Software Isolation: Why It Matters to Software Evolution and Why Everybody Puts It Off

The SEI is conducting research to help organizations significantly improve the time it takes to evolve their software, but why is software evolution relevant to organizations, and what is holding them back? Software gets messy (e.g., unwanted dependencies, duplicated or highly coupled functionality, overly complex or entangled implementations, etc.) over time as new features and requirement changes are introduced. Messy software costs money in terms of a developer’s time and an organization’s ability to respond to rapidly changing environments.
The changes required to improve and evolve software to allow organizations to work efficiently can be invasive and long-lived (i.e., months, if not years). Making these changes this often requires software isolation—the segregation of software capabilities to achieve a specific goal, such as creating a library, standing up a service in the cloud, abstracting away a hardware platform, or achieving some goal such as reusability, modularity, or scalability. Software isolation remains a labor-intensive activity, however, with little or no help from tools that can speed up the process. This SEI Blog post discusses the practice of software isolation, which is one of the steps in large-scale refactoring efforts that most software development organizations go through.
The Importance of Software Isolation
In today’s fast-moving environments, organizations push development teams to deliver software on time and on budget. But a changing environment can outpace development teams, and unforeseen use cases and new requirements can force changes to the development plan. Such changes add complexity to the software, which can cause it to degrade.
As software degrades, it becomes less maintainable, which in turn increases development times. When organizations need to add new features to the software, they then must make a tough choice between two alternatives:
- add new features on top of the existing software, perhaps inelegantly, working around a potentially decaying architecture, or
- refactor the software first, so that it is easier to add the new (and future) features, but incur added development costs, delaying feature deliveries.
Large-scale refactoring—pervasive or extensive changes requiring substantial commitment of resources—involves many steps. Organizations must plan the effort; allocate developers to the project who may need to learn to use new platforms, frameworks, or tools; devise a strategy to introduce the new changes into production; and solve other problems caused by major changes. But most large-scale refactoring efforts have something in common: when modifying the software, developers must extract functionality for some purpose (i.e., they must perform software isolation).
The Organizational Challenge of Software Refactoring
In practice, organizations often choose to add features on top of existing software, because refactoring first does not have an obvious return on investment. Refactoring potentially introduces risks, costs money, and occupies valuable developer time that could be used to deliver new features instead. In a survey conducted by the SEI, 71 percent of respondents indicated that “there were occasions when they wanted to conduct large-scale refactoring, but had not done so.” The most common reasons why organizations decided not to perform large-scale refactoring were “new features were prioritized over refactoring” (>60 percent) and “the anticipated cost was too high” (>50 percent).
These decisions repeat and compound over the life of the software as new features are continuously added and prioritized over refactoring. After a few years or even decades, the result is a brittle product whose architecture is no longer fit for its purpose, perhaps not even understood or known. Features become hard to add, development and test times increase, bugs appear unexpectedly, and updates slow down. Software becomes hard to understand and hard to work with. An organization knows it has reached this point when no one on the development team wants to make changes to the product, or when only one person can (or dares to) make changes to certain areas in the code. It happens to even the most well-planned software systems.
At this point, organizations recognize that their pain has reached a tipping point, and they finally decide to perform large-scale refactoring on their software. Other motivations may also prompt this decision, such as a need to change current operational strategies by reducing the overhead of maintaining private infrastructure by moving to the cloud. Either way, organizations recognize the need to perform a large-scale refactoring to remain relevant. Enter software isolation.
What Is Software Isolation?
Software isolation refers to the act of separating existing capabilities—or functions—from existing code and is one of the steps in a large-scale refactoring. Developers begin with some goal in mind. Maybe they need to extract an existing capability to transform it into a stand-alone service, or perhaps they want to break a monolith application into a series of microservices. These are all software isolation activities. Software isolation can serve several purposes:
- isolating code into a stand-alone service
- One of the most popular techniques for scaling software is to replicate the running instances of a given capability. For example, developers may want to spin off instances of an email application to serve requests and to send action confirmations in a personnel management application. Before they can extract the emailing capability from their existing application, they need to isolate it so that they can later create a stand-alone service that can be replicated.
- Teams often need to move application capabilities to different or independent environments, usually as part of a growth effort. For example, they may want to break a monolith into a series of microservices, or they may want to extract the authentication capability into its own microservice to use it in an authentication-as-a-service manner. Isolation enables developers to extract the desired capabilities into stand-alone microservices that can be deployed independently.
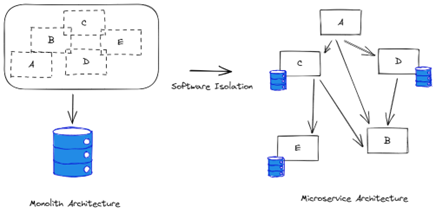
- isolating code to migrate to new platforms
- As cloud platforms become more ubiquitous, many organizations are looking for ways to migrate their services to these platforms to benefit from shared platform management (whether private or public). They usually begin by porting specific services to the new platform, starting with low-risk ones. As they become more comfortable with the new platform, they start migrating more mission-critical services. In all cases, software isolation plays a central role in separating existing software capabilities into services that can be natively hosted in the cloud as opposed to simply following a lift-and-shift approach.
- Platform migration is not just limited to the cloud platforms. Depending on the application, organizations may be performing a similar task in migrating capabilities to other platforms, such as Internet of Things devices. Either way, teams must first isolate the capability before they can move it.
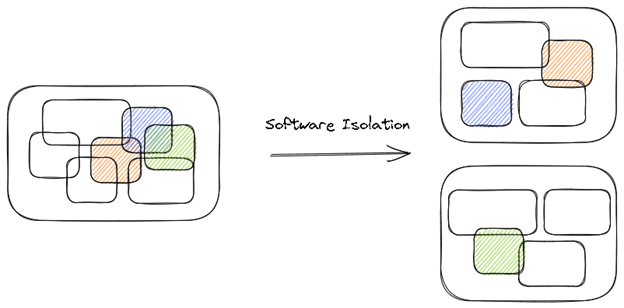
- Isolating outdated, undesirable, or suboptimal code
- As software grows, frameworks, licensed libraries, and other technologies are introduced. These external dependencies may go out of date, have security vulnerabilities, or become too expensive for license renewal. Depending on the architecture type or how long the software has been in use, these technologies can be heavily ingrained (i.e., tangled). Software isolation is the first step to extract these capabilities. Developers isolate the undesired capability into its own library or service so that they can later replace it with a better option. Having the capability in a single location makes this job easier and is a common first step in the process.

- Isolating code for reuse
- A common technique to increase software quality, reduce software bugs, and decrease development times is to reuse already developed capabilities. Think of reusing the core logistics tracking software for a distribution network or the navigation software for an aircraft. These are complex capabilities that have been previously deployed and proven in use. Software isolation can be used to extract these capabilities for reuse. When these capabilities are reused, organizations leverage the time and effort that has already been put into developing them. Not only do they benefit from previous development and test efforts, but reuse means these capabilities already meet existing domain-specific requirements, assumptions, and organizational goals, and are production ready.
- Isolating code to enable independent team development
- Software must evolve as organizations grow. In most cases, organizations begin their journey with a simple software application that eventually must support this growth. Usually, more developers are brought into the organization to help. However, the initial software architecture must change to support this increase in developers working together concurrently (and often in geographically distributed areas). Software isolation can be used to split the application into independent pieces of functionality, each maintained by a different team. These can be reused but also independently maintained and released, enabling better utilization of development resources.
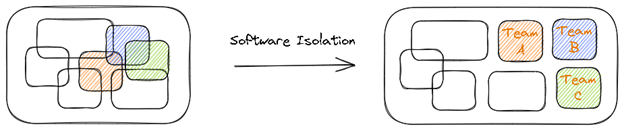
Why Is Software Isolation Challenging?
Software isolation requires teams to identify, make, and verify the necessary code changes. The first change is a problem that relies on team expertise, and the last benefits from the use of test automation. However, making code changes still represents a huge effort for developers. For example, they need to figure out which classes are part of the capability being isolated and, beyond that, the dependencies these classes have on other parts of the code.
Developers must also determine which operations to apply when isolating the capability. For example, should they move a whole class or just a method or a field? Should they consider pulling up methods to a base class and then move the base class? Or perhaps a more sensible operation is to move just an interface definition. Developers must make hundreds, if not thousands, of these decisions in a large-scale refactoring.
To make things worse, there is relatively little assistance from tools in this area. Developers do all this work by hand, relying on the “red squiggly lines” from their integrated development environments or on compiler errors directly, constantly recompiling the code to try to identify which dependency they need to resolve next. On a large code base, this effort can be overwhelming to even the most seasoned developers.
Developers should not have to dread a refactoring exercise. Equally important, organizations should be able to engage in large-scale refactoring activities without the fear of refactoring work derailing their efforts to deliver new features. The challenge with software isolation is not limited to technical decisions alone: the organization’s strategy, needs, resources, and deadlines must also be considered. However, the process of making code changes is still huge and unavoidable for large projects. There is a clear need for better, large-scale refactoring tools that can help organizations to quickly deliver new capabilities or take advantage of new technologies.
Additional Resources
Learn more about the SEI’s work in software isolation and large-scale refactoring: Untangling the Knot: Enabling Rapid Software Evolution.
This collection ”Untangling the Knot” contains artifacts from several projects that apply artificial intelligence techniques to automate labor-intensive engineering activities and make refactoring recommendations: https://resources.sei.cmu.edu/library/asset-view.cfm?assetID=742903.
Written By

More In Software Architecture
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed