Aligning DevSecOps and Machine Learning

Over the past few years, society has seen a rebirth of interest in artificial intelligence (AI) and, more specifically, machine learning (ML) applications. As is typical in time periods of hardware performance spikes in which computer scientists can increase the throughput of their systems, researchers have been using computers to learn from patterns in data that once took an impractical amount of time to process. This capability has not been limited to large, corporate entities; the advent of graphics processing units (GPUs) has enabled even non-corporate equipment to process large data sets. On a corporate scale, machines with multiple GPUs are used in data centers to mine information and identify data patterns like never before.
How can engineers organize such systems to take advantage of all the practices proposed by Agile methodologies and the more recent DevSecOps developments? In this blog post, I will explore the machine learning (ML) and DevSecOps domains and propose ways to use them in collaboration for increased performance.
Understanding Pipelines
When software engineers say pipeline, they usually mean a set of tools chained together—into some form of framework—that provide the necessary glue-code to stitch them together. This glue-code usually has functions of storing and retrieving information from a data repository that is common to all tools, or at least moving data from one tool to the next in line.
The two domains we are talking about in this article are ML and DevSecOps. In this context, a pipeline may mean a learning ML pipeline that is used to process data for an ML framework. A pipeline may also be a DevSecOps pipeline that is used to transform source code into a built product, using build directives, as well as functional and security testing.
Machine Learning Pipelines
An ML pipeline is a chain of tools used to automate the processes in an ML machine learning workflow. These tools allow the transformation and correlation of data into a model that will be later used to evaluate other data sets and provide a measure of how closely their characteristics resemble the original training data.
ML pipelines are inherently iterative and consist of many different steps to load information, extract the desired characteristics from the information, and store the summarized learnings in a model. To achieve better accuracy, the model is trained with relevant data sets, which not only display the desired characteristics, but also present them in a way that resembles the real cases that will be analyzed once the training is done. A large, responsive storage layer is also fundamental to contain the training, testing and real data, as well as the large binaries that represent the trained models.
The illustration below displays—in a very simplified way—the two main modes of operation in an ML pipeline: training mode and testing mode. During the training phase, sample data that contains the patterns for training the model is fed into the pipeline, and such patterns are correctly identified by engineers. Subsequently, real world data will be passing through the pipeline in testing mode, and based on the patterns recorded previously in the model, similar patterns found in the new data will trigger positive reactions (predictions).
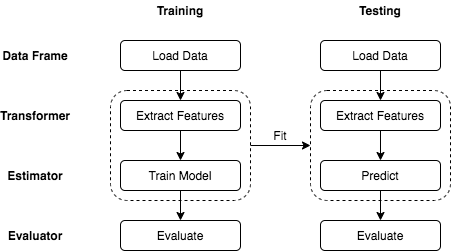
DevSecOps Pipelines
A DevSecOps pipeline consists of automated procedures that enable collaboration, manage risk and security, provide resilience, build, package and deploy systems to meet stakeholder needs. It contains a chain of all the tooling used to process information that will result in the creation and testing of software. If the build product satisfactorily passes all tests, then it may become a candidate for a release. Otherwise, the team receives feedback about any eventual failures along the process and goes back into another development iteration.
The illustration below shows a generic DevSecOps pipeline that accommodates all the IEEE processes.

The processes in the DevSecOps pipeline heavily rely on continuous integration (CI) and continuous delivery (CD) methodologies. CI is a process that continually merges a system’s artifacts, including source code updates and configuration items from all stakeholders on a team, into a shared mainline to build and test the developed system. CD is a software engineering practice that allows for frequent releases of new software to staging or various test environments through the use of automated testing.
Throughout the DevSecOps pipeline, the project team will capture all the initial versions of the requirements for the system, and will also record any changes in time that reflect the evolution of the functional needs for that system. As the requirements are turned into architectural features and finally code, the pipeline will attempt to build the system periodically and apply automated tests to ensure the security of the software and also that the system requirements have been fully satisfied.
At the end of these processes, the resulting build products are delivered to different environments, culminating with a deployment into production. Depending on environment constraints, the last step (deployment to production) may not be always feasible. DevOps is built upon Agile, so software production activities are naturally iterative and can accommodate changes at any point in time during the software development lifecycle.
The benefits of the DevSecOps pipeline include the following:
- reduction of manual labor and human error
- enforcement of parity across environments
- auditability, visibility, and traceability
- built-in security via environment parity
- guaranteed, consistent results
Which Comes First?
Now that we understand the main features of both pipelines, the million-dollar-question is: How do we put all this together?
The simple answer is: it depends on what one wants to accomplish. If the goal is to provide a solid infrastructure for the development of a system that focuses largely on ML, then we must direct our attention to how we can provide the project team with all the tools they need to implement a DevSecOps pipeline that also contains all the additional features to support the ML function of the system. Providing this capability is described in the DevSecOps for AI section below.
If the goal is to generate a DevSecOps pipeline that responds and adapts to changes in the environment or some other characteristic tracked and measured by the project team, then we may need to implement a pipeline that changes its behavior when the tracked features change. This approach is novel and is described in the AI for DevSecOps section below.
Figure 3 below is an attempt to simplify the representation of all the layers involved in providing the necessary infrastructure for both of the approaches described above. It shows how the individual infrastructures for the two pipelines are connected and built, from hardware moving up into the software.
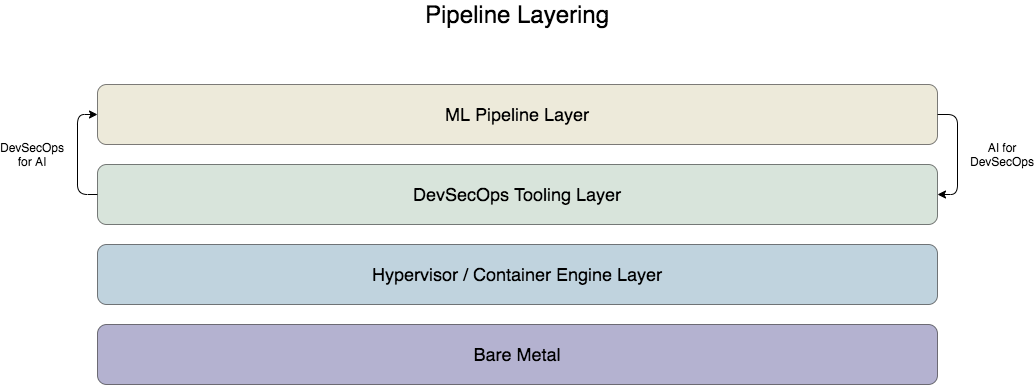
DevSecOps for AI
When creating a DevSecOps pipeline that performs adequately for an AI or ML process, there are many steps that must be addressed to ensure that the different objectives of the various layers of the infrastructure function properly.
First, ensure that all the hardware resources are available and accessible in the machines that will execute the processes. With that in place, the next step establishes the DevSecOps pipeline tooling, which may appear as a containerized solution. On top of the tooling, which has been specifically configured for the type of system one is building, the ML pipeline will appear to allow performing the basic ML system functions (e.g., data collection, model training, and model testing).
Below is a detailed list of steps to follow when creating a DevSecOps pipeline for an ML Process:
A. Basic DevSecOps Steps:
- Ensure compliance with the policies and guidelines coming in from the governance phase.
- Capture and record the requirements for the system development.
- Define the system architecture as a systems engineering functional model that satisfies the previously captured requirements.
- Prepare the test cases that closely match the requirements.
- Develop and build the system.
- Perform functional and security testing, using all the test cases established in Step 4.
- Deliver and deploy the system to its final production environment.
B. ML-specific Steps
- Configure development, testing, and production environments that have proper access to a responsive storage layer that allows training, testing and real data storage and create targets to run these processes for ease-of-use.
- Allow easy distribution of the created, tested and versioned models, enabling traceability across changing features and requirements.
- Provide proper configuration of additional hardware (GPUs) and ensure that they are accessible throughout the software development lifecycle. This step can be tricky, due to the challenge of accessing hardware from within virtual machines and containers. The selection of the framework is fundamental to provide access to the hardware capabilities.
- Enable post-delivery monitoring to ensure the system is not resource-constrained and performs as expected.
AI for DevSecOps
Introducing AI or ML processes into a DevSecOps pipeline is a new trend that has been gaining recognition in some sectors. Until now, DevSecOps pipelines were running a quasi-linear process that always followed the same path. System designers and engineers ask new questions centered around other possible scenarios that may not appear in the system lifetime until a certain event occurs. That event may trigger behaviors that will require changes in the system structure or architecture.
As an example, security threats may lead to changes not only in configuration, but to which components, topologies, or architecture are used in a system. By evaluating some measurable aspects of the system operation (e.g., log files), ML processes can feed data into a repository. This repository can then be considered in a forthcoming release to automatically define a better approach to build the software. This sort of problem has been studied for years by researchers working on self-adapting systems, which have only recently been able to perform dynamic reconfigurations of their systems through the techniques described here.
The biggest challenge in AI for DevSecOps is an extension of a known DevOps problem: glue-code. DevOps engineers are familiar with the fact that writing a large amount of glue-code to tie all the different components of a pipeline is a common unmentioned, but time-consuming task. Most of the CI frameworks available today allow for some configurability, but very few people have played with the possibility of defining different paths based on metrics or analytics. Implementing a mechanism that allows the lane-switching capability described above may quickly become a burden on any project teams that decide to play with this new trend.
A more complex scenario may present two pipelines that share common characteristics and use the switches to evaluate the quality of the identified ML patterns. Figure 4 below illustrates our example.
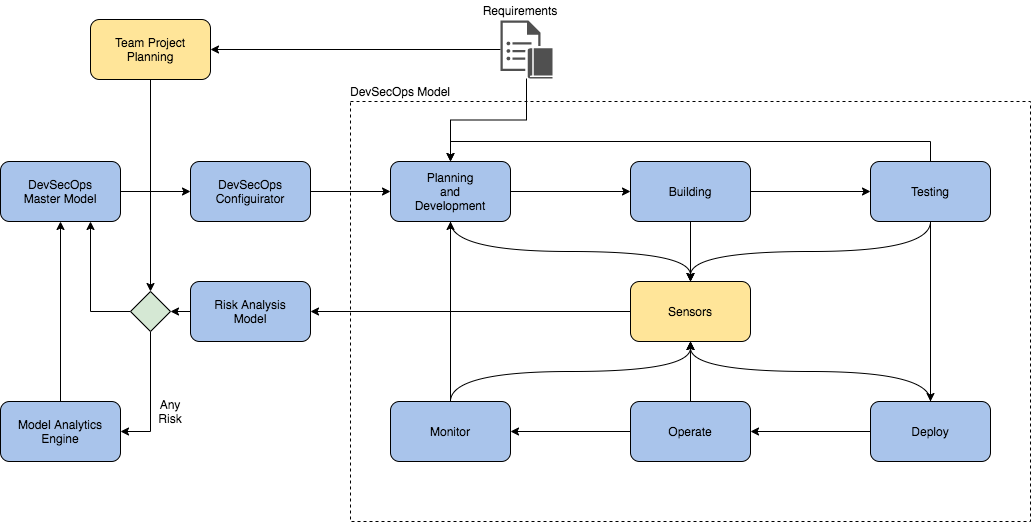
When the analyzed data falls into a known pattern, the ML processes can evaluate it and avoid any changes in the way the software is configured or built. If—for any reasons—the detected patterns show a lack of similarity with previously learned patterns, it may be time to dispatch a re-training of the models used to detect them, prior to rebuilding the software. The co-dependence on the models and how data is shared across the two pipelines may impose challenges that are too large to resolve with commercial off-the-shelf (COTS) tools, a technical or financial burden that would prove unfeasible for many projects.
An Ideal Configuration
The fusion of DevSecOps and ML is a very recent phenomenon. Many different organizations are still attempting to find out what can be achieved with this association and at what cost. No one has a definitive position or a very strong statement about how it must be done and what the best practices are. With that said, there are certain practices that can be proposed as basic guidance to achieve solid results in an organized way that presents minimal conflicts across the different sections of the pipelines and their architectural characteristics:
- No matter how a DevSecOps pipeline and an ML pipeline are combined, the fundamental behaviors of both must not be altered. The introduced behaviors should always add to the existing set of functions in the pipeline, without blocking or causing destructive interference with the original pipeline functions.
- Any results coming from any analytic processes that may guide or modify the pipeline behaviors must be made available to the parts of the system that evaluate those results. For example, if analysis results are stored in a data repository, then that repository must be accessible from the location that runs the code to evaluate those results.
- Any teams working on such pipeline association should go through a forecast process to understand the processing needs of the executed algorithms. There should always be enough processing power (CPU or GPU) and additional memory and storage for the products of the analysis.
- In the case of air-gapped system components, there should be provisions to mitigate any lack of connectivity or information filtering from one classification domain into another. Implementing automated gates, when possible, or at least an automated notification system for human interaction, can largely reduce discontinuities along the pipelines.
Attempting to provide an authoritative opinion on a configuration of ML and DevSecOps pipelines may lead to premature or vague statements. Following our proposed practices—in addition to the system’s own requirements—is a good starting point due to their simplicity. Any additional complexity should be built around a simple—but already functional—first implementation.
Accounting for Bias
Any system using ML should be aware of the risks posed by false positives and negatives, and how these results may influence the analysis process. Business requirements frequently permeate the software through models or rules that oversimplify cases—sometimes for the sake of performance. These rules sometimes introduce limitations in identifying patterns, and perform poorly when looking at edge cases that had not been considered when the model was trained. According to Sanghamitra Dutta, a doctoral candidate in electrical and computer engineering (ECE) at Carnegie Mellon University, “AI decisions are tailored to the data that is available around us, and there have always been biases in data, with regards to race, gender, nationality, and other protected attributes. When AI makes decisions, it inherently acquires or reinforces those biases.”
Even though it’s easy to proceed without any controls against bias, the introduction of measures that evaluate the outputs of the models to avoid stereotyping is a very useful and sometimes a financially justifiable effort. If the system only proceeds in its pattern matching after human adjudication, that step may help cover any inherent bias unfairness coming from the model. However, a system should not rely on a human step that can quickly become a bottleneck—or even a blocker—to its designed functions and scalability.
We strongly recommend that organizations properly record all the definitions that led to the constructions of the models, so identified patterns can be explained and defended by those principles. In case any modifications are necessary, the model should be retrained and the modifications added to the records with a full explanation of what failed and made their existence necessary.
Using ML Within DevSecOps Pipelines
This post aimed to:
- Situate someone who is not completely familiar with the ML landscape or the latest trends in DevSecOps in the latest trends in those areas
- Provide suggestions on how to use ML from within DevSecOps pipelines, along with some limited understanding of the benefits and underlying problems from such combination
Even though this blog post did not suggest specific tools, visualizing alternatives for a configuration is not a complex task. The complexity of such an implementation would reside in stitching all the tools together for a smooth and seamless operation, because no known frameworks operate in this fashion yet.
Organizations that are familiar with DevSecOps tools should be able to implement the basic parts of the pipeline configuration, while taking the ML piece as a fresh challenge. We are interested in working with organizations and offering guidance on the variety of systems they are likely to encounter, as well as providing a synopsis of the accumulated knowledge required to assemble these solutions, including within the DoD and other government agencies.
Additional Resources
Read more about the SEI’s work in DevSecOps.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed