties can also help developers parse the issues and identify what is ambiguous or missing. For example, without explicit information about debt accumulation, the issue cannot be properly classified nor the tradeoffs understood. Technical debt should foster dialogue between business and technical actors. Classifying issues as technical debt allows developers to justify budgeting project resources for paying back debt similarly to allocating a budget for fixing defects, instead of continuing to pay the ongoing cost of addressing only the symptoms.
Summary of Findings and Future Work
After reviewing the results of our study, we hypothesize that developers can use automated text analysis and machine-learning techniques to discover technical debt issues more systematically. To explore this hypothesis, we ran a search on a sample set of the issues we examined for the following words: duplicate, custom, workaround, inconsistent, hack, legacy, rewrite, cleanup, refactor, and refresh. We hypothesized that we would find a statistically significant difference between the percentage of issues that contain one of these key words and are technical debt when compared with the set of issues that contain a key word but were not classified as technical debt. We observe that 67 percent of the issues contained one of the key words and were classified as carrying debt. Only 8 percent fell in the latter category. These findings suggest that automated word searches of key concepts related to technical debt hold promise, but more experimentation is needed with larger data sets.
Assessing accumulation was one of the biggest challenges we observed with systematically classifying technical debt issues in this study. Such an assessment is hard for two reasons:
- First, the language used by developers to describe accumulation is even less explicit than the design issue description. For example, developers wrote, "so much time has passed that now we have duplicate data," "this may lead to confusion for users," or "we should try to simplify so it is easier to maintain." The unstructured language that indicates accumulation of debt makes it hard for reviewers to classify an item consistently, for developers to assess impact, and for researchers to study how to automate technical debt classification.
- Second, issues often included three types of accumulation information: (1) existing accumulation related to the current problem, (2) future recurring accumulation related to the current problem, and (3) accumulation related to the potential solution of the current problem. For this study, we limited the scope of accumulation to Type 1. Future research is needed to better define and model accumulation of debt in terms of the costs of not fixing the problem and the added costs of fixing the problem later.
Our findings indicate several future research opportunities, and our plans include the following:
- Evaluate other techniques for mining unstructured data to locate technical debt in software repositories.
- Trace technical debt in the developer text discussion to code through the commit log to evaluate efficacy of self-reported debt in issue trackers.
- Model dimensions of accumulation in terms of cost to fix, cost to not fix, and the influence of time (current and future costs) to improve guidelines for managing technical debt.
- Build on the investment in the Chromium data set to conduct correlation studies with defects and software vulnerabilities to better understand the relationships among these kinds of software anomalies.
We welcome your feedback on our classification for technical debt and technical debt item description in the comments section below. If you would like to try out the classification approach, the decision flow description from our study can be found in a classification guidance accessible on the SEI website. This study is part of a wider SEI effort on technical debt. If you would like to collaborate on a study of managing technical debt, please get in touch.
Additional Resources
Read about our recent work on managing technical debt in the following publications:
- Avgeriou, P., Kruchten, P., Nord, R., Ozkaya, I., and Seaman, C. 2016. Reducing Friction in Software Development. IEEE Software 33, 1 (2016), 66−73.
- Bellomo, S., Nord, R. L., Ozkaya, I., and Popeck, M. Got Technical Debt? Surfacing Elusive Technical Debt in Issue Trackers. Mining Software Repositories 2016, co-located with ICSE 2016, in Austin, Texas, May 2016.
- Bellomo, S., Nord, R. L., Ozkaya, I., and Popeck, M. Technical Debt Classification Approach and Technical Debt Issue Examples. Sample data set and classification guidance for the conference paper Got Technical Debt.
- Ernst, N., Bellomo, S., Ozkaya, I., Nord, R. L., and Gorton, I. Measure It? Manage It? Ignore It? Software Practitioners and Technical Debt. In Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, 50−60. ACM, 2015.
Written By

More By The Author
More In Technical Debt
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Technical Debt
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed