Test Suites as a Source of Training Data for Static Analysis Alert Classifiers


PUBLISHED IN
Secure DevelopmentThis post was also co-written Will Snavely.
Numerous tools exists to help detect flaws in code. Some of these are called flaw-finding static analysis (FFSA) tools because they identify flaws by analyzing code without running it. Typical output of an FFSA tool includes a list of alerts for specific lines of code with suspected flaws. This blog post presents our initial work on applying static analysis test suites in a novel way by automatically generating a large amount of labeled data for a wide variety of code flaws to jump-start static analysis alert classifiers (SAACs). SAACs are designed to automatically estimate the likelihood that any given alert indicates a genuine flaw.
A common problem with FFSA tools is when they issue a large number of false positive alerts, or alerts that do not indicate a genuine code flaw. Manually sorting through a large number of false positive alerts in search of a few crucial code flaws is tedious, error-prone, and expensive. These problems motivated us to work on SAACs.
Obtaining relevant training data is the first ingredient to develop any machine learning-based classifier. Ideal data in this case would include a large number of FFSA alerts with expert labels specifying whether each alert is a false positive. Unfortunately, publicly-available data of this type is scarce. An organization that wishes to use a SAAC to maintain its code base must apply internal expertise to label alerts, which increases the start-up cost of using a SAAC and ultimately reduces the value of a SAAC for smaller organizations that do not have much internal data.
A key goal of our work is to identify publicly available data that we can use to pre-train (or "jump-start") an SAAC. An organization may find a pre-trained SAAC useful for identifying false positive alerts even before it begins to generate its own expert alert labels. The SAAC can later be updated with the new expert labels to become increasingly accurate. Similarly, an organization may find that its pre-existing SAAC system can be improved by adding labeled data covering a wider variety of code flaws and code conditions.
This blog post describes how we derive SAAC training data from test suites consisting of repositories of "benchmark" programs that are purpose-built to test static analysis tools. These test suites are abundant, e.g., NIST provides over 600,000 cost-free, open-source test suite programs in its Software Assurance Reference Dataset, along with metadata identifying each test's known flaw conditions and the flaw locations.
Our use of test suites as a source of training data for SAACs is novel since test suites are normally used to test and compare vulnerability analysis tools or test system defenses. Our resulting classifier attains high rates of precision and recall on hold-out test sets within a selected test suite. Future work will assess the performance of our SAAC on non-test suite code.
From Test Suites to Classifiers: Terminology and Overview
The figure below outlines our software system for developing SAAC-based training data harvested from test suites. At the top level, our SAAC development process has two steps. The first step is to prepare labeled data (or "ground truth"). The second step is to train a classifier and evaluate its performance. Below we present our classifier accuracy results and give some insights on how we built classifiers, though our focus is on the data preparation.
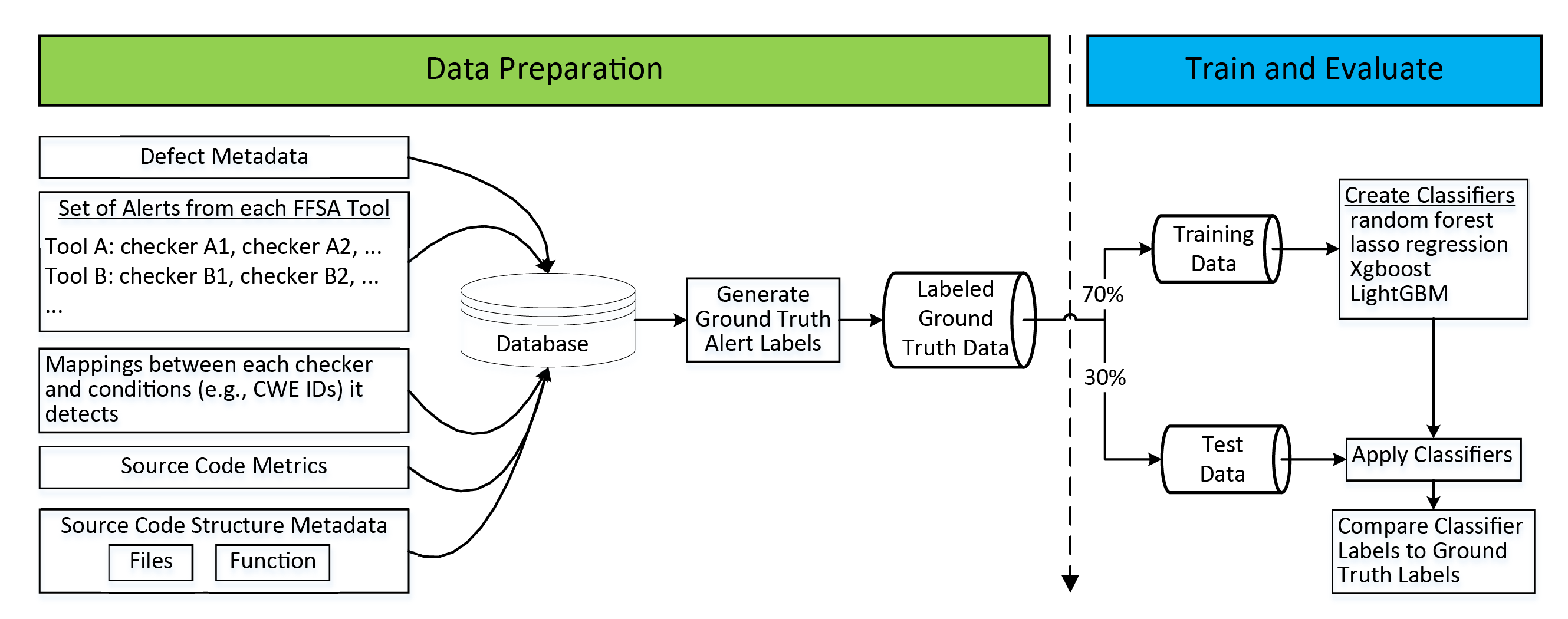
Data preparation begins with identifying and obtaining one or more test suites that include metadata specifying the locations of code flaws. There are many different types of code flaws. Our system uses the Common Weakness Enumeration (CWE), which establishes a unique CWE-ID for a large variety of flaws (there are 706 CWE-IDs as of March 26, 2018).
To support our system, a test suite's metadata needs to specify both (a) the presence of specific code flaws (i.e., specific CWE-IDs) on specific lines of code and (b) the absence of specific code flaws within specific sections of code.
Having obtained test suites, we run multiple FFSA tools (indicated as Tool A, Tool B, etc. in the figure above) on all of the source code to generate a large volume of alerts. FFSA tools use multiple sub-tools, or checkers, indexed by checker-IDs. Each checker can typically detect flaws corresponding to just one or a few CWE-IDs.
We align alerts with test suite metadata to assign a label, or determination of whether an alert is a false positive, for as many alerts as possible. Specifically, mappings between checkers and the CWE-IDs that they can detect are available for some FFSA tools. An alert that was generated by a mapped checker therefore has a known "target CWE-ID." Wherever the test suite metadata specifies the presence or absence of a flaw corresponding to an alert's target CWE-ID, the alert inherits its label from the test suite metadata.
Finally, we identify all groups of alerts that (a) co-occur on a single line of code and (b) share the same target CWE-ID. These groups are reduced to a single fused alert record. Alert fusion simplifies the data and avoids double-counting labels; all alerts in a fused group inherited their label from the same piece of test suite metadata.
Case Study: The Juliet Test Suite
We developed our system around the Juliet C/C++ v1.2 test suite, which provides test programs for flaws of multiple subtypes of 118 of the most common CWE-IDs. For example, flaw subtypes for a CWE-ID could include separate instantiations of the flaw using an integer or a string. Additional test programs involving variants of control, data, and/or type flow exist for many flaw subtypes. For instance, one program may locate a flaw completely within a function, while another program may exhibit the same flaw hidden in a control flow that involves data pointers and multiple function calls.
We selected eight FFSA tools including popular commercial tools and open-source tools (terms of use agreements prevent us from disclosing the tool names). We ran each tool on the 61,387 tests in the Juliet test suite, generating on the order of a million alerts. Our software system parsed the alerts and uploaded them to a database, collating each alert with its checker-ID and the file path and line number of the possible defect.
We identified publicly available mappings to CWE-IDs for many of the checker-IDs and loaded these into the database. Finally, we identified labels for many of the alerts, performed alert fusion, and generated several hundred features to guide the classifier. We describe these steps in detail below.
Alert Labels from Juliet Metadata
The Juliet test suite contains two types of metadata that are relevant for determining the validity of alerts:
- a manifest file: This XML file provides precise flaw information, including line number, CWE-ID, and file path.
- function names: Documentation for the test suite says that if the function name includes the string GOOD then the particular CWE-ID does not occur in it, but if it includes the string BAD then the CWE-ID does occur in the function. We gathered information about file path and line numbers covered by each function name that contains GOOD or BAD, as well as the CWE indicated (usually by filename).
Note that both the manifest file and the function names provide only CWE-ID-specific flaw information. In general, a line of code marked BAD for one code flaw type could be flawless with respect to all other code flaw types. We can therefore use the metadata flaw information to determine the validity of an alert only when we can establish that the alert's checker-ID is for a flaw of the same type as a flaw referenced in the metadata.
For alerts from the FFSA tools with publicly available mappings between checker-IDs and CWE-IDs, we identified the CWE-ID for each alert. We then fused alerts grouped by line and CWE-ID, producing a set of fused alerts with known CWE-ID designations. Finally, we determined labels (i.e., classifier ground truth labels) for each fused alert as follows:
- If the manifest includes a record of a flaw for the same file path, line number, and CWE-ID as the alert, set label = True, which indicates the alert is a true positive (TP).
- If the defect alert matches any line within a function name with GOOD and the alert's CWE-ID matches the CWE-ID associated with the function, set label = False, which indicates the alert is a false positive (FP).
Applying the above procedure resulted in 13,330 TP fused alerts, 24,523 FP fused alerts, and 17,441 fused alerts with no determination. The procedure defined above conservatively refrains from assigning a label for an alert when (a) the alert falls within a function labeled BAD, but (b) the metadata flaw line number does not match the line number of the alert.
Automatically generating this volume of alert labels is potentially a nontrivial cost savings. Pugh and Ayewah found a mean time of 117 seconds per SA alert review, from analyzing data from 282 Google engineers that made more than 10,000 manual SA alert determinations. Manually generating our 37,853 alert labels at this rate might have taken 1,230 hours. Manual auditing and natural code, however, would likely not cover many of the conditions in the Juliet test suite since many conditions rarely exist in natural code. (By 'natural code', we mean code developed for purposes other than being a test suite. Code developed solely for test suites tends to have different characteristics, for example see discussion of the Juliet test suite in the Future Work section below.) Even if SA tools were run on a large number of natural codebases (which would take a lot of time and computation) and alerts were found for many conditions, it might take many manual audits before both true and false determinations could be made for each condition. Realistically, it would take an enormous amount of manual auditing time (and money to pay for it), to develop that much data.
Features for the Classifiers
In machine learning terminology, a feature is a number associated with each data point. Classifiers use features to make predictions. For instance, a classifier that predicts whether a person is a full-time student might take into account the person's age.
We generated hundreds of features to help train the classifiers that we tested. The majority of the features come from computing code metrics on the test suite:
- Lizard--A simple code complexity analyzer that ignores the C/C++ header files or Java imports and supports most of the popular languages
- C Code Source Metrics (CCSM)--tools to gather simple metrics from C code
- A proprietary tool (whose name is omitted here to preserve anonymity)
The resulting metrics include counts of significant lines of code, complexity, and cohesion. All metrics are functions of describe code functions or code files.
Lizard provided the fewest metrics, and CCSM provided the most. Our database correlates each alert with applicable code metrics. Specifically, each alert on a line in a function inherits the metrics computed for that function, as well as the metrics for the file containing that function.
The primary reason we ran multiple FFSA tools on the Juliet test suite was to obtain a large number of alerts, but a secondary benefit is to produce additional features. We included an indicator for whether each FFSA tool issued one of the alerts in each fused alert. We also defined two new code metrics: the number of alerts per file and the number of alerts per function.
Other features include one-hot encodings of the CWE-ID and the CWE-ID subtypes indicated by each FFSA tool's checker-ID. Including these features allows the classifier to learn from base rates of FFSA tool precision (percent correct or true positive) for each subtypes of the code flaw indicated by each CWE-ID.
Classifier Development and Testing
The classifier task is to determine whether a fused alert is a True Positive (TP) or a False Positive (FP) on the basis of the features associated with each alert. We used a standard experimental design to measure the accuracy of each classifier by splitting the labeled alert archives into a training set and a test set. We trained each classifier on the training set and separately tested each classifier on the test set.
We started by defining our single test set, which included 11,392 fused alerts, or about 30 percent of the fused alerts. We then defined the training set to include all the remaining fused alerts. We used the R statistical programming language to run four different classifiers: LightGBM, XGBoost, the H2O.ai implementation of random forests, and the glmnet implementation of lasso-regularized logistic regression. For each classifier, a prediction for a fused alert is a number between 0 and 1, which represents an estimated probability that the fused alert has label = True.
Our primary metric for classifier performance is the area under the receiver operating characteristic curve (AUROC). The AUROC is useful for comparing the overall performance of classifiers when the classifier output is probabilistic. In addition to the AUROC, we compute the precision, recall, and accuracy since these standard metrics are relatively easy to interpret. The precision is the fraction of predicted TP alerts that were indeed TP, the recall is the fraction of TP alerts that were successfully predicted as TP, and accuracy is the number of correct predictions made divided by the total number of predictions made. Note that precision is meaningless when the classifier does not classify any issues as TP, so precision values for certain subsets of the test set are missing. Similarly, recall is meaningless when the labeled alerts contain no TP alerts, as there is nothing to recall.
The following test results summarize performance of the classifiers on the test set after training on the training data. Table 2 summarizes the average performance of the different classifiers over the entire test set. Table 3 summarizes the performance of LightGBM, our best classifier, on all CWE-IDs for which at least one test data point was available. Note that that test count is the number of fused alerts available for testing for each CWE-ID, and TP rate is the fraction of the testing alerts that were TP.
| Classifier | Accuracy | Precision | Recall | AUROC |
|---|---|---|---|---|
| rf | 0.938 | 0.893 | 0.875 | 0.991 |
| lightgbm | 0.942 | 0.902 | 0.882 | 0.992 |
| xgboost | 0.932 | 0.941 | 0.798 | 0.987 |
| lasso | 0.925 | 0.886 | 0.831 | 0.985 |
| CWE-ID | Test Count | TP Rate | PrecisionR | Recall | Accuracy |
|---|---|---|---|---|---|
| 457 | 2010 | 0.06 | 0.99 | 1 | 1 |
| 78 | 1069 | 0.43 | 0.81 | 0.76 | 0.82 |
| 758 | 967 | 0 | 1 | 1 | 1 |
| 195 | 956 | 0.14 | 0.63 | 0.53 | 0.89 |
| 197 | 770 | 0.43 | 0.79 | 0.83 | 0.83 |
| 194 | 683 | 0.35 | 0.92 | 0.74 | 0.89 |
| 190 | 522 | 0.16 | 1 | 1 | 1 |
| 134 | 417 | 0.42 | 0.88 | 0.83 | 0.89 |
| 191 | 402 | 0.28 | 0.73 | 0.87 | 0.88 |
| 404 | 341 | 0.22 | 0.85 | 0.93 | 0.95 |
| 762 | 294 | 1 | 1 | 1 | 1 |
| 680 | 291 | 0 | 1 | ||
| 401 | 266 | 0 | 1 | ||
| 369 | 265 | 0.46 | 0.97 | 0.96 | 0.97 |
| 606 | 262 | 0.31 | 1 | 1 | 1 |
| 590 | 232 | 1 | 1 | 1 | 1 |
| 665 | 204 | 0 | 0 | 0.99 | |
| 252 | 189 | 0.73 | 1 | 1 | 1 |
| 681 | 169 | 0.12 | 1 | 1 | 1 |
| 761 | 169 | 0.5 | 1 | 1 | 1 |
| 843 | 87 | 0.28 | 0.94 | 0.67 | 0.9 |
| 775 | 85 | 0 | 1 | ||
| 563 | 73 | 0.16 | 1 | 1 | 1 |
| 377 | 72 | 0 | 1 | ||
| 121 | 70 | 0.83 | 0.96 | 0.86 | 0.86 |
| 476 | 57 | 0.32 | 0.95 | 1 | 0.98 |
| 122 | 53 | 0.81 | 0.88 | 0.98 | 0.87 |
| 196 | 44 | 0.16 | 1 | 1 | 1 |
| 426 | 44 | 0.43 | 0.73 | 0.84 | 0.8 |
| 690 | 42 | 1 | 1 | 1 | 1 |
| 469 | 39 | 0.36 | 1 | 1 | 1 |
| 468 | 33 | 0.21 | 0.88 | 1 | 0.97 |
| 398 | 30 | 0.23 | 1 | 1 | 1 |
| 688 | 25 | 0 | 1 | ||
| 328 | 21 | 1 | 1 | 1 | 1 |
| 467 | 21 | 1 | 1 | 1 | 1 |
| 415 | 20 | 0.45 | 1 | 1 | 1 |
| 587 | 20 | 0.35 | 1 | 1 | 1 |
| 188 | 14 | 1 | 1 | 1 | 1 |
| 367 | 14 | 1 | 1 | 1 | 1 |
| 416 | 9 | 1 | 1 | 1 | 1 |
| 253 | 7 | 1 | 1 | 1 | 1 |
| 338 | 7 | 1 | 1 | 1 | 1 |
| 478 | 7 | 1 | 1 | 1 | 1 |
| 484 | 7 | 1 | 1 | 1 | 1 |
| 127 | 3 | 0.67 | 1 | 0.5 | 0.67 |
| 126 | 2 | 0.5 | 0 | 0.5 | |
| 570 | 2 | 1 | 1 | 1 | 1 |
| 571 | 2 | 1 | 1 | 1 | 1 |
| 480 | 1 | 0 | 1 | ||
| 483 | 1 | 0 | 1 | ||
| 562 | 1 | 1 | 0 | 0 | |
| 835 | 1 | 1 | 1 | 1 | 1 |
We are currently writing a conference paper to more thoroughly document this work.
Summary and Future Work
We developed a novel method that uses test suites to automatically generate a large quantity of labeled data for FFSA alert classifier development. We implemented this method in a software system and generated a large quantity of labeled data for many different conditions using the Juliet test suite. Initial tests of the resulting classifiers on partitioned alerts from the test suite data show high accuracy for a large number of code flaw types.
With incorporation of test suites that cover more conditions (e.g., more CWE-IDs), we expect that the methods demonstrated here would yield successful classifiers for those additional conditions. In general, the method and software system developed can be used with any FFSA and code metrics tools to rapidly develop labeled data archives with standard additions to the system. Incorporating a new tool requires a parser and uploads to the database, while any new FFSA tool requires checker-CWE mappings. The general method can use additional artifact characteristics (source code repository metrics, bug database metrics, and dynamic analysis metrics), but the software system we developed would require extensions.
The Juliet test suite programs are small (generally consisting of 1-3 short files) and are synthetically constructed. Our future work includes adding data from additional test suites, plus testing the classifiers on natural codebases, including widely used publicly available cost-free open-source codebases and non-public proprietary codebases belonging to collaborators.
Additional Resources
View a recent presentation that I gave, Automating Static Analysis Alert Handling with Machine Learning: 2016-2018, to Raytheon's Systems And Software Assurance Technology Interest Group.
Read a paper on alert auditing rules and an auditing lexicon that we developed that is intended to improve classifier accuracy: Static Analysis Alert Audits: Lexicon & Rules.
Read blogposts on our previous alert classifier work:
Presentation (PowerPoint): Hands-On Tutorial: Auditing Static Analysis Alerts Using a Lexicon and Rules
Presentation: Rapid Expansion of Classification Models to Prioritize Static Analysis Alerts for C
Presentation: Prioritizing Alerts from Static Analysis with Classification Models
Our paper "Prioritizing Alerts from Multiple Static Analysis Tools, using Classification Models" will be published in the SQUADE (an ICSE 2018 workshop) proceedings at some time after the workshop date (May 28, 2018).
Written By


More By The Authors
Release of SCAIFE System Version 2.0.0 Provides Support for Continuous-Integration (CI) Systems
• By Lori Flynn
PUBLISHED IN
Secure DevelopmentGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed