Actionable Data from the DevSecOps Pipeline


As the Special Operations Command (SOCOM) commander, you are told that intelligence has discovered that an adversary has unexpected capabilities. Therefore, you need to reprioritize capabilities. You inform the program manager (PM) for your advanced aircraft platform that the lower priority capability for the whiz-bang software for sensor fusion that was on the roadmap 18 months from now will need to become the top priority and be delivered in the next six months. But the next two priorities are still important and are needed as close to the original dates (three months and nine months out) as possible.
You need to know
- What options to provide the new capability and the next two priority capabilities (with reduced capability) can be provided without a change in staffing?
- How many more teams would need to be added to get the sensor-fusion software in the next six months and to stay on schedule for the other two capabilities? And what is the cost?
In this blog post, excerpted and adapted from a recently published white paper, we explore the decisions that PMs make and information they need to confidently make decisions like these with the help of data that is available from DevSecOps pipelines.
As in commercial companies, DoD PMs are accountable for the overall cost, schedule, and performance of a program. Nonetheless, the DoD PM operates in a different environment, serving military and political stakeholders, using government funding, and making decisions within a complex set of procurement regulations, congressional approval, and government oversight. They exercise leadership, decision-making, and oversight throughout a program and a system’s lifecycle. They must be the leaders of the program, understand requirements, balance constraints, manage contractors, build support, and use basic management skills. The PM’s job is even more complex in large programs with multiple software-development pipelines where cost, schedule, performance, and risk for the products of each pipeline must be considered when making decisions, as well as the interrelationships among products developed on different pipelines.
The goal of the SEI research project called Automated Cost Estimation in a Pipeline of Pipelines (ACE/PoPs) is to show PMs how to collect and transform unprocessed DevSecOps development data into useful program-management information that can guide decisions they must make during program execution. The ability to continuously monitor, analyze, and provide actionable data to the PM from tools in multiple interconnected pipelines of pipelines (PoPs) can help keep the overall program on track.
What Data Do Program Managers Need?
PMs are required to make decisions almost continuously over the course of program execution. There are many different areas where the PM needs objective data to make the best decision possible at the time. These data fall into the main categories of cost, schedule, performance, and risk. However, these categories, and many PM decisions, are also impacted by other areas of concern, including staffing, process effectiveness, program stability, and the quality and data provided by program documentation. It is important to recognize how these data are related to each other, as shown in Figure 1.
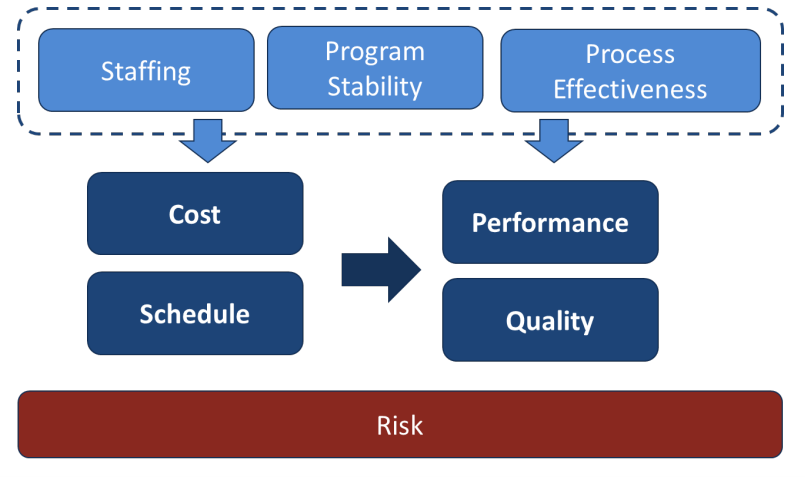
All PMs track cost and schedule, but changes in staffing, program stability, and process effectiveness can drive changes to both cost and schedule. If cost and schedule are held constant, these changes will manifest in the end product’s performance or quality. Risks can be found in every category. Managing risks requires collecting data to quantify both the probability of occurrence and impact of each risk if it occurs.
In the following subsections, we describe these categories of PM concerns and suggest ways in which metrics generated by DevSecOps tools and processes can help provide the PM with actionable data within these categories. For a more detailed treatment of these topics, please read our white paper.
Cost
Cost is typically one of the largest drivers of decisions for a PM. Cost charged by the contractor(s) on a program has many facets, including costs for management, engineering, production, testing, documentation, etc. This blog post focuses on providing metrics for one aspect of cost: software development.
For software-development projects, labor is usually the single most significant contributor to cost, including costs for software architecture, modeling, design, development, security, integration, testing, documentation, and release. For DoD PMs, the need for accurate cost data is exacerbated by the requirement to plan budgets five years in advance and to update budget numbers annually. It is therefore critical for PMs to have quality metrics so they can better understand overall software-development costs and help estimate future costs.
The DevSecOps pipeline provides data that can help PMs make decisions regarding cost. While the pipeline typically doesn’t directly provide information on dollars spent, it can feed typical earned value management (EVM) systems and can provide EVM-like data even if there is no requirement for EVM. Cost is most evident from work applied to specific work items, which in turn requires information on staffing and the activities performed. For software developed using Agile processes in a DevSecOps environment, measures available through the pipeline can provide data on team size, actual labor hours, and the specific work planned and completed. Although clearly not the same as cost, tracking labor charges (hours worked) and full-time equivalents (FTEs) can provide an indication of cost performance. At the team level, the DevSecOps cadence of planning increments and sprints provides labor hours, and labor hours scale linearly with cost.
A PM can use metrics on work completed vs. planned to make informed decisions about potential cost overruns for a capability or feature. These metrics can also help a PM prioritize work and decide whether to continue work in specific areas or move funding to other capabilities. The work can be measured in estimated/actual cost, and optionally an estimated/actual size can be measured. The predicted cost of work planned vs. actual cost of work delivered measures predictability. The DevSecOps pipeline provides several direct measurements, including the actual work items taken through development and production, and the time they enter the DevSecOps pipeline, as they are built and as they are deployed. These measurements lead us to schedule data.
Schedule
The PM needs accurate information to make decisions that depend on delivery timelines. Schedule changes can affect the delivery of capability in the field. Schedule is also important when considering funding availability, need for test assets, commitments to interfacing programs, and many other aspects of the program. On programs with multiple software pipelines, it is important to understand not only the technical dependencies, but also the lead and lag times between inter-pipeline capabilities and rework. Schedule metrics available from the DevSecOps pipeline can help the PM make decisions based on how software-development and testing activities on multiple pipelines are progressing.
The DevSecOps pipeline can provide progress against plan at several different levels. The most important level for the PM is the schedule related to delivering capability to the users. The pipeline typically tracks stories and features, but with links to a work-breakdown structure (WBS), features can be aggregated to show progress vs. the plan for capability delivery as well. This traceability does not naturally occur, however, nor will the metrics if not adequately planned and instantiated. Program work must be prioritized, the effort estimated, and a nominal schedule derived from the available staff and teams. The granularity of tracking should be small enough to detect schedule slips but large enough to avoid excessive plan churn as work is reprioritized.
The schedule will be more accurate on a short-term scale, and the plans must be updated whenever priorities change. In Agile development, one of the main metrics to look for with respect to schedule is predictability. Is the developer working to a repeatable cadence and delivering what was promised when expected? The PM needs credible ranges for program schedule, cost, and performance. Measures that inform predictability, such as effort bias and variation of estimates versus actuals, throughput, and lead times, can be obtained from the pipeline. Although the seventh principle of the Agile Manifesto states that working software is the primary measure of progress, it is important to distinguish between indicators of progress (i.e., interim deliverables) and actual progress.
Story points can be a leading indicator. As a program populates a burn-up or burndown chart showing completed story points, this indicates that work is being completed. It provides a leading indication of future software production. However, work performed to complete individual stories or sprints is not guaranteed to generate working software. From the PM perspective, only completed software products that satisfy all conditions for done are true measures of progress (i.e., working software).
A common problem in the multi-pipeline scenario—especially across organizational boundaries—is the achievement of coordination events (milestones). Programs should not only independently monitor the schedule performance of each pipeline to determine that work is progressing toward key milestones (usually requiring integration of outputs from multiple pipelines), but also verify that the work is truly complete.
In addition to tracking the schedule for the operational software, the DevSecOps tools can provide metrics for related software activities. Software for support items such as trainers, program-specific support equipment, data analysis, etc., can be vital to the program’s overall success. The software for all the system components should be developed in the DevSecOps environment so their progress can be tracked and any dependencies recognized, thereby providing a clearer schedule for the program as a whole.
In the DoD, understanding when capabilities will be completed can be critical for scheduling follow-on activities such as operational testing and certification. In addition, systems often must interface to other systems in development, and understanding schedule constraints is important. Using data from the DevSecOps pipeline allows DoD PMs to better estimate when the capabilities under development will be ready for testing, certification, integration, and fielding.
Performance
Functional performance is critical in making decisions regarding the priority of capabilities and features in an Agile environment. Understanding the required level of performance of the software being developed can allow informed decisions on what capabilities to continue developing and which to reassess. The concept of fail fast can’t be successful unless you have metrics to quickly inform the PM (and the team) when an idea leads to a technical dead end.
A necessary condition for a capability delivery is that all work items required for that capability have been deployed through the pipeline. Delivery alone, however, is insufficient to consider a capability complete. A complete capability must also satisfy the specified requirements and satisfy the needs in the intended environment. The development pipeline can provide early indicators for technical performance. Technical performance is normally validated by the customer. Nonetheless, technical performance includes indicators that can be measured through metrics available in the DevSecOps pipeline.
Test results can be collected using modeling and simulation runs or through various levels of testing within the pipeline. If automated testing has been implemented, tests can be run with every build. With multiple pipelines, these results can be aggregated to give decision makers insight into test-passage rates at different levels of testing.
A second way to measure technical performance is to ask users for feedback after sprint demos and end-of-increment demos. Feedback from these demos can provide valuable information about the system performance and its ability to meet user needs and expectations.
A third way to measure technical performance is through specialized testing in the pipeline. Stress testing that evaluates requirements for key performance parameters, such as total number of users, response time with maximum users, and so forth, can help predict system capability when deployed.
Quality
Poor-quality software can affect both performance and long-term maintenance of the software. In addition to functionality, there are many quality attributes to consider based on the domain and requirements of the software. Additional performance factors become more prominent in a pipeline-of-pipelines environment. Interoperability, agility, modularity, and compliance with interface specifications are a few of the most obvious ones.
The program must be satisfied that the development uses effective methods, issues are identified and remediated, and the delivered product has sufficient quality for not just the primary delivering pipeline but for all upstream pipelines as well. Before completion, individual stories must pass through a DevSecOps toolchain that includes several automated activities. In addition, the overall workflow includes tasks, design, and reviews that can be tracked and measured for the entire PoP.
Categorizing work items is important to account for, not only for work that builds features and capability, but also work that is often considered overhead or support. Mik Kersten uses feature, bug, risk item, and technical debt. We would add adaptation.
The work type balance can provide a leading measure of program health. Each work item is given a work type category, an estimated cost, and an actual cost. For the completed work items, the portion of work in each category can be compared to plans and baselines. Variance from the plan or unexpected drift in one of the measures can indicate a problem that should be investigated. For example, an increase in bug work suggests quality problems while an increase in technical-debt issues can signal design or architectural deficiencies that are not addressed.
Typically, a DevSecOps environment includes one or more code-analysis applications that automatically run daily or with every code commit. These analyzers output weaknesses that were discovered. Timestamps from analysis execution and code commits can be used to infer the time delay that was introduced to address the issues. Issue density, using physical size, functional size, or production effort can provide a first-level assessment of the overall quality of the code. Large lead times for this stage indicate a high cost of quality. A static scanner can also identify issues with design changes in cyclomatic or interface complexity and may predict technical debt. For a PoP, analyzing the upstream and downstream results across pipelines can provide insight as to how effective quality programs are on the final product.
Automated builds support another indicator of quality. Build issues usually involve inconsistent interfaces, obsolete libraries, or other global inconsistencies. Lead time for builds and number of failed builds indicate quality failures and may predict future quality issues. By using the duration of a zero-defect build time as a baseline, the build lead time provides a way to measure the build rework.
For PoPs, build time following integration of upstream content directly measures how well the individual pipelines collaborated. Test capabilities within the DevSecOps environment also provide insight into overall code quality. Defects found during testing versus after deployment can help evaluate the overall quality of the code and the development and testing processes.
Risk
Risks generally threaten cost, schedule, performance, or quality. The PM needs information to assess the probability and impact of the risks if not managed and possible mitigations (including the cost of the mitigations and reduction in risk consequence) for each possible course of action. The risks involved in software development can result from inadequacy of the technical solution, supply-chain issues, obsolescence, software vulnerabilities, and issues with the DevSecOps environment and overall staffing.
Risk results from uncertainty and includes potential threats to the product capability and operational issues such as cyberattack, delivery schedule, and cost. The program must ensure that risks have been identified, quantified, and, as appropriate, tracked until mitigated. For the purposes of the PM, risk exposures and mitigations should be quantified in terms of cost, schedule, and technical performance.
Risk mitigations should also be prioritized, included among the work items, and scheduled. Effort applied to burning down risk is not available for development, so risk burndown must be explicitly planned and tracked. The PM should monitor the risk burndown and cost ratios of risk to the overall period costs. Two separate burndowns should be monitored: the cost and the value (exposure). The cost assures that risk mitigations have been adequately funded and executed. The value burndown indicates actual reduction in risk level.
Development teams may assign specific risks to capabilities or features. Development-team risks are usually discussed during increment planning. Risk mitigations added to the work items should be identified as risk and the totals should be included in reports to the PM.
Other Areas of Concern to the Program Manager
In addition to the traditional PM responsibilities of making decisions related to cost, schedule, performance, and risk, the PM must also consider additional contributing factors when making program decisions, especially with respect to software development. Each of these factors can affect cost, schedule, and performance.
- Organization/staffing—PMs need to understand the organization/staffing for both their own program management office (PMO) team and the contractor’s team (including any subcontractors or government personnel on those teams). Obtaining this understanding is especially important in an Agile or Lean development. The PMO and users need to provide subject-matter experts to the developing organization to ensure that the development is meeting the users’ needs and expectations. Users can include operators, maintainers, trainers, and others. The PMO also needs to involve appropriate staff with specific skills in Agile events and to review the artifacts developed.
- Processes—For multi-pipeline programs, process inconsistencies (e.g., definition of done) and differences in the contents of software deliverables can create massive integration issues. It is important for a PM to ensure that PMO, contractor, and supplier processes are defined and repeatably executed. In single pipelines, all program partners must understand the processes and practices of the upstream and downstream DevSecOps activities, including coding practices and standards and the pipeline tooling environments. For multi-pipeline programs, process inconsistencies and differences in the contents of software deliverables can create massive integration issues, with both cost and schedule impacts.
- Stability—In addition to tracking metrics for items like staffing, cost, schedule, and quality, a PM also needs to know if these areas are stable. Even if some metrics are positive (for example, the program is below cost), trends or volatility can point to possible issues in the future if there are wide swings in the data that are not explained by program circumstances. In addition, stability in requirements and long-term feature prioritization could also be important to track. While agility encourages changes in priorities, the PM needs to understand the costs and risks incurred. Moreover, the Agile principle to fail fast can increase the rate of learning the software’s strengths and weaknesses. These are a normal part of Agile development, but the overall stability of the Agile process must be understood by the PM.
- Documentation—The DoD requirement for documentation of acquisition programs creates a PM challenge to balance the Agile practice of avoiding non-value-added documentation. It is important to capture necessary design, architecture, coding, integration, and testing knowledge in a manner that is useful to engineering staff responsible for software sustainment while also meeting DoD documentation requirements.
Creating Dashboards from Pipelines to Identify Risks
Although the amount of data available from multiple pipelines can get overwhelming, there are tools available for use within pipelines that will aggregate data and create a dashboard of the available metrics. Pipelines can generate several different dashboards for use by developers, testers, and PMs. The key to developing a useful dashboard is to select appropriate metrics to make decisions, tailored to the needs of the specific program at various times across the lifecycle. The dashboard should change to highlight metrics related to those changing facets of program needs.
It takes time and effort to determine what risks will drive decisions and what metrics could inform those decisions. With instrumented DevSecOps pipelines, those metrics are more readily available, and many can be provided in real time without the need to wait for a monthly metrics report. Instrumentation can help the PM to make decisions based on timely data, especially in large, complex programs with multiple pipelines.
Additional Resources
Read the SEI white paper by Julie Cohen and Bill Nichols, Program Managers—The DevSecOps Pipeline Can Provide Actionable Data.
Read the SEI blog post by Bill Nichols, The Current State of DevSecOps Metrics.
Read other SEI blog posts about DevSecOps.
Read other SEI blog posts about Agile.
Read other SEI blog posts about measurement and evaluation.
Read the SEI blog post by Will Hayes, Patrick Place, and Keith Korzec, Agile Metrics: Assessing Progress to Plans.
Learn more about the SEI Automated Cost Estimation in a Pipeline of Pipelines (ACE/PoPs) research project.
Written By


More By The Authors
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed