A Public Repository of Data for Static-Analysis Classification Research

PUBLISHED IN
Secure DevelopmentStatic analysis (SA) tools are a widely used and routine part of testing by DoD and commercial organizations. Validating and repairing defects discovered by SA tools can require more human effort from auditors and coders than organizations have available. Since 2016, researchers in the SEI CERT Division have been developing a method to automatically classify and prioritize alerts (warnings) and meta-alerts (alerts about code flaws or conditions) to help auditors and coders address large volumes of information with less effort. The purpose of our research has been to enable practical automated classification, so that all meta-alerts can be addressed.
Note: For an explanation of our use of the terms alert, alert condition, and meta-alert, see the sidebar, A Note About Terminology for Alerts.
To date, research into the classification of meta-alerts has been constrained by the absence of a complete and reliable dataset of meta-alert data. This blog post describes a new repository of labeled data that CERT is making publicly available for many code-flaw conditions. Researchers can use this dataset along with the associated code and tool output to monitor and test the performance of their automated classification of meta-alerts.
In addition to labeled data, researchers need associated data that can be used as classifier features. Features are types of data that are analyzed by the mathematical algorithms for the classifiers. They include data gathered by code-metrics tools and general SA tools about the program, file, function, and other categories relevant to each alert. These features help researchers develop more accurate classifiers.
In developing this public repository of data for meta-alert classification research, our goal has been to help the research field as a whole—other researchers as well as ourselves. Researchers in the field need such data for many different code languages, static analysis (and other) tools, and types of code projects, and from a varied set of development organizations. Classifiers are generally better if the data used to develop them (and active-learning /adaptive heuristics used to update them) are similar to the coding-project type, development organization, coding language, and tools for the codebase whose static analysis meta-alerts are being adjudicated.
Background: Using Automation to Prioritize Alerts from Static Analysis Tools
We encountered the problem of insufficient data in our initial classification research, which we began in 2016. We did not have enough labeled data to develop precise classifiers with high recall for many code-flaw conditions, or for similar code. Moreover, the data that we did have was not always of reliably high quality. We addressed this issue of classifier accuracy by using multiple static analysis tools as features, thereby improving the accuracy of classifiers.
We began this work in 2017, motivated in part by the realization that there was insufficient data of dubious quality for accurate classifiers for some conditions, such as Common Weakness Enumerations (CWEs) and CERT coding rules. We developed auditing rules and an auditing lexicon and used test suites in a novel way to produce labeled data for classifier development. The SEI developed the Source Code Analysis Integrated Framework Environment (SCAIFE) application programming interface (API) in 2017. SCAIFE defines an architecture for classifying and prioritizing static analysis meta-alerts using automatically labeled and manually adjudicated data that accurately classifies most data as expected true positive (e-TP), expected false positive (e-FP), or indeterminate (I). By the end of 2018, we had approximately 38,000 new labeled (True/False) alerts from eight SA tools on the Juliet test suite, an improvement over the 7,000 alerts from CERT audit archives over the previous 10 years.
This smaller number of labeled alerts was not enough labeled data to create precise classifiers for most of the CERT coding standards. Our data from more than 10 years of CERT audits had too little (or no) labeled data to create precise classifiers for most of the CERT coding rules. The result of the 2018 work has been high precision for more conditions. Initial 2018 results from an analysis of the Juliet test suite are shown in Figure 1.
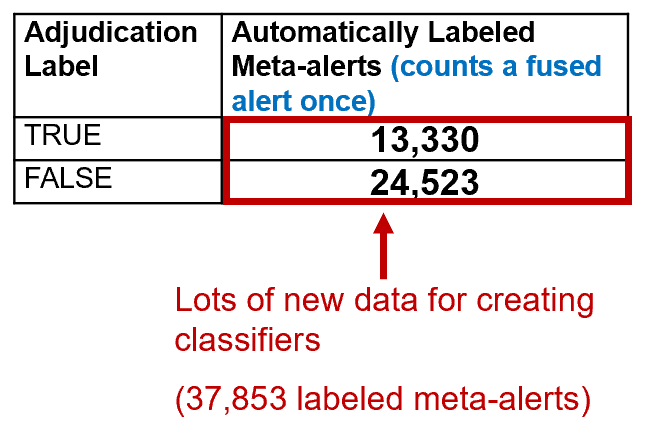
Figure 1 provides initial metrics that show that the availability of the additional data resulted in significant savings. A manual audit of 37,853 meta-alerts from non-test-suite programs would take an unrealistic minimum of 1,230 hours (117 seconds per meta-alert audit according to research by Ayewah and Pugh), and the first 37,853 alert audits would not cover many conditions and sub-conditions covered by the Juliet test suite. Both True and False labels are needed to develop precise classifiers for the conditions. Realistically, it would take an enormous amount of manual auditing time (far more than 1,230 hours) to develop that much labeled data using natural (not test-suite) code and manual adjudications, to generate labeled data for that many conditions, with both true and false labels. More data will be available as we use more tools and test suites.
In 2018-2019, we turned our attention to getting more organizations to use automated meta-alert classifier technology. Adoption had been constrained because of the expense and the dearth of data and experts in the field. We developed an extensible architecture with a novel method for generating test-suite data, enabling wider use of classifiers with an extensible architecture, an application programming interface (API), software to instantiate the architecture, and adaptive-heuristic research.
Rapid Classifiers (RC) Data
On 4/2/2020, we first published the Open Dataset RC_Data for Classifier Research to the SEI CERT Secure Coding webpage, with v2 published on 4/27. Ebonie McNeil, Matthew Sisk, and I developed this dataset. It contains structured data that others can use to test algorithms and tools that we developed, and it supports external research and collaborations on automated classification of static analysis alerts. This data is now publicly available for download. One of our DoD collaborators and also researchers from the University of Virginia—Tim Sherburne, Peter A. Beling, Barry M. Horowitz, and Stephen Adams, Department of Engineering Systems and Environment—have worked with the data already in their research on classifiers.
“RC” stands for “rapid classifiers,” for the series of projects (that I’ve led) intended to enable rapid use of automated classification by
- quickly getting labeled data from test suites
- enabling sharing of previously sensitive data sanitization of audit archives and thus enabling more-quickly growing manually-audited data archives
- developing a modular architecture with API definitions to enable existing systems and tools to start using automated classification technology by overcoming cost and expertise barriers.
The RC_Data file can be downloaded and then reconstituted into a MongoDB database. The database contains data for two test suites: the Juliet Java Test Suite and for the Juliet C/C++ Test Suite. The Juliet test suites are open source, created by the National Security Agency (NSA) Center for Assured Software (CAS) and hosted by the National Institute of Standards and Technology (NIST) Software Assurance Reference Dataset (SARD) website.
These test suites were created to test the quality of flaw-finding static analysis (FFSA) tools. We use them in a different way than the purpose for which they were originally designed to help generate data for creating and testing automated classification tools. The RC_Data dataset includes structured data about the FFSA alerts from open-source tools, information about Common Weakness Enumeration (CWE) conditions those are mapped to, verdicts (true/false/unknown) determined using test-suite meta-data, and code metrics from open-source code-metrics tools.
The RC_Data dataset is composed only of open-source data: open-source flaw-finding and code-metrics static analysis tools, open-source codebases, open-source mappings between checkers and taxonomy IDs, and open-source test-suite manifests. Proprietary tool vendors who develop the most-used proprietary tools do not allow publication of alerts from their tools, and sometimes do not allow publication of mappings from their tool checkers to external taxonomy conditions (e.g., CWE or CERT coding rules). We have run more tools on the Juliet codebases and others, but can publicly share only data that is open source in RC_Data.
Potential collaborators should contact us if they are interested in contributing to the RC_Data dataset, if they have (or could) generate open-source tool alerts, and optionally also code metrics, for an open-source codebase along with adjudications true or false. Adjudications are required; they can be performed manually or can simply consist of a SARD-style XML manifest for a test suite.
Self-Training Resources for Auditing Meta-Alerts
To make it easier for researchers to contribute—whether publicly or for their internal use only—to the data in the RC_Data dataset, we have identified some self-training resources. To date, we have not aggregated and provided these resources publicly but have provided them on request to a number of collaborators, who have found them to be useful. Here is the list of resources:
- Static Analysis Alert Audits: Lexicon & Rules, by D. Svoboda, L. Flynn, and W. Snavely, paper for 2016 IEEE Secure Development Conference (SecDev)
- Hands-On Tutorial: Auditing Static Analysis Alerts Using a Lexicon and Rules, presentation by L. Flynn, D. Svoboda, and W. Snavely
- One-hour webinar about hands-on use of Source Code Analysis Laboratory (SCALe), “Improve Your Static Analysis Audits Using CERT SCALe’s New Features,” by L. Flynn. (The SCAIFE System includes the SCALe tool as a separable part of SCAIFE.) Video Presentation slides (PDF)
- “Rapid Construction of Accurate Automatic Alert Handling System,” presentation by L. Flynn and E. McNeil, Nov. 2019. Video Presentation slides (PDF)
The quality of data will increase if the team using the data studies definitions of the code-flaw types (i.e., conditions”) for which they will inspect static analysis meta-alerts, as defined in a formal code-flaw taxonomy. For my research, the taxonomies currently of the most interest are
- MITRE CWE
- CERT coding rules for C
- CERT coding rules for Java
- CERT coding rules for C++
The SCALe GitHub publication includes a SCAIFE/SCALe HTML manual with extensive information about how to use the SCAIFE and SCALe systems at https://github.com/cmu-sei/SCALe (scaife-scale branch).
Looking Ahead to Open-Source Data for More Codebases
In the future, we will add more data to augmented versions of this dataset. They will include open-source data from more codebases and data from more tools, and we will add more features to the dataset.
We are currently working with University of Virginia researchers on an update to the initial RC_Data, to which they will add their own data on dynamic analyses and regression testing. I have been working with them to add fields and collections—a grouping of MongoDB documents that is the equivalent of a relational database management system (RDBMS) table, similar conceptually to a Structured Query Language (SQL) database table—to hold those fields. I am also working with them to update the database format that they will arrange their data into to use project, package, and additional structures that my projects use internally in our SCAIFE DataHub databases.
In our ongoing research projects at the SEI, we have greatly updated the SCAIFE DataHub database format over the past three years, but the RC_Data database v1 format is a much older format used by our old code that evolved into SCAIFE on a separate branch. We used the old branch to produce the initial RC_Data, but the newer DataHub database format has more fields and collections that will be useful for research on classifiers, even before adding the new fields for the University of Virginia data. We expect to continue to enhance the RC_Data database format as we work with additional collaborators who generate additional features for data they contribute to RC_Data, and those new features will need to be included in the RC_Data database.
A Note About Terminology for Alerts
In our most recent work, we have begun to differentiate three concepts:
- Alert: A warning from an FFSA tool, specific to (1) a particular code location (line number and filepath); (2) a checker ID (a type of code flaw that the tool looks for, where the combination of all checker IDs in a tool define the tool’s internal taxonomy for code flaws); (3) a unique primary warning message; and (4) a unique set of secondary warning messages if there are any. Some tools provide secondary warning messages that enable users to trace control or data flow in the code that leads to the primary alert.
- alertCondition: A condition is a constraint or property of validity with which code should comply. FFSA tools detect whether code violates conditions. External taxonomies of code flaws, such as MITRE CWE, Motor Industry Software Reliability Association (MISRA) rules, and SEI CERT Secure Coding Rules are defined external to a single static analysis tool.) An alertCondition is a single alert combined with information about only one of the externally defined code-flaw taxonomy conditions to which the SA tool’s checker maps. An example of an externally defined taxonomy condition: CWE-190 is a condition from the CWE taxonomy, and CWEs are defined externally to any SA tool. In our SEI SCALe tool (research versions 3.0 and newer, and on GitHub all publications of the scaife-scale branch of SCALe), in Unfused view, each row of the alertCondition List shows an alertCondition, and the total count shown is the count of alertConditions.
- Meta-alert: A construct that alertConditions map to, which all alertConditions that share the same line, filepath, and condition. Our classifiers make a prediction for a meta-alert, and an analyst makes a manual adjudication of a meta-alert. The meta-alert construct is used in SEI SCALe (research versions 3.0 and newer) to link alerts that are mapped to the same (1) code location (line number and filepath); and (2) code-flaw condition (specifically, a condition from a taxonomy external to any particular static analysis tool). For example, CWE-190 is a condition from the CWE taxonomy. In SCALe versions 3.0 and newer, determinations (e.g., True and False) are made at a meta-alert level. Note that each alert in SCALe versions 3.0 and newer has a meta-alert, even when only one alert maps to that code location and code-flaw condition. In Fused view, the total count shown is the count of meta-alerts.
Additional Resources
Read the SEI blog post, Test Suites as a Source of Training Data for Static Analysis Alert Classifiers.
Read the SEI blog post, SCALe v. 3: Automated Classification and Advanced Prioritization of Static Analysis Alerts.
Read the SEI blog post, An Application Programming Interface for Classifying and Prioritizing Static Analysis Alerts.
Read the SEI blog post, Prioritizing Security Alerts: A DoD Case Study.
Read the SEI blog post, Prioritizing Alerts from Static Analysis to Find and Fix Code Flaws.
Read the technical manual (and we hope you will follow the steps to test and instantiate SCAIFE code!):
How to Instantiate SCAIFE API Calls: Using SEI SCAIFE Code, the SCAIFE API, Swagger-Editor, and Developing Your Tool with Auto-Generated Code.
Examine the YAML specification of the latest published SCAIFE API version on GitHub.
Download the scaife-scale branch of SCALe: https://github.com/cmu-sei/SCALe/tree/scaife-scale.
Read the SEI white paper, SCAIFE API Definition Beta Version 0.0.2 for Developers.
Read the SEI technical report, Integration of Automated Static Analysis Alert Classification and Prioritization with Auditing Tools: Special Focus on SCALe.
Review the 2019 SEI presentation, Rapid Construction of Accurate Automatic Alert Handling System.
Read other SEI blog posts about SCALe.
Read other SEI blog posts about static analysis alert classification and prioritization.
Read the SEI technical report, Integration of Automated Static Analysis Alert Classification and Prioritization with Auditing Tools: Special Focus on SCALe.
Watch the SEI webinar, Improve Your Static Analysis Audits Using CERT SCALe’s New Features.
Read the SEI blog post, Static Analysis Alert Test Suites as a Source of Training Data for Alert Classifiers.
Read the Software QUAlities and their Dependencies (SQUADE, ICSE 2018 workshop) paper, Prioritizing Alerts from Multiple Static Analysis Tools, Using Classification Models.
View the presentation, Challenges and Progress: Automating Static Analysis Alert Handling with Machine Learning.
View the presentation (PowerPoint), Hands-On Tutorial: Auditing Static Analysis Alerts Using a Lexicon and Rules.
Watch the video, SEI Cyber Minute: Code Flaw Alert Classification.
View the presentation, Rapid Expansion of Classification Models to Prioritize Static Analysis Alerts for C.
Look at the SEI webpage focused on our research on static analysis alert automated classification and prioritization.
Written By

More By The Author
Release of SCAIFE System Version 2.0.0 Provides Support for Continuous-Integration (CI) Systems
• By Lori Flynn
Release of SCAIFE System Version 1.0.0 Provides Full GUI-Based Static-Analysis Adjudication System with Meta-Alert Classification
• By Lori Flynn
PUBLISHED IN
Secure DevelopmentGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed