A Tool to Address Cybersecurity Vulnerabilities Through Design


Increasingly, software development organizations are finding that a large number of their vulnerabilities stem from design weaknesses and not coding vulnerabilities. Recent statistics indicate that research should focus on identifying design weaknesses to alleviate software bug volume. In 2011, for example when MITRE released its list of the 25 most dangerous software errors, approximately 75 percent of those errors represented design weaknesses. Viewed through another lens, more than one third of the current 940 known common weakness enumerations (CWEs) are design weaknesses. Static analysis tools cannot find these weaknesses, so they are currently not addressed prior to implementation and typically are detected after the software has been executed when vulnerabilities are much more costly and time-consuming to address. In this blog post, the first in a series, we present a tool that supports a new architecture model that can identify structures in the design and code base that have a high likelihood of containing bugs, hidden dependencies in code bases, and structural design flaws.
Foundations of our Work
At the SEI, there has been extensive research in architecture analysis, and the techniques we had previously developed, such as the Architecture Tradeoff Analysis Method (ATAM), were manual and labor-intensive. Such techniques allowed us to broadly identify risks, but we wanted the ability to zoom in and try to find the specific architectural weaknesses or flaws in the code.
This post describes our work on a design representation, known as Design Rule Space (DRSpace), and associated set of tools (Titan) that allow us to reverse engineer an existing code base, extract architectural and design information, manipulate that information in interesting ways, and then analyze that manipulated form of the information to find architectural flaws. The approach we have developed is automated, which will save developers and researchers much-needed resources and time.
Building the Design Representation
In late 2009 we began a collaboration with Yuanfang Cai and some of her doctoral students at Drexel University. We met at a conference, and we were both concerned by the lack of tool support for architecture analysis, and the lack of economic analysis of architectural decisions. We began to work together, and this collaboration has resulted in our tool, Titan, and a stream of very successful empirical research based on the growing capabilities of Titan.
Our work initially focused on development of a tool chain. On the left side of the tool chain are several artifacts. In addition to source code, these artifacts include the revision control system (e.g., Subversion or Git) that manages commits and releases etc. Our approach relies on the fact that virtually every software development projects uses issue tracking systems, for example, JIRA, to manage bugs and changes to the system. We realized that there is substantial information in these artifacts (issue tracking and revision control) that can provide valuable insights beyond code view into the design of a system and any potential sources of vulnerabilities.
Using the commercial reverse engineering tool Understand (in principle, any reverse engineering tool could be used) we were able to find out the basic facts of a system. For example, file A inherits from file B, or file A calls file B, or file A depends on file B also aggregates.
We also examined information from enterprise architects that allowed us to conduct an analysis of the designs. This analysis highlighted dependencies between files that we viewed as triples: File A, File B, and some relation between them.
Using the information we obtained, we created a design structure matrix (DSM) where all the rows represent file names. Those file names are then duplicated in the same order in the columns. The diagonal in this matrix represents the self-dependency or self-relationship. Every cell in the matrix represents some dependency between file on the row and file on the column or no dependency if none exists. This structure allowed us to view a very compact representation of all the structural relationships that exist between the files.
We next extracted the revision history of the project. Every disciplined software project maintains its source code in a revision control system so that when changes are made to a file, an artifact is checked in for that change. Reviewing the revision history provides a historical record of how the project has evolved.
Using that historical record we built a separate history DSM that allowed us to view history dependencies between files. For example, if a developer makes a change to fix a bug or implement a feature, several files might have to be changed simultaneously. This matrix allowed us to realize that if files A and B are checked in in the same commit to the revision history, then they have a history dependency.
So, using the two dependencies, every time file A and file B are committed together, we note that in the DSM for all A and all B. Now we have the two sources of information: one representing structural dependencies, one representing historical dependencies.
Next, we clustered the matrix using design rule hierarchy (DRH), a DSM clustering algorithm where the lower layers depend on the higher layers and the modules in the same layers are independent of each other. As illustrated in the figure below, DRH reorders the rows and the columns so the most important files, the files that most others depend on, are at the top. Then, underneath those are files they depend on, and underneath those are the files they depend on, and so forth.
Our architectural representation known as Design Rule Space (DRSpace) is formed by selecting structural and evolutionary dependency relationships and then clustering them using the design rule hierarchy algorithm.
The concept of a DRSpace is based on design rule theory proposed by Baldwin and Clark that explains how modularity adds value to a system in the form of options. Their theory suggests that independent Modules are decoupled from a system by the creation of design rules. The independent Modules should only depend on design rules. As long as the design rules remain stable, a module can be improved, or even replaced, without affecting other parts of the system.
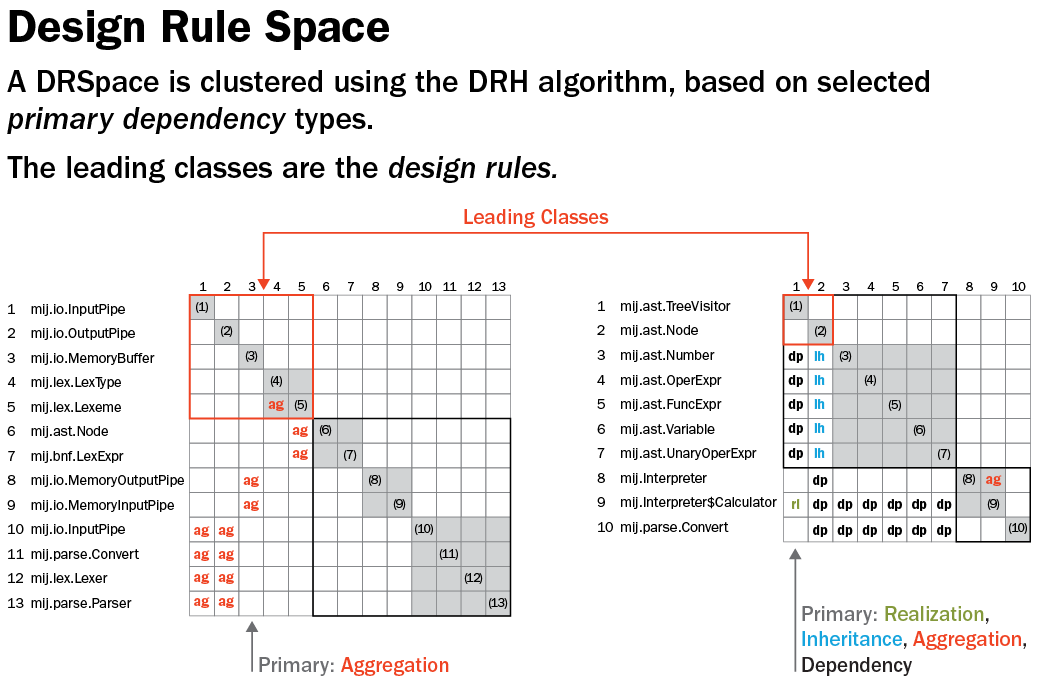
One example of a design rule would be a programmer that uses the Abstract Factory pattern in a system. As a result, many other files in the system depend on that abstract. There will be classes that implement the Abstract Factory interface, that inherit from it, that depend on it, that use it, and that aggregate it. The Abstract Factory representation is the design rule that other files will depend upon. To summarize, our approach presents a cluster of the architecture in terms of dependencies with the leading classes (i.e., the most important design rules) at the top.
Analyzing the Matrix for Prototypical Flaws
We have now analyzed more than 150 projects (120 open source and 30 closed-source), written in C, C++, C#, Java, and PHP, using this tool chain. These projects cover a wide range of application domains, and range from modest size to the largest of software systems, such as operating systems, databases, web servers, and many others.
Having structured the project's DSM as a DRH, we can now examine it for prototypical flaws including
- cyclic dependencies. This is where, for example, File A depends on File B, File B depends on File C, and File C depends on File A, creating a cycle of dependencies. Such cycles are notoriously difficult to maintain, as it is difficult to predict the consequences of a change to any of A, B, or C.
- improper inheritance. This is where a parent class depends on one of its subclasses, or a client of the inheritance hierarchy depends on both the parent class and a subclass (e.g., File B inherits from File A, but File A depends on File B.) For more on this, see Hotspot Patterns: The Formal Definition and Automatic Detection of Architecture Smells.
- modularity violations. While improper inheritance and cyclic dependencies represent purely structural issues, a DRSpace also allows us to identify modularity violations (i.e., two or more files change together frequently and regularly in a system's revision history, but have no structural relationship to one another). Modularity violations suggest that those files share some secret or knowledge and that information has not been encapsulated or modularized.
- unstable interface. This type of flaw occurs when you have a file that many other files depend on (a leading file) and that file changes frequently and contains bugs.
These last two violations, modularity violations and unstable interface, can only be identified if the structural and history information are combined. The history information, which consists of both changes and bugs, can be gathered and distinguished because we also relied on a third source of data: the issue tracking system. In modern, mature projects, when a change is committed to the revision control system, developers are required to include a note in the commit message that describes what issue from the issue tracking system that this change addressed. This feature is key to our approach because it allows us to distinguish commits to resolve bugs from commits to make changes for new features. This type of reporting is important because it allows us to distinguish different kinds of problems in the revision history and identify what problems are causing bugs, unnecessary amounts of changes, and other issues that can be pathological problems for a project, including excessive churn (the committed lines of code).
Transitioning to Our Stakeholders: The Department of Homeland Security and Beyond
The Department of Homeland Security (DHS) Science and Technology Directorate (S&T) provided CERT with funding to explore making the Titan tool and design representation available in the Software Assurance Marketplace (SWAMP). SWAMP, which went live in February 2014, was assembled from Indiana University's Center for Applied Cybersecurity Research, the NCSA Cybersecurity Directorate at the University of Illinois Urbana-Champaign, the University of Wisconsin-Madison Middleware Security and Testing group, and the Morgridge Institute for Research .
Most projects in our experience do not distinguish bugs as being security-based or not security based. With the SWAMP project we focused on implementing our design algorithm and Titan tool to identify security bugs in a system as well as changes made to implement security features.
We applied our approach to 10 large-scale open-source systems (HTTP Server, PHP, Tomcat, Avro, Camel, CXF, Derby, Hadoop, Chromium, and HBase), and we determined that, in addition to looking at bugs and changes, we are going to focus on security bugs and security changes. We found the same pattern that we had identified in previous tests of our approach: a .9 correlation between architectural flaws and security bugs and security changes.
Economic Analysis: A Return on Investment for Refactoring
Our recent research has shown that defective files seldom exist alone in large-scale software systems. They are usually architecturally connected, and their architectural structures exhibit significant design flaws that propagate bugginess among files. We call these flawed structures the architecture roots, a type of technical debt that incurs high maintenance penalties.
Using our DRSpace approach and Titan tool we were able to examine projects for different classes of files. For example, we can examine a part of a project with zero design flaws and zero structural flaws and calculate the bug rate and change rate. Next, we can examine the bug rate and change rate in problematic areas of a project. This analysis allows us to calculate the benefits if architectures were to break the cyclic dependencies by refactoring the project to remove the modularity violations and other issues.
Removing the architecture roots of bugginess requires refactoring, but the benefits of refactoring have historically been difficult for architects to quantify or justify. Working with researchers from Drexel, we recently applied our approach to identify and quantify such architecture debts in a large-scale industrial software project. This application and the economic case we were able to make for refactoring will be described in the next blog post in this series.
Wrapping Up and Looking Ahead
Architecture problems lead to quality issues. The approach that we have devised allows us to bridge the gap between architecture and quality. Using the Titan tool and the DRSpace-based analysis approach we can more accurately pinpoint design flaws including
- cyclic class dependencies
- cyclic package dependencies
- improper inheritance
- modularity violations
- unstable interfaces
The identification of such flaws allows us to assess the technical debt and its economic impact and predict the economic impact of repair strategies.
We welcome your feedback on this approach in the comments section below.
Additional Resources
Read our paper A Case Study on Locating the Architectural Roots of Technical Debt, which I coauthored along with Yuanfang Cai, Ran Mo, Qiong Feng, Lu Xiao, Serge Haziyev, Volodymyr Fedak, and Andriy Shapochka.
On a separate front, the Titan software is being licensed by Drexel, and is available for academics. For more information, please visit http://drexel.edu/commercialization/about/contact/.
View the talk that Rick Kazman gave on this research called Locating the Architectural Roots of Technical Debt at the 2015 Saturn Conference.
View the presentation Hotspot Patterns: The Formal Definition and Automatic Detection of Architecture Smells by R. Mo, Y. Cai, R. Kazman, L. Xiao, from the Proceedings of the 12th Working IEEE/IFIP Conference on Software Architecture (WICSA 2015).
Written By


More By The Authors
Measurement Challenges in Software Assurance and Supply Chain Risk Management
• By Nancy R. Mead, Carol Woody, Scott Hissam
More In Software Architecture
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed