Tactics and Patterns for Software Robustness

Robustness has traditionally been thought of as the ability of a software-reliant system to keep working, consistent with its specifications, despite the presence of internal failures, faulty inputs, or external stresses, over a long period of time. Robustness, along with other quality attributes, such as security and safety, is a key contributor to our trust that a system will perform in a reliable manner. In addition, the notion of robustness has more recently come to encompass a system’s ability to withstand changes in its stimuli and environment without compromising its essential structure and characteristics. In this latter notion of robustness, systems should be malleable, not brittle, with respect to changes in their stimuli or environments. Robustness, consequently, is a highly important quality attribute to design into a system from its inception because it is unlikely that any nontrivial system could achieve this quality without conscientious and deliberate engineering. In this blog post, which is excerpted and adapted from a recently published technical report, we will explore robustness and introduce tactics and patterns for understanding and achieving robustness.
Defining Robustness
Robustness is certainly an important quality of software systems. Gerald Jay Sussman, in his essay “Building Robust Systems: An Essay,” defines robust systems as “systems that have acceptable behavior over a larger class of situations than was anticipated by their designers.” Avizienis and colleagues define robustness as “dependability with respect to erroneous input.” We claim that a system is “robust” if it
- has acceptable behavior in normal operating conditions over its lifetime
- has acceptable behavior in stressful environmental conditions (e.g., spikes in load)
- can recover from or adapt to states that are outside its proper operating specification
- can evolve and adapt to changes in its environment and stimuli with only minor changes
But how do we actually achieve robustness? In the remainder of this post, we will discuss and provide examples of two important kinds of design mechanisms: tactics and patterns. These mechanisms are the architect’s main tools to achieve a desired set of robustness characteristics.
Architectural Tactics
Since tactics are simpler and more fundamental than patterns, we begin our discussion of mechanisms for robustness with them. Tactics are the building blocks of design, the raw materials from which patterns, frameworks, and styles are constructed. Each set of tactics is grouped according to the quality attribute goal that it addresses. The goals for the robustness tactics shown in the figure below are to enable a system, in the face of a fault, to prevent, mask, or repair the fault so that a service being delivered by the system remains compliant with its specification.
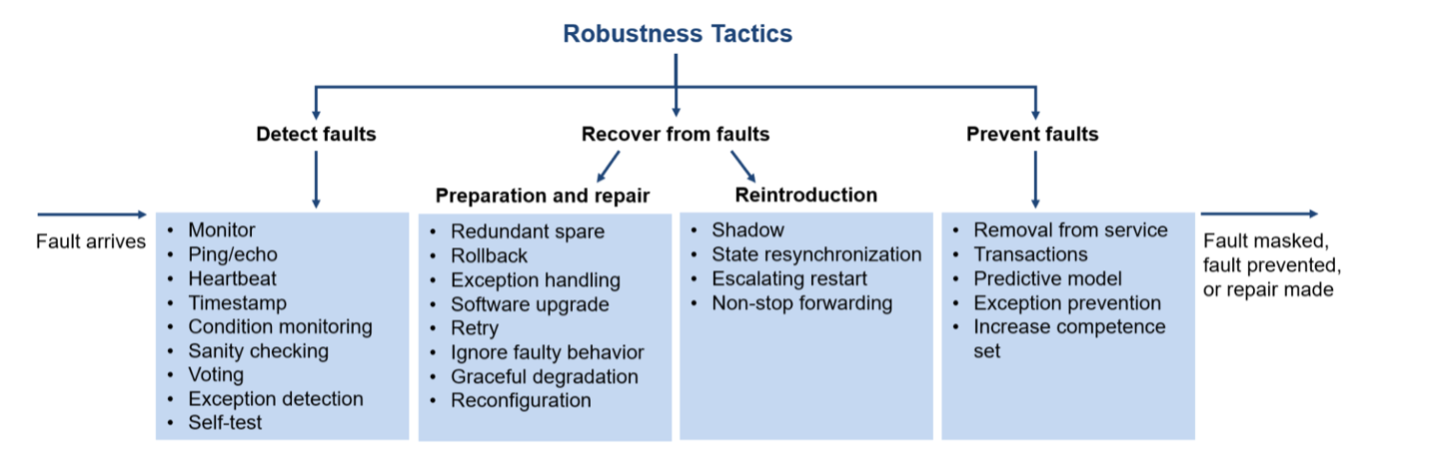
These tactics are known to influence the responses (and hence the costs) in the general scenario for robustness (e.g., number of components affected, effort, calendar time, new defects introduced). By consciously managing these system strategies and concerns, architects can design to reduce the likelihood of a failure, thereby increasing the mean time to failure (MTTF) measure, or to recover from failures more quickly, thus reducing the mean time to repair (MTTR) measure.
Detect Faults—Before any system can take action regarding a fault, the presence of the fault must be detected or anticipated. Tactics in this category include the following:
- Monitor. A monitor is a component that is used to monitor the state of health of various other parts of the system: processors, processes, input/output, memory, and so forth.
- Ping/echo. Ping/echo refers to an asynchronous request/response message pair exchanged between nodes, used to determine reachability and the round-trip delay through the associated network path.
- Heartbeat. A heartbeat is a fault detection mechanism that employs a periodic message exchange between a system monitor and a process being monitored.
- Timestamp. This tactic is used to detect incorrect sequences of events, primarily in distributed message-passing systems.
- Condition monitoring. This tactic involves checking conditions in a process or device or validating assumptions made during the design.
- Sanity checking. This tactic checks the validity or reasonableness of specific operations or outputs of a computation.
- Voting. The most common realization of this tactic is referred to as triple modular redundancy (or TMR), which employs three components that do the same thing, each of which receives identical inputs and forwards its output to voting logic, used to detect any inconsistency among the three output states.
- Exception detection. This tactic is used for detecting a system condition that alters the normal flow of execution.
- Self-test. Elements (often entire subsystems) can run procedures to test themselves for correct operation. Self-test procedures can be initiated by the element itself or invoked from time to time by a system monitor.
Recovery from Faults—Recover from faults tactics are refined into preparation and repair tactics and reintroduction tactics. The latter are concerned with reintroducing a failed (but rehabilitated) element back into normal operation.
Preparation and repair tactics are based on a variety of combinations of retrying a computation or introducing redundancy. They include the following:
- Redundant spare. This tactic has three major manifestations: active redundancy (hot spare), passive redundancy (warm spare), and spare (cold spare).
- Rollback. Rollback. This tactic permits the system to revert to a previous known good state, referred to as the “rollback line”—rolling back time—upon the detection of a failure.
- Exception handling. After an exception has been detected, the system must handle it in some fashion.
- Software upgrade. The goal of this tactic is to achieve in-service upgrades to executable code images without affecting services.
- Retry. The retry tactic assumes that the fault that caused a failure is transient and retrying the operation may lead to success.
- Ignore faulty behavior. This tactic calls for ignoring messages sent from a particular source when the system determines that those messages are spurious.
- Graceful degradation. This tactic maintains the most critical system functions in the presence of element failures, dropping less critical functions.
- Reconfiguration. Using this tactic, a system attempts to recover from failures of a system element by reassigning responsibilities to the resources left functioning, while maintaining as much of the critical functionality as possible.
Reintroduction is where a failed element is reintroduced after a repair has been performed. Reintroduction tactics include the following:
- Shadow. This tactic refers to operating a previously failed or in-service upgraded element in a “shadow mode” for a predefined duration of time prior to reverting the element back to an active role.
- State resynchronization. This tactic is a reintroduction partner to the active redundancy and passive redundancy preparation and repair tactics.
- Escalating restart. This reintroduction tactic allows the system to recover from faults by varying the granularity of the element(s) restarted and minimizing the level of service affectation.
- Non-stop forwarding. The concept of non-stop forwarding originated in router design. In this design, functionality is split into two parts: supervisory, or control plane (which manages connectivity and routing information), and data plane (which does the actual work of routing packets from sender to receiver).
Prevent Faults—Instead of detecting faults and then trying to recover from them, what if your system could prevent them from occurring in the first place? Although this sounds like some measure of clairvoyance might be required, it turns out that in many cases it is possible to do just that. Tactics in this category include
- Removal from service. This tactic refers to temporarily placing a system element in an out-of-service state for the purpose of mitigating potential system failures.
- Substitution. This tactic employs safer protection mechanisms—often hardware-based—for software design features that are considered critical.
- Transactions. Systems targeting high-availability services leverage transactional semantics to ensure that asynchronous messages exchanged between distributed elements are atomic, consistent, isolated, and durable. These four properties are referred to as the “ACID properties.”
- Predictive model. A predictive model, when combined with a monitor, is employed to monitor the state of health of a system process to ensure that the system is operating within its nominal operating parameters and to take corrective action when conditions are detected that are predictive of likely future faults.
- Exception prevention. This tactic refers to techniques employed for the purpose of preventing system exceptions from occurring.
- Abort. If an operation is determined to be unsafe, it is aborted before it can cause damage. This tactic is a common strategy employed to ensure that a system fails safely.
- Masking. A system may mask a fault by comparing the results of several redundant upstream components and employing a voting procedure in case one or more of the values output by these upstream components differ.
Architectural Patterns
As stated above, architectural tactics are the fundamental building blocks of design. Hence, they are the building blocks of architectural patterns. During analysis it is often useful for analysts to break down complex patterns into their component tactics so that they can better understand the specific set of quality attribute concerns that patterns address, and how. This approach simplifies and regularizes analysis, and it also provides more confidence in the completeness of the analysis.
In the remainder of this post, we provide a brief description of a set of patterns, a discussion of how the patterns promote robustness, and the other quality attributes that are negatively impacted by these patterns (tradeoffs). Just because a pattern negatively impacts some other quality attribute, however, does not mean that the levels of that quality attribute will be unacceptable. This is not to say, however, that the resulting latency of the system will be unacceptable. Perhaps the added latency is only a small fraction of end-to-end latency on the most important use cases. In such cases the tradeoff is a good one, providing benefits for robustness while “costing” only a small amount of latency.
The purpose of this section is to illustrate the most common robustness patterns—process pairs, triple modular redundancy, N+1 redundancy, circuit breaker, recovery blocks, forward error recovery, health monitoring, and throttling—and to show how analysts can break patterns down into tactics that allow them to understand the patterns’ quality attribute characteristics, strengths, weaknesses, and tradeoffs.
Process pairs—The process pairs pattern combines software (and sometimes hardware) redundancy tactics with transactions and checkpointing. Two identical processes are running, with one process being designated the “primary” or “leader.” This primary process is the one that clients interact with at runtime, under normal circumstances. As the primary process processes information, it bundles its execution into transactions.
The benefit of process pairs, over simply using a transaction mechanism, is that upon failure of the primary process. the recovery is very fast (as compared with restarting the primary process and playing back the transaction log to recreate the state just prior to the failure).
The tradeoff of this pattern is that requires the expenditure of additional software, networking, and potentially hardware resources. Adding the checkpointing and failover mechanisms increases up-front complexity.
Triple modular redundancy—The triple modular redundancy (TMR) pattern is one of the earliest known robustness patterns. Its roots can be traced back to at least 1951 in computer hardware, where TMR was used in magnetic drum memory to ameliorate the inherent unreliability of individual elements. It builds upon the active redundancy tactic, where two or more elements process the same inputs in parallel. Many variants of this pattern exist, such as quad-modular redundancy (QMR) and N-modular redundancy. In each case one node may be elected as “active” with the other nodes processing all inputs in parallel, but only being activated in case the active node fails. In other versions there is a voting process where the voter collects and compares the votes from each of the replicated nodes; if a node disagrees with the majority, it is marked as failed and its outputs are ignored.
The most obvious benefit of TMR is the avoidance of a single point of failure. Likewise, if a voter is used, then this pattern also includes a fault detection mechanism.
One tradeoff is that redundancy greatly increases the hardware costs for the system, its complexity, and its initial development time. Moreover, systems using this pattern consume substantially more resources at runtime (e.g., energy and network bandwidth). Finally, there is the added complexity of determining which of the nodes to anoint as the “active” node and, in case of failure, which backup to promote to active status.
N + 1 redundancy - The N+1 redundancy pattern builds upon one or more redundancy tactics. In this pattern there are N active nodes, with one spare node. The assumptions are that the active nodes have similar functionality and the spare node can be introduced to replace any of the N active nodes if one of them has failed. The one spare node may be an active spare, meaning that it processes all the same inputs as the system(s) that it is mirroring; it may be a passive spare, meaning that the active nodes periodically send it updates; or it may be a cold spare, meaning that when it takes the place of a failed node it initially has none of that node’s state.
Clearly N+1 redundancy provides the benefit of any redundancy pattern, which is the avoidance of a single point of failure. Also, N+1 redundancy is much less expensive than TMR, QMR, or similar patterns that require a heavy investment in software and hardware, since a single backup node can back up any chosen number of active nodes.
The higher the N, the greater the likelihood that more than one failure could occur. The lower the N, the more an implementation of this pattern costs, in terms of redundant hardware and the attendant energy costs.
Circuit breaker pattern—The circuit breaker pattern is used to detect failures and prevent the failure from constantly reoccurring or cascading to other parts of a system. It is commonly used in cases where failures are intermittent. A circuit breaker is a combination of a timeout (an exception detection tactic) and a monitor, which is an intermediary between services.
The benefit of this pattern is that it limits the consequences of a failure by wrapping the interface to that element and returning immediately if a failure has been detected. This can greatly reduce the amount of resources wasted on retrying a service that is known to have failed.
The circuit breaker pattern will negatively affect performance. Like many robustness patterns, this tradeoff is often considered to be justifiable, particularly if services experience intermittent and transient failures.
Recovery blocks—The recovery blocks pattern is used when there are several possible ways to process a result based on an input and one is chosen as the primary processing capability. After the primary processing capability returns a result, it is passed through an acceptance test. If this test fails, this pattern then tries passing the input to a second processing capability. This second processing capability acts as a recovery block for the primary. This process can continue for any number of backup processing capabilities. This pattern is a kind of N-version programming, or it may be realized as a form of analytic redundancy.
This pattern is useful in cases where the processing is complex, where high availability is desired, but where hardware redundancy is not a viable option. This pattern does not protect against hardware failures, of course, but it does provide some protection against software failures and bugs.
One tradeoff is that if the serial variant of this pattern is employed, latency (from the time the input arrives to the time that an acceptable result is produced) will be increased in cases where one or more acceptance tests fail. If the parallel variant of this pattern is employed, substantially more CPU resources will be consumed to process each input.
Forward error recovery - The forward error recovery pattern is a kind of active redundancy employed in situations where relatively high levels of faults are expected. The idea of forward error recovery originated in the telecommunications domain, where communication over noisy channels resulted in large numbers of packets being damaged, resulting in large numbers of packet retries. This was expensive, particularly in the early days of telecommunications or in cases where latency was very large (for example, communication with space probes). To attempt to address this shortcoming, packets were encoded with redundant information so that they could self-detect and self-correct a limited number of errors.
This pattern is useful in cases where the underlying hardware or software is unreliable and where it is possible to encode redundant information. As with most patterns for robustness, higher levels of availability can be costly.
Health monitoring—In complex networked environments, just determining the health of a remote service may be challenging. To achieve high levels of availability, it is necessary to be able to tell, with confidence, whether a service is operating consistently with its specifications. The health monitoring pattern (sometimes called “endpoint health monitoring”) addresses this need. The monitor is a separate service that periodically sends a message to every endpoint that needs to be monitored. The simplest form of this pattern is ping/echo, where the monitor sends a ping message, which is echoed by the endpoint. But more sophisticated checks are common—instances of the monitor tactic—such as measuring the round-trip latency for send/response messages and checking on various properties of the monitored endpoints such as CPU utilization, memory utilization, application-specific measures, and so forth.
This pattern is useful in cases where the system is distributed and where the health of the distributed components cannot be assessed locally in a timely fashion (for example, by waiting for messages to time out). This pattern also allows for arbitrarily sophisticated measures of health to be implemented.
As with the other patterns for robustness, monitoring requires more up-front work than not monitoring. It also requires additional runtime processing and network bandwidth.
Throttling—In contexts where demand on the system, or a portion of the system, is unpredictable, the throttling pattern can be employed to ensure that the system will continue to function consistently with its service-level agreements and that resources are apportioned consistently with system goals.
The idea is that a component, such as a service, monitors its own performance measures (such as its response time), and when it approaches a critical threshold it throttles incoming requests. A number of throttling strategies can be employed—each of these corresponding to a Control Resource Demand tactic. For example, the throttling could mean rejecting requests from certain sources (perhaps based on their priority, criticality, or the amount of resources that they have already consumed), disabling or slowing the response for specific request types (for less essential functions), or reducing response time evenly for all incoming requests.
The goal of robustness is for a software-reliant system to keep working, consistently with its specifications, despite the presence of external stresses, over a long period of time. The Throttling pattern aids in this objective by ensuring that essential services remain available, at the cost of degrading some kinds or qualities of the system’s functionality.
As with the other patterns for robustness, throttling requires more up-front work than not throttling, and it requires a small amount of runtime processing to monitor critical resource usage levels and to implement the throttling policy.
Architectural Mechanisms for Achieving Robustness
We have now seen a broad sample of architectural mechanisms—tactics and patterns—for achieving robustness. These proven mechanisms are useful in both design—to give a software architect a vocabulary of design primitives from which to choose—and in analysis, so an analyst can understand the design decisions made, or not made, their rationale, and their potential consequences.
Additional Resources
Read the SEI technical report from which this post is excerpted, Robustness, which I coauthored with Philip Bianco, Sebastián Echeverría, and James Ivers.
Written By

More By The Author
More In Software Architecture
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed