Continuous Integration in DevOps

When Agile software development models were first envisioned, a core tenet was to iterate more quickly on software changes and determine the correct path via exploration--essentially, striving to "fail fast" and iterate to correctness as a fundamental project goal. The reason for this process was a belief that developers lacked the necessary information to correctly define long-term project requirements at the onset of a project, due to an inadequate understanding of the customer and an inability to anticipate a customer's evolving needs. Recent research supports this reasoning by continuing to highlight disconnects between planning, design, and implementation in the software development lifecycle. This blog post highlights continuous integration to avoid disconnects and mitigate risk in software development projects.
To achieve an iterative, fail-fast workflow, Agile methodologies encouraged embedding customer stakeholders full time with the development team, thereby providing in-house, real-time expertise on customer needs and requirements. In essence, Agile methodologies have created a constant, real-time feedback loop between customer subject matter experts and software development teams. In a previous post, I presented DevOps as an extension of Agile principles. Consistent with this definition, DevOps takes the real-time feedback loop concept and extends it to other points in the software development lifecycle (SDLC), mitigating risks due to disconnects between developers, quality assurance (QA), and operations staff, as well as disconnects between developers and the current state of the software.
A cornerstone of DevOps is continuous integration (CI), a technique designed and named by Grady Booch that continually merges source code updates from all developers on a team into a shared mainline. This continual merging prevents a developer's local copy of a software project from drifting too far afield as new code is added by others, avoiding catastrophic merge conflicts. In practice, CI involves a centralized server that continually pulls in all new source code changes as developers commit them and builds the software application from scratch, notifying the team of any failures in the process. If a failure is seen, the development team is expected to refocus and fix the build before making any additional code changes. While this may seem disruptive, in practice it focuses the development team on a singular stability metric: a working automated build of the software.
Recall that a fundamental component of a DevOps approach is that to remove disconnects in understanding and influence, organizations must embed and fully engage one or more appropriate experts within the development team to enforce a domain-centric perspective. To remove the disconnect between development and sustainment, DevOps practitioners include IT operations professionals in the development team from the beginning as full team members. Likewise, to ensure software quality, QA professionals must be team members throughout the project lifecycle. In other words, DevOps takes the principles of Agile and expands their scope, recognizing that ensuring high quality development requires continual engagement and feedback from a variety of technical experts, including QA and operations specialists.
For example, continuous integration (CI) offers a real-time window into the actual state of the software system and associated quality measurements, allowing immediate and constant engagement of all team members, including operations and QA, throughout the project lifecycle. CI is a form of extreme transparency that makes sure that all project stakeholders can monitor, engage, and positively contribute to the evolving software project without disrupting the team with constant status meetings or refocusing efforts.
Due to their powerful capabilities, CI servers have evolved to perform (and therefore, verify) other important quality metrics automatically, such as running test suites and even automatically deploying applications into test environments after a successful integration. As DevOps practice matures, my expectation is that CI systems and tools will continue to evolve as a central management system for the software development process, as well as testing and integration. One of the research areas my team is exploring is ways to enhance software security by adapting effective security testing and enhancement tools to run efficiently within the constraints of CI, a topic I will explore further in the next installment of our ongoing series on DevOps.
Continuous Integration in DevOps
As I stated in the second post in this series, DevOps, in part, describes techniques for automating repetitive tasks within the software development lifecycle (SDLC), such as software builds, testing, and deployments, allowing these tasks to occur more naturally and frequently throughout the SDLC.
I oversee a software engineering team that works within the SEI's CERT Division that focuses on research and development of solutions to cybersecurity challenges. When developers on my team write code, they test locally and then check the code into a source control repository. We focus on frequent code check-ins, to avoid complex merge problems. After code is checked in, our CI system takes control. It monitors the source code repositories for all projects and pulls an updated version of the code when it detects a new commit. If the project is written in a compiled language (we use many different languages and frameworks regularly), the server compiles and builds the new code. The CI server also runs associated unit test suites for the project. If prior steps succeed, the server runs pre-configured scripts to deploy the application to a testing environment. If any of these processes fails, the CI server fails the build and sends immediate failure notifications to the entire project team. The team's goal is to keep the build passing at all times, so a developer who breaks the build is expected to immediately get it back on track. In this way, the CI server helps to reinforce the habit of thoroughly testing code before committing it, to avoid breaking the build and disrupting the productivity of your team members.
Without this QA process, a developer may check broken code into a central repository. Other developers may make changes that depend on this broken code, or attempt to merge new changes with it. When this happens, the team can lose control of the system's working state, and suffer a loss in momentum when forced to revert changes from numerous developers to return to a functional state.
CI servers (also known as build servers) automatically compile, build, and test every new version of code committed to the central team repository, ensures that the entire team is alerted any time the central code repository contains broken code. This severely limits the chance for catastrophic merge issues and loss of work built upon a broken codebase. In mature operations, the CI server may also automatically deploy the tested application to a quality assurance (QA) or staging environment, ensuring the Agile dream of a consistent working version of software.
All the actions described above are performed based on automated configuration and deployment scripts written collaboratively by development and operations engineers. The collaboration is important--it ensures that operations expertise in deployment needs and best practices is represented in the development process, and that all team members understand these automated scripts and can use and enhance them. This collaboration also sets the stage for use of the same scripts to eventually deploy the system into production environments with high confidence, a process known as continuous deployment, which is a topic for a later post.
As shown in the graphic below, the build server checks out new code from source control, compiles/builds it (if necessary), and tests the code (primarily unit tests, at this stage, though static code analysis is also possible). Once the code is tested, the build server deploys it to QA. At this point, the build server can also launch scripts to perform integration testing, user interface testing, advanced security testing (more on this soon) and other tests requiring a running version of the software. Consistent with Agile requirements that emphasize a continually working version of the software, our CI server automatically reverts to the last successful version of the software, keeping a working QA system available even if integration tests failed.
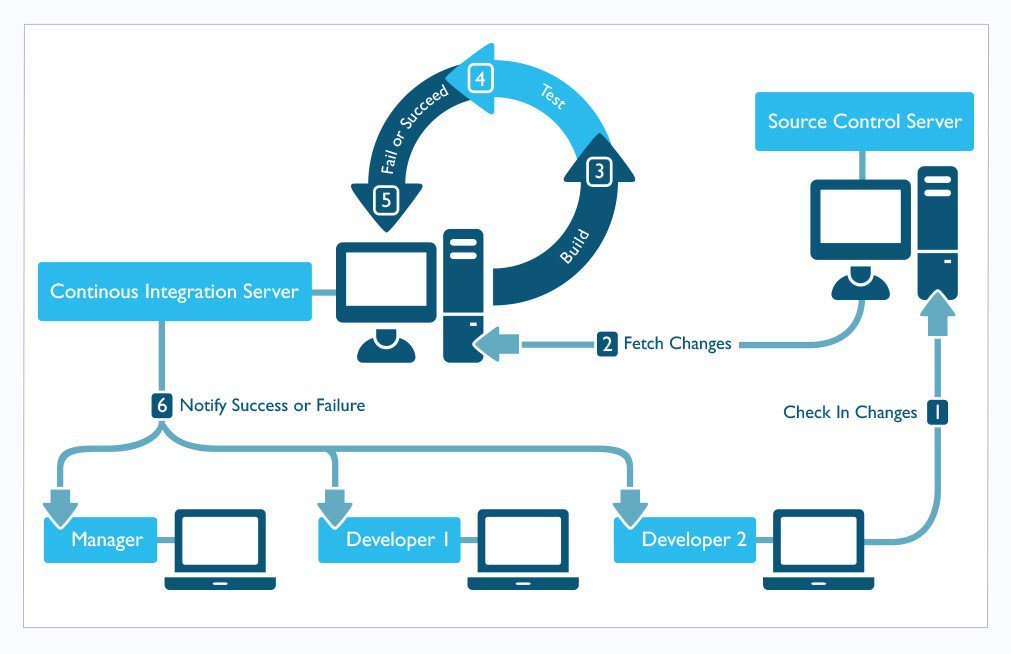
With CI, when developers check in bad code, the system will automatically notify the entire team within minutes. This notification of failure can also be applied to failing functional tests, failing security tests, or failing automated deployment processes, creating an immediate feedback loop to developers to reinforce both software functionality and quality standards. This process helps the team to manage the development of complex, multi-faceted systems without losing sight of defects arising in previously completed features or overall quality. The CI process should be designed to reinforce the quality attributes most important to your system or customer:
- Is security a primary concern? Configure your build server to run a comprehensive suite of security tests and fail the build if vulnerabilities are found.
- Is performance a priority? Configure your build server to run automated performance tests to measure the speed of key operations, and fail the build if they are too slow (even if the operation completed successfully).
Think of continuous integration as your gatekeeper for quality control. Design your failure rules to enforce continual adherence to the quality measures that are most important to your organization and your customers.
Wrapping Up and Looking Ahead
While CI is by no means a new phenomenon, the DevOps movement underscores its importance as a foundational technique for software process automation and enforcement. There are many popular CI systems, including Jenkins, Bamboo, Teamcity, CruiseControl, Team Foundation Server, and others. The variety of systems means that any team should be able to find a tool that both meets its needs and integrates well with the technology stack(s) it employs.
For more information on this and other DevOps-related topics, every Thursday the SEI publishes a new blog post offering guidelines and practical advice to organizations seeking to adopt DevOps in practice. We welcome your feedback on this series, as well as suggestions for future content.
Additional Resources
To listen to the podcast, DevOps--Transform Development and Operations for Fast, Secure Deployments, featuring Gene Kim and Julia Allen, please visit http://url.sei.cmu.edu/js.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed