SCALe v. 3: Automated Classification and Advanced Prioritization of Static Analysis Alerts


PUBLISHED IN
Secure DevelopmentStatic analysis tools analyze code without executing it, to identify potential flaws in source code. These tools produce a large number of alerts with high false-positive rates that an engineer must painstakingly examine to find legitimate flaws. As described in Lori's first blog post on this topic, we in the SEI's CERT Division have developed the SCALe (Source Code Analysis Laboratory) tool since 2010 as part of our research on new ways to help analysts be more efficient and effective at auditing static analysis alerts.
We develop the SCALe tool with new features to enable research, for instance to gather metrics on the effect of the new features or to enable SCALe audit archives to have higher quality data and develop better automated alert classifiers. In August 2018 we released a version of SCALe (version 2) to the public (open source via Github). This blog post describes new features and capabilities we have added in our ongoing development of SCALe.
Lori Flynn is the principal investigator leading research on static analysis alert classification and advanced alert prioritization from late 2015 through the present, and her research project teams have done almost all the SCALe development during that time. Co-author Ebonie McNeil has been involved with this research since December 2017, and has made significant contributions to the development of SCALe. SCALe developers on Lori's research project teams since late 2015 also including David Svoboda, William Snavely, Derek Leung, Jiyeon Lee, Lucas Bengston, Jennifer Burns, Christine Baek, Baptiste Vauthy, Shirley Zhou, Maria Rodriguez De La Cruz, and Elliot Toy.
The latest release of the SCALe tool is version 3.0, which is currently a non-public research prototype that we share only with collaborators. In this release, we have added many features and fields to provide automated classification and advanced prioritization of static analysis alerts. We describe these enhancements in this post. We also describe plans to connect this enhanced version of SCALe to an architecture that will provide classification and prioritization of alerts via application programming interface (API) calls. The research project team is developing a prototype that instantiates the architecture, and we are working to complete the prototype and integrate it with latest version of SCALe.
SCALe provides a graphical user interface (GUI) front end for auditors to examine alerts from one or more static analysis tools and the associated code, to make determinations about an alert (e.g., mark it as true or false), and export the project audit information to a database or file. The publicly released version of SCALe can be used for auditing software in four languages (C, C++, Java, and Perl) and two code-flaw taxonomies [SEI CERT coding rules and MITRE's Common Weakness Enumeration (CWE)]. To learn more about SCALe, see SCALe: A Tool for Managing Output from Static Analysis Tools.
The two figures below illustrate the evolution of the SCALe tool from version 1.0 (prior to the research project enhancements begun in late 2015) to version 3.0, which is the current working version.
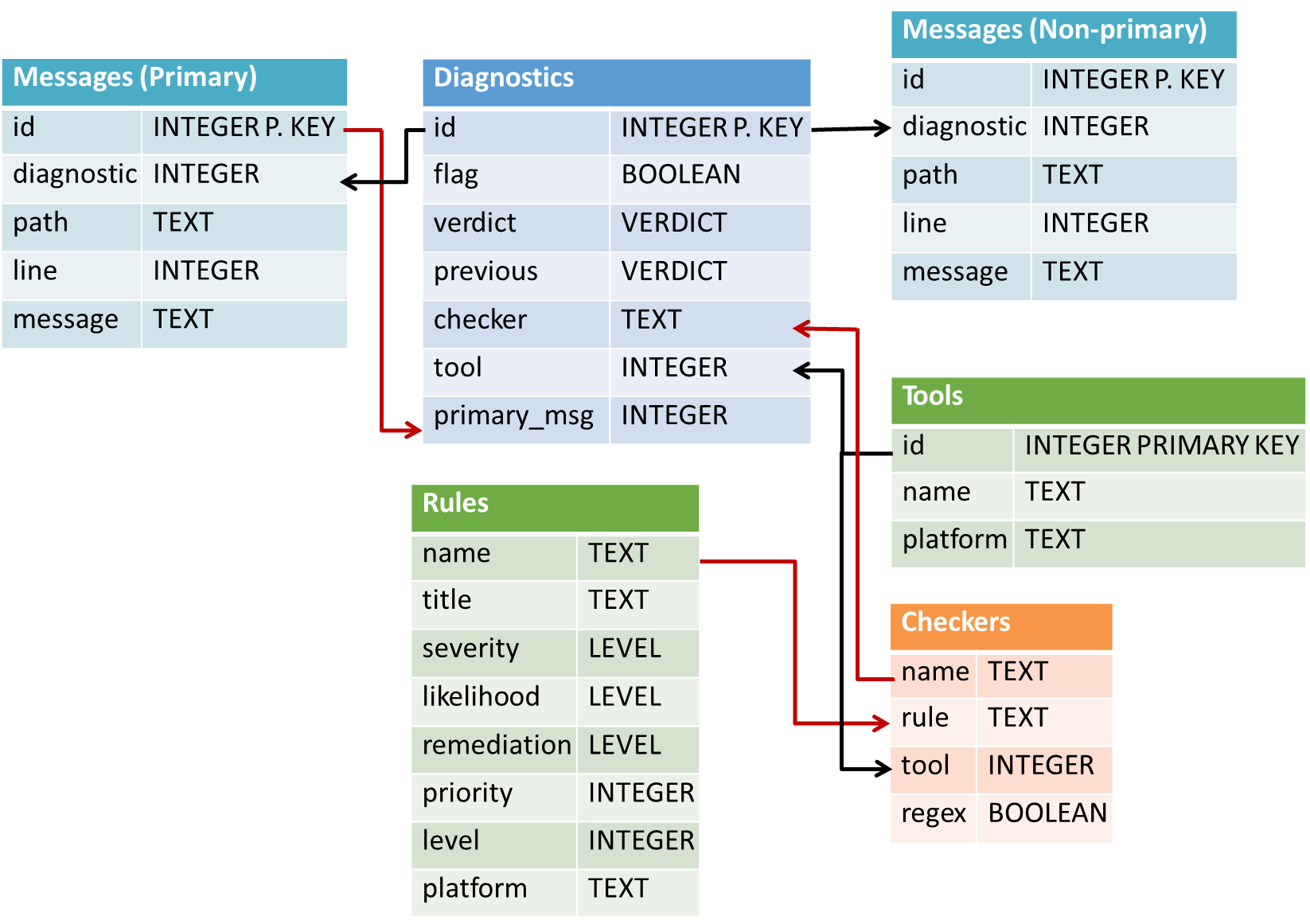
Figure 1: SCALe v1 Exported Database Format
The following modifications to the initial version of the SCALe databases include new features important for prioritization and classification integration:
- Inclusion of the CWE taxonomy, as well as CERT coding rules. This taxonomy enables the use of test suites based on Common Weakness Enumeration (CWE) to automatically generate labeled data for classifiers. (Introduced in SCALe v2.)
- Alert fusion, which reduces the effective number of (alert, condition) tuples to be audited. Tuples on any given line of code get fused into a single unit for auditing purposes. We use a new data structure called a meta-alert, at least one associated with every alert and one for every condition that alert is mapped to. Alert fusion refers to multiple alerts being mapped to a single meta-alert (this happens when they share the same line number, filepath, and mapped condition). A meta-alert can be mapped to a single alert (during the time it maps to only one alert, there is no alert fusion associated with it). (Introduced in SCALe v2.)
- Support for additional software metrics used by classifiers, including use of code-metrics tool output [from tools such as Lizard and C Code Source Metrics (CCSM)] that provide many code features such as metrics on code cohesion and complexity. (Introduced in SCALe v2.)
- New and modified fields in accordance with a conference paper that came out of this research in 2016, Static Analysis Alert Audits: Lexicon & Rules. These fields include improved auditor determinations, new supplemental determinations, and a new notes field. These standardized labels and fields work with the CERT auditing rules to enable precise and consistent audit determinations. They should therefore improve the accuracy of classifiers based on the archive data resulting from the audit. (Introduced in SCALe v2.)
- New tables for classification and prioritization, which record schemes for various types of prioritization and classification, as well as scores for the resulting priority and confidence. The scores will be used in the GUI to order alerts for prioritized auditor work. (Introduced in SCALe v2, modified in SCALe v3.)
- New fields for classification and prioritization. Pre-existing project tables have two new fields, last_used_confidence_scheme and last_used_priority_scheme. These fields enable the auditor to determine how the confidence and priority values were calculated, even if the SCALe project is exported and then re-imported into a different in-stance of SCALe. The project tables also have a new field, current_classifier_scheme, which records the scheme for the most recent type of classifier that was created, which is the scheme that was last used to create a classifier, although the classifier may not yet have been run on alerts that need to be labeled. (Introduced in SCALe v3.)
- New table for user upload fields, which stores custom fields the user can use to prioritize alerts. Custom fields are pre-calculated metrics that users want to include in addition to the fields already present like severity or likelihood. (Introduced in SCALe v3.)
- Determination history, which is a new table that stores the history of determinations for a meta-alert, including primary and supplemental verdicts, notes, flag, and timestamp. This data can be used to develop classifiers that use features such as determination changes. (Introduced in SCALe v2 but later than GitHub version, plus in SCALe v3.)
The database design in Figure 2 shows the new format of an exported SCALe project (in sqlite3 database format).
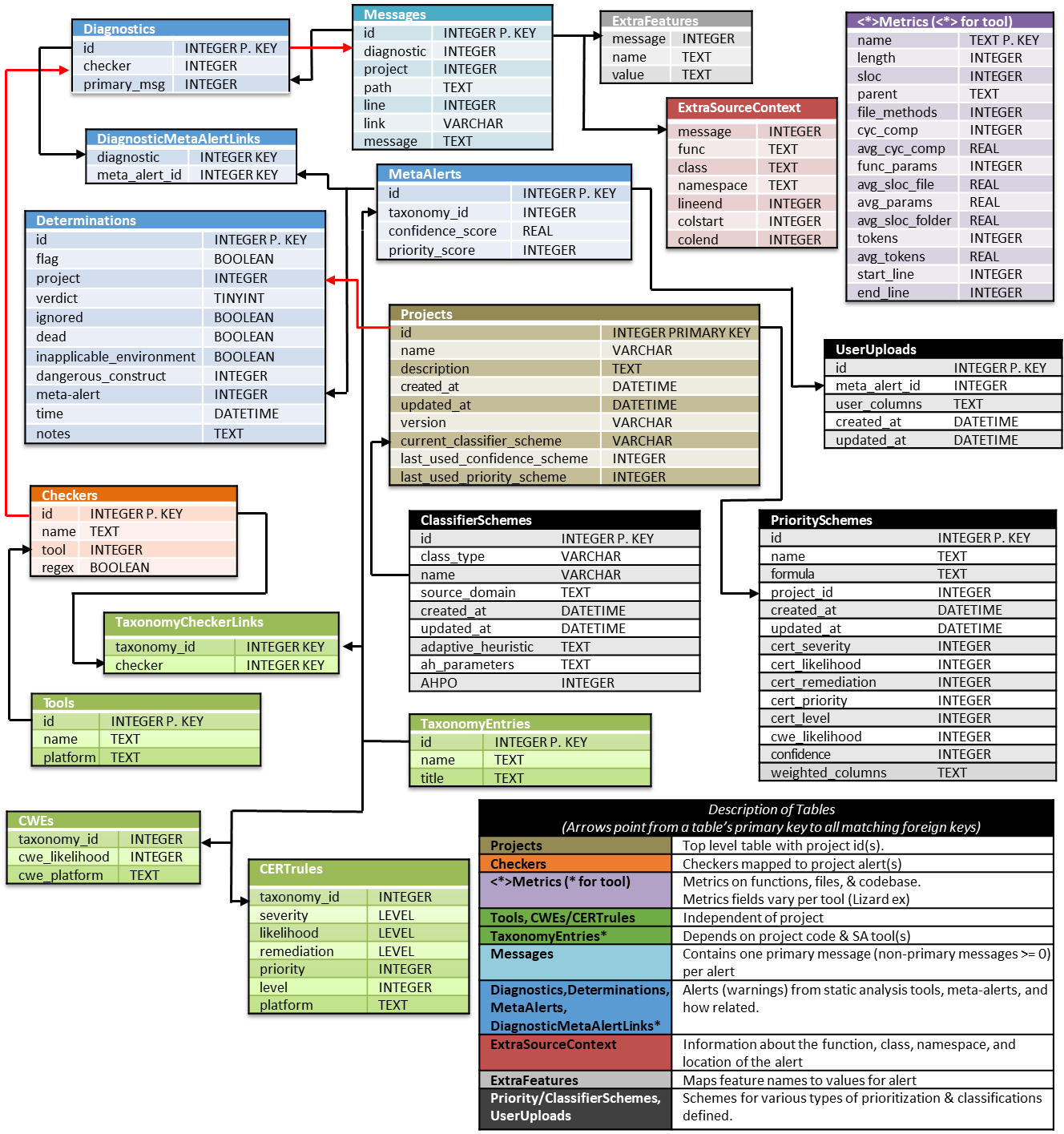
Figure 2: SCALe v 3.0 Exported Database Format
The following sections briefly describe new functionalities added in v 3.0 of SCALe that weren't described in our previous blogpost.
Selection of a Priority Scheme
Prioritization-scheme selection allows users to prioritize static analysis alerts using factors they care about, as shown in the figure below. The formulas can combine classifier confidence and other values (e.g., risk, cost) used by the system.

Figure 3: Save Prioritization Scheme
Ability to Upload Additional Fields
Uploaded fields can currently be used in prioritization formulas, but cannot be viewed in the GUI. Future versions of SCALe will include the fields in the GUI.
The upload-fields option is intended for advanced users who can work with SQL databases and who have or can generate values for new fields (e.g., based on advanced logic using the other alert fields or based on proprietary data). An extended and more user-friendly version of the concept, however, could be added without technical difficulty beyond standard development. This addition would enable less technical users to generate values for new fields using mathematical formulas, advanced logic, and data beyond that provided in the initial SCALe database.
Ability to Select and Run a Classification Scheme
Although classification is not available in the current version of SCALe, we have integrated many features required for classification into it. Interfaces are provided for user testing and feedback.
The user selects one of the three options shown in Figure 4. The interface displays three options: Xgboost, Random Forest, and Logistic Regression.

Figure 4: Selection of a Classifier Scheme
After a classifier type is selected, a popup window appears with the following options:
- Projects available: This section lists available projects for labeled data (meta-alerts with determinations) that could be used to train the classifier. These project names are auto-populated from the current active set of SCALe projects.
- Adaptive heuristics: This section provides options to choose from various adaptive heuristics (including to use none). An adaptive heuristic modifies classification values as new data relevant to the project comes in (e.g., as new audit determinations are made or as new static analysis tools are run on the code base and the tool output is loaded into the project). Many adaptive heuristics have user-editable parameters.
- Automated hyper-parameter optimization (AHPO): This section provides AHPO options. The user can select one or none.
After selecting a classification scheme, the user will be able to click a "Classify" button that will cause meta-alerts to be classified (e.g., level of confidence true or false will be predicted).
Cascading
This feature allows a user to take determinations made from a previous SCALe audit and automatically apply them to alerts generated by a new SCALe audit. The section Upload Determinations from Project in the Edit Project screen (shown in Figure 5, with red arrows pointing to where users must make selections) provides this functionality. It uses the UNIX diff utility to determine if a code line within a file from a previous version of a code base matches a code line within the current version of the code base. If the lines match and there was a previously made determination for the meta-alert, then it infers the same determination for the current meta-alert. A new note with a timestamp is added that identifies the determination as being cascaded.
Future work will analyze the accuracy of classifiers created using cascaded determinations compared to classifiers using only regular determinations.
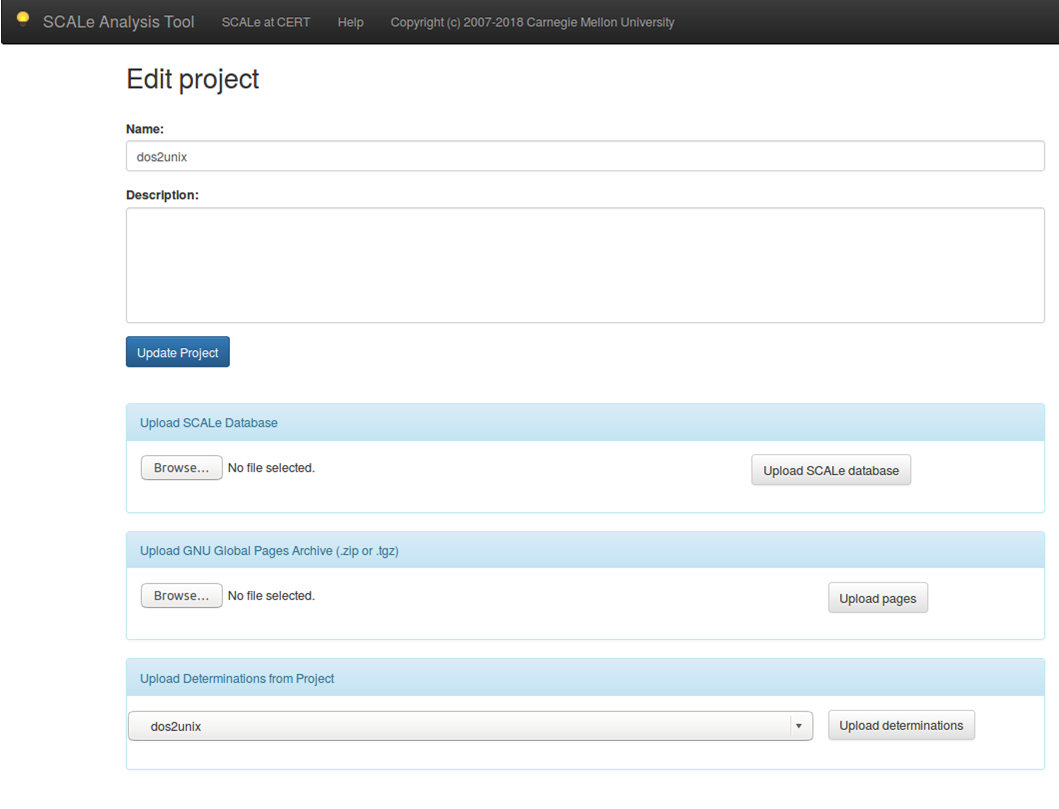
Figure 5: Upload Determinations Screen
Next Steps and Future Work
The research project that developed SCALe v3 is developing an architecture with APIs and an open-source prototype system to enable users to
- Quickly begin to use automated classifiers for their static analysis alerts.
- Quickly begin to use formulas to prioritize static analysis alerts using factors they care about. These prioritization formulas will be able to combine various fields, including classifier-derived confidence, with mathematical operators.
- Use the API definition to build on the original prototype system, enabling the use of additional
- alert auditing tools (e.g., aggregator tools like SCALe, DHS SWAMP, or Army CERDEC's Software Assessment Tool (SwAT), or single flaw-finding static analysis tools). The alert auditing tool developers simply need to instantiate the API function calls (develop what is required to make and respond to the required function calls), rather than develop all the infrastructure required for classification and advanced alert prioritization.
- flaw-finding static analysis tools, code-metrics tools, adaptive heuristics, classification techniques, code-flaw taxonomies, etc.
In the future, SCALe will interact with the other parts of the architecture and three other servers will provide external functionality. Currently, the enhancements to SCALe provide advanced prioritization and much of the classifier functionality that will be required in SCALe for a fully integrated system. Our research project team will soon publish the architecture model and the beta version of our API for the architecture. After that, we will publish a third blog post in this series.
We hope that potential collaborators will read about what we are doing with SCALe and contact us if they want to collaborate. (Collaborators are invited to implement the API from their alert auditing tool and provide feedback, to test SCALe and provide feedback, and/or to send us sanitized alert audit data with manual auditor determinations.) Other interested users should watch the SEI website for announcements about the planned public release of SCALe v 3.
Additional Resources
Read the blog posts in this series of posts on SCALe.
Read SEI press release, SEI CERT Division Releases Downloadable Source Code Analysis Tool.
Read the SEI blog post, Static Analysis Alert Test Suites as a Source of Training Data for Alert Classifiers.
Read the Software QUAlities and their Dependencies (SQUADE, ICSE 2018 workshop) paper Prioritizing Alerts from Multiple Static Analysis Tools, Using Classification Models.
Read the SEI blog post, Prioritizing Security Alerts: A DoD Case Study (In addition to discussing other new SCALe features, it details how the audit archive sanitizer works.)
Read the SEI blog post, Prioritizing Alerts from Static Analysis to Find and Fix Code Flaws.
View the presentation Challenges and Progress: Automating Static Analysis Alert Handling with Machine Learning.
View the presentation (PowerPoint): Hands-On Tutorial: Auditing Static Analysis Alerts Using a Lexicon and Rules.
Watch the video: SEI Cyber Minute: Code Flaw Alert Classification.
View the presentation: Rapid Expansion of Classification Models to Prioritize Static Analysis Alerts for C.
View the presentation: Prioritizing Alerts from Static Analysis with Classification Models.
Look at the SEI webpage focused on our research on static analysis alert automated classification and prioritization.
Read the SEI paper, Static Analysis Alert Audits: Lexicon & Rules, presented at the IEEE Cybersecurity Development Conference (IEEE SecDev), which took place in Boston, MA on November 3-4, 2016.
Read the SEI Technical Note, Improving the Automated Detection and Analysis of Secure Coding Violations.
Read the SEI Technical Note, Source Code Analysis Laboratory (SCALe).
Read the SEI Technical Report, Source Code Analysis Laboratory (SCALe) for Energy Delivery Systems.
Watch the SEI Webinar, Source Code Analysis Laboratory (SCALe).
Read the SEI Technical Note, Supporting the Use of CERT Secure Coding Standards in DoD Acquisitions.
Written By


More By The Authors
Release of SCAIFE System Version 2.0.0 Provides Support for Continuous-Integration (CI) Systems
• By Lori Flynn
PUBLISHED IN
Secure DevelopmentGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed