Polar: Improving DevSecOps Observability


For organizations that produce software, modern DevSecOps processes create a wealth of data used for improving the creation of tools, increasing infrastructure robustness, and saving money on operational costs. Currently this vast amount of data produced by DevSecOps implementation is collected using traditional batch data processing, a technique that limits an organization’s ability to gather and comprehend the full picture provided by these processes. Without visibility into the totality of data, an organization’s capability to both quickly and effectively streamline decision making fails to reach its full potential.
In this post, we introduce Polar, a DevSecOps framework developed as a solution to the limitations of traditional batch data processing. Polar gives visibility into the current state of an organization’s DevSecOps infrastructure, allowing for all of the data to be engaged for informed decision making. The Polar framework will quickly become a software industry necessity by providing organizations with the ability to immediately gain infrastructure insights from querying.
A Detailed System Overview
Polar’s architecture is designed to efficiently manage and leverage complex data within a mission context. It is built on several core components, each integral to processing, analyzing, and visualizing data in real time. Below is a simplified yet comprehensive description of these components, highlighting their technical workings and direct mission implications.
Architecture View
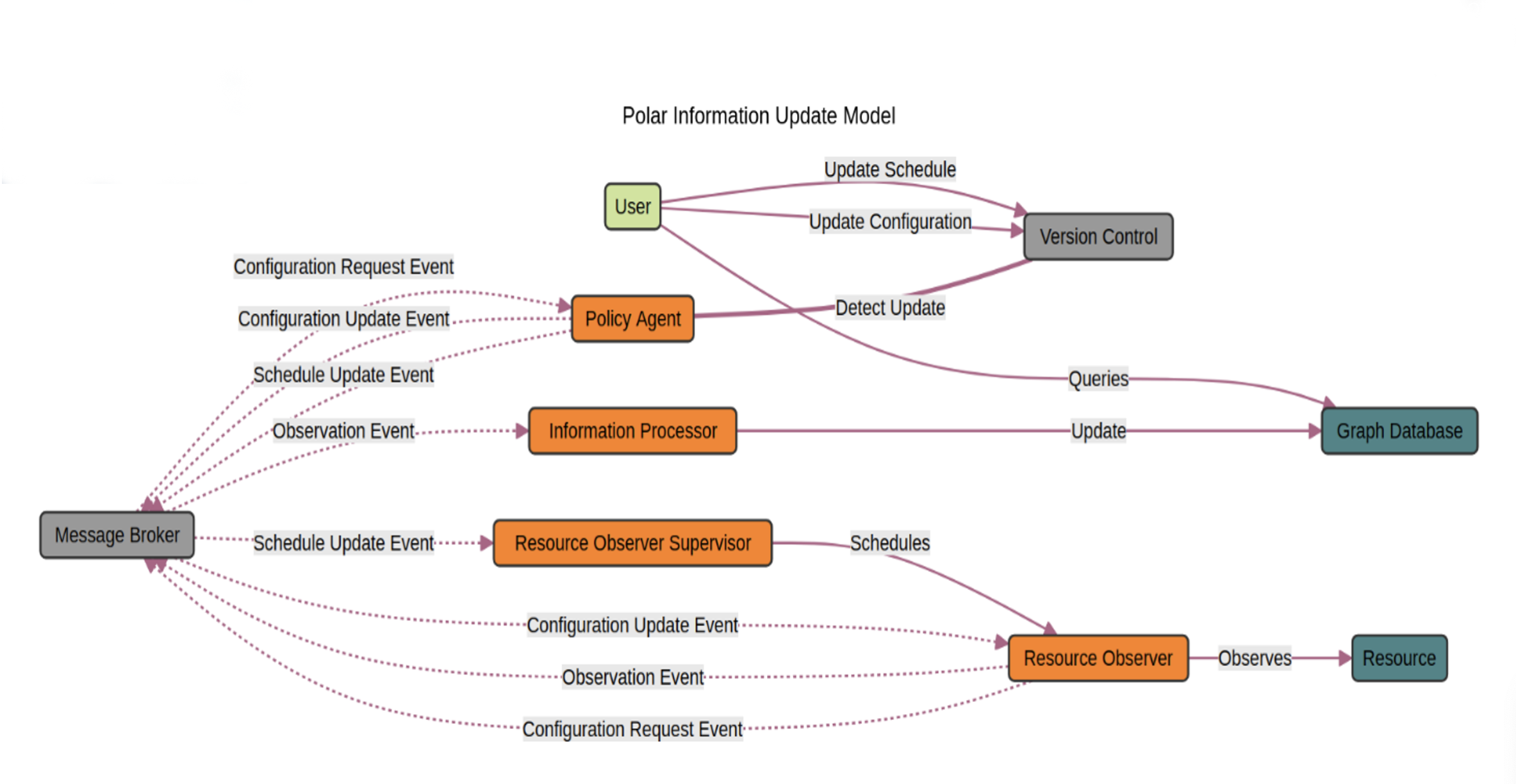
Graph Database
At the core of the architecture is the graph database, which is responsible for storing and managing data as interconnected nodes and relationships. This allows us to model the data in a natural way that is more clearly aligned to intuitive data query and analysis by organizations than is possible with traditional relational databases. The use of a typical graph database implementation also means that the schema is dynamic and can be changed at any time without requiring data migration. The current implementation uses Neo4J due to its robust transactional support and powerful querying capabilities through Cypher, its query language. Plans to support ArangoDB are in the works.
Participants and Their Roles
Additionally, the Polar architecture is built around several key participants, each designed to fulfill specific functions within the system. These participants seamlessly interact to collect, process, and manage data, turning them into actionable insights.
Observers
Observers are specialized components tasked with monitoring specific resources or environments. They are deployed across various parts of the business infrastructure to continuously gather data. Depending on their configuration, Observers can track anything from real-time performance metrics in IT systems to user interactions on a digital platform. Each Observer is programmed to detect changes, events, or conditions defined as relevant. These can include changes in system status, performance thresholds being exceeded, or specific user actions. Once detected, these Observers raise events that encapsulate the observed data. Observers help optimize operational processes by providing real-time data on system performance and functionality. This data is crucial for identifying bottlenecks, predicting system failures, and streamlining workflows. Observers can track user behavior, providing insight into preferences and usage patterns. This information is vital for improving user interfaces, customizing user experiences, and improving application satisfaction.
Information Processors
Information Processors, formerly Resource Observer Consumers, are responsible for receiving events from Observers and transforming the captured data into a format suitable for integration into the knowledge graph. They act as a bridge between the raw data collected by Observers and the structured data stored in the graph database. Upon receiving data, these processors use predefined algorithms and models to analyze and structure the data. They determine the relevance of the data, map it to the appropriate nodes and edges in the graph, and update the database accordingly.
Policy Agents
Policy Agents enforce predefined rules and policies within the architecture to ensure data integrity and compliance with both internal standards and external regulations. They monitor the system to ensure that all components operate within set parameters and that all data management practices adhere to compliance requirements. Policy Agents use a set of criteria to automatically apply rules across the data processing workflow. This includes validating policy inputs and ensuring that the correct parts of the system receive and apply the latest configurations. By automating compliance checks, Policy Agents ensure that the correct data is being collected and in a timely manner. This automation is crucial in highly regulated environments where once a policy is decided, it must be enforced. Continuous monitoring and automatic logging of all actions and data changes by Policy Agents ensure that the system is always audit-ready, with comprehensive records available to demonstrate compliance.
Pub/Sub Messaging System
A publish-subscribe (pub/sub) messaging system acts as the backbone for real-time data communication within the architecture. This system allows different components of the architecture, such as Resource Observers and Information Processors, to communicate asynchronously. Decoupling Observers from Processors ensures that any component can publish data without any knowledge or concern for how it will be used. This setup not only enhances the scalability but also improves the tolerance of faults, security, and management of data flow.
The current implementation utilizes RabbitMQ. We had considered using Redis pub/sub, because our system only requires basic pub/sub capabilities, but we had difficulty due to the immaturity of the libraries used by Redis for Rust supporting mutual TLS. This is the nature of active development, and situations change frequently. This is obviously not a problem with Redis but with supporting libraries for Redis in Rust and the quality of dependencies. The interactions played a bigger role in our decision to utilize RabbitMQ.
Configuration Management
Configuration management is handled using a version control repository. Our preference is to use a private GitLab server, which stores all configuration policies and scripts needed to manage the deployment and operation of the system; however, the choice of distributed version control implementation is not important to the architecture. This approach leverages Git's version control capabilities to maintain a history of changes, ensuring that any modifications to the system's configuration are tracked and reversible. This setup supports a GitOps workflow, allowing for continuous integration and deployment (CI/CD) practices that keep the system configuration in sync with the codebase that defines it. Specifically, a user of the system, possibly an admin, can create and update plans for the Resource Observers. The idea is that a change to YAML or in version control can trigger an update to the observation plan for a given Resource Observer. Updates might include a change in observation frequency and/or changes in what is collected. The ability to control policy through a version-controlled configuration fits well within modern DevSecOps principles.
The integration of these components creates a dynamic environment in which data is not just stored but actively processed and used for real-time decision making. The graph database provides a flexible and powerful platform for querying complex relationships quickly and efficiently, which is crucial for decision makers who need to make swift decisions based on a wide amount of interconnected data.
Security and Compliance
Security and compliance are primary concerns in the Polar architecture as a cornerstone for building and maintaining trust when operating in highly regulated environments. Our approach combines modern security protocols, strict separation of concerns, and the strategic use of Rust as the implementation language for all custom components. The choice to use Rust helps to meet several of our assurance goals.
Using Polar in Your Environment
Guidelines for Deployment
The deployment, scalability, and integration of the Polar architecture are designed to be smooth and efficient, ensuring that missions can leverage the full potential of the system with minimal disruption to existing processes. This section outlines practical guidelines for deployment, discusses scalability options, and explains how the architecture integrates with various IT systems.
The architecture is designed with modularity at its core, allowing components, such as Observers, Information Processors, and Policy Agents, to be deployed independently based on specific business needs. This modular approach not only simplifies the deployment process but also helps isolate and resolve issues without impacting the entire system.
The deployment process can be automated for any given environment through scripts and configurations stored in version control and applied using common DevSecOps orchestration tools, such as Docker and Kubernetes. This automation supports consistent deployments across different environments and reduces the potential for human error during setup. Automated and modular deployment allows organizations to quickly set up and test different parts of the system without major overhauls, reducing the time to value. The ability to deploy components independently provides flexibility to start small and scale or adapt the system as needs evolve. In fact, starting small is the best way to begin with the framework. To begin observing, chose an area that would provide immediately useful insights. Combine these with additional data as they become available.
Integration with Existing Infrastructures
The architecture uses existing service APIs for networked services in the deployed environment to query information about that system. This approach is considered as minimally invasive to other services as possible. An alternative approach that has been taken in other frameworks that provide similar functionality is to deploy active agents adjacent to the services they are inspecting. These agents can operate, in many cases, transparently to the services they are observing. The tradeoff is that they require higher privilege levels and access to information, and their operations are not as easily audited. APIs generally allow for secure and efficient exchange of data between systems, enabling the architecture to augment and enhance current IT solutions, without compromising security.
Some Observers are provided and can be used with minimal configuration, such as the GitLab Observer. However, to maximize the use of the framework, it is expected that additional Observers will need to be created. The hope is that eventually, we will have a repository of Observers that fit the needs of most users.
Schema Development
The success of a knowledge graph architecture significantly depends on how well it represents the processes and specific data landscape of an organization. Developing custom, organization-specific schemas is a critical step in this process. These schemas define how data is structured, related, and interpreted within the knowledge graph, effectively modeling the unique aspects of how an organization views and uses its information assets.
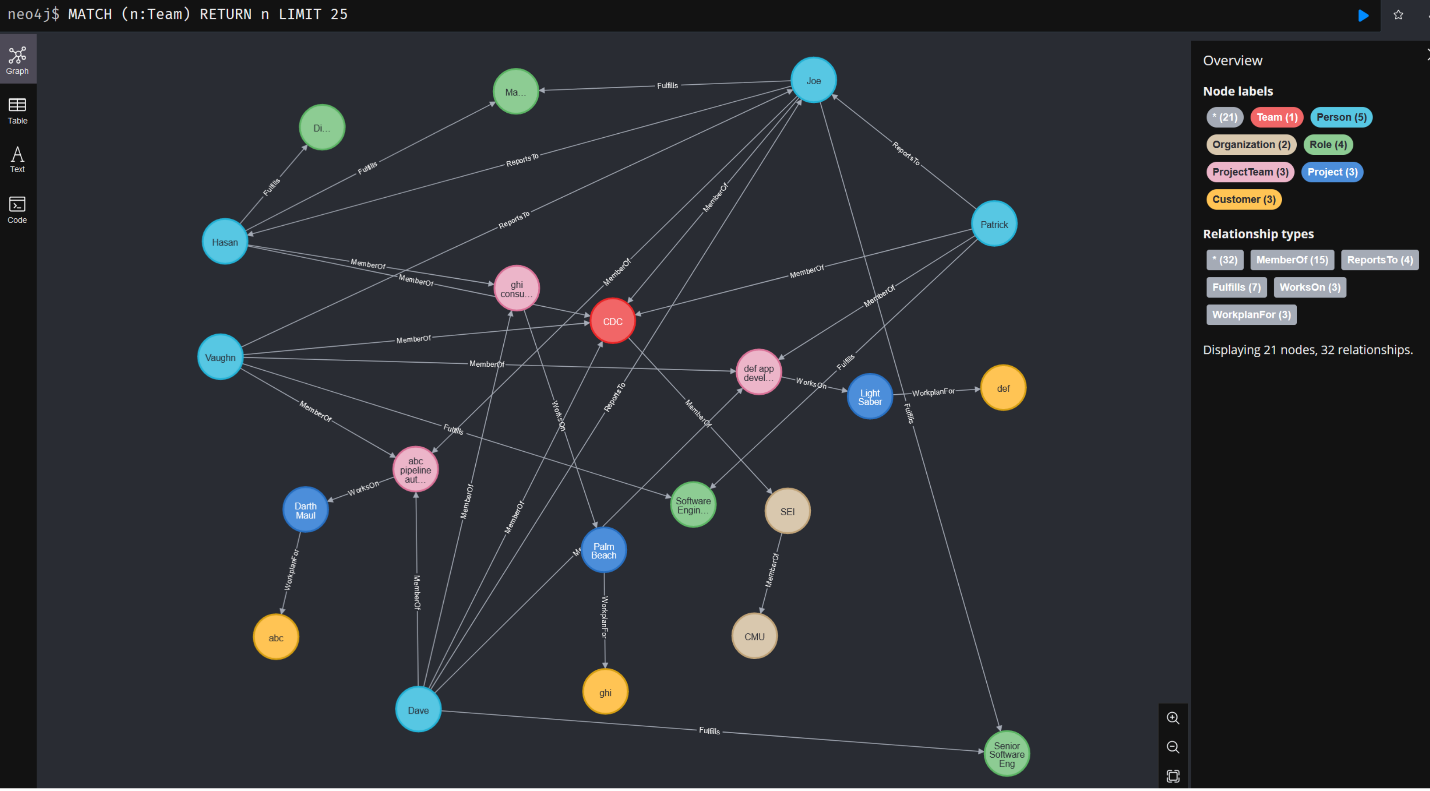
Custom schemas allow data modeling in ways that closely align with an organization’s operational, analytical, and strategic needs. This tailored approach ensures that the knowledge graph reflects the real-world relationships and processes of the business, enhancing the relevance and utility of the insights it generates. A well-designed schema facilitates the integration of disparate data sources, whether internal or external, by providing a consistent framework that defines how data from different sources are related and stored. This consistency is crucial to maintain the integrity and accuracy of the data within the knowledge graph.
Data Interpretation
In addition to schema development by the Information Architect, there are pre-existing models for how to think about your data. For example, the SEI’s DevSecOps Platform Independent Model can also be used to begin creating a schema to organize information about a DevSecOps organization. We have used it with Polar in customer engagements.
Data Transformation in the Digital Age
The development and deployment of the Polar architecture represents a significant advancement in the way organizations handle and derive value from their data produced by the implementation of DevSecOps processes. In this post we have explored the intricate details of the architecture, demonstrating not only its technical capabilities, but also its potential for profound impact on operations incorporating DevSecOps into their organizations. The Polar architecture is not just a technological solution, but a strategic tool that can become the industry standard for organizations looking to thrive in the digital age. Using this architecture, highly regulated organizations can transform their data into a dynamic resource that drives innovation and can become a competitive advantage.
Additional Resources
To download Polar visit the Carnegie Mellon Software Engineering Institute’s Github site.
Written By



More By The Authors
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed