Migrating Applications to Kubernetes

Kubernetes is a popular, cloud-native container orchestration system. Adoption of Kubernetes in production environments has rapidly increased over the last several years. As Kubernetes adoption increases, there is often pressure to migrate applications that are currently deployed via other means onto Kubernetes. Performing an effective migration of these applications to Kubernetes may help organizations adopt DevOps practices, and it will allow organizations to unify their operations onto a single set of cloud tooling and expertise.
However, cloud-native software architectures are different from traditional architectures in a variety of ways. As a result, migration of a system into a cloud-native environment is not as simple as a rehosting migration. This post introduces a generic process that provides a useful set of questions to ask when planning a Kubernetes migration. The answers to the questions can then be used to make informed choices about how to use the various deployment options available within Kubernetes.
Understand the Goal
A full understanding of the goals of the migration is absolutely key to a success. First, determine whether the application should be modified to support the behavior of the environment, or whether the environment should be modified to support the behavior of the application. Modifying an application that is not currently cloud native to take advantage of the benefits of cloud-native design may require extensive rework. However, it is often possible to avoid this rework, at least at first, and work around the problems with a design that is not cloud-aware.
Here are some questions that should be asked before starting the migration:
- Why is the application being migrated?
- Can the behavior of the application be modified? An application that cannot be modified is often fairly easy to migrate; however, it may not reap any real benefit from Kubernetes.
Gather Information about the Application
The next step is to understand the scope of what needs to be migrated. What components make up the application being migrated? Is it a single service or a collection of services that work together?
After the scope is determined, the remainder of the information gathering is to gain a complete understanding of the interfaces of the application's components. The following steps should be completed for each component of the application independently.
Determine Network Interactions
The network is by far the most common interface in modern applications. Consider both the outbound connections that the application initiates and the inbound connections that are initiated by other applications. These interfaces must be preserved during a migration so that applications and users are unaware that the migration has even taken place.
1. What must the service connect to in order to function?
Make sure to record the URL or IP, the port, and the location of the resource within or outside the cluster. See Table 1 for an example for how this information could be recorded, along with some example data.

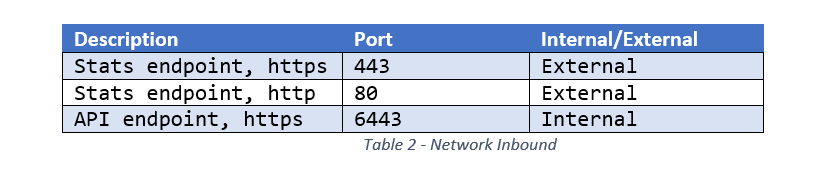
2. What services or users need access to the service?
Make sure to record the port and location of the remote user/service inside the cluster, outside the cluster, or both. See Table 2 for an example of how this information could be recorded, along with some example data.
Determine Filesystem Interactions
Modern applications use filesystems for storage of configuration, static data, and dynamic data. Historically, filesystems were also used as a mechanism for communication between applications and components. Although this practice has largely been replaced by network-based interaction, it is still present in some domains and in legacy applications. Filesystem interactions should be noted, however, because they are very important to the migration.
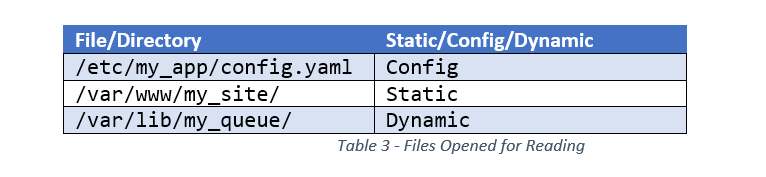
1. What files and directories are read by the service?
For each file or directory, determine whether the content is static, configuration, or dynamic (i.e., modified at runtime). See Table 3 for an example of how this information could be recorded, along with some example data.
2. What files are modified by the service?
Make sure to record whether the modifications must survive service restarts (i.e., be persistent) or if they can be transient. Also record whether the changes must be visible to other applications or executables, or only be visible to the service instance itself. See Table 4 for an example of how this information could be recorded, along with some example data.

Use the Data to Plan the Migration
Gathering the data in the previous section requires a deep understanding of the application being migrated. This deep understanding of the application should now be used to reflect upon the goals of the migration and reaffirm the desire to migrate. For some applications it is possible that a migration will not provide significant value without extensive refactoring of the application.
If proceeding with the migration is still deemed valuable, the actual migration involves two steps:
- Containerization of the processes that make up the application.
- Selecting the Kubernetes objects that will make up the components of the application in the new environment.
Although Step 1 above is necessary, it is not specific to Kubernetes and is already quite well described in various articles and courses. To proceed with step 2, here are some questions to help determine which Kubernetes objects are needed for the migration:
1. What controller should be used to manage the Pods?
Kubernetes has several built-in controllers for managing Pods, and each exhibits slightly different behavior.
- Deployment -- The most common controller, it will work to ensure that the number of existing Pod replicas is the specified number. The name of each Pod is randomly generated and will not be consistent if Pods are restarted.
- DaemonSet -- Like a deployment, except the Pod will be started once on every node.
- StatefulSet -- Like a deployment, except the name of each Pod is sequential from 0, unique, and sticky. If a Pod is rescheduled to a different node, its name will remain the same when it is restarted.
2. How will persistent storage be achieved?
If persistent storage is required for the application, then first consider the use of cloud-native storage options in your environment (e.g., S3 in Amazon Web Services or Blob in Microsoft Azure). However, doing so will require changes to the application to support the use of these systems instead of the filesystem.
If it is not feasible to change the application, then a PersistentVolume is the way to go. If possible in your environment, a LocalPersistentVolume is a good last-resort option if performance of network-attached storage is not sufficient.
3. How should configuration be injected?
Configuration should be injected into the Pods via a ConfigMap. However, data such as passwords and keys should be injected via a Secret instead.
4. How should static files, such as certificates, be managed?
Static data should be compiled into the Docker image that makes up the Pods. Alternatively, it could be treated the same as persistent storage and loaded once, before deployment.
5. How should communication between components via filesystems be handled?
A PersistentVolume can usually be created with the necessary access permissions and mounted into the Pods that need to communicate. However, the PersistentVolume implementation that is used for a volume impacts whether that volume can be used by multiple readers or writers simultaneously. It is therefore possible that the Kubernetes environment being used does not support any networked implementations with the read/write behavior required.
The best way to solve this problem is to avoid it by restructuring the application to use network-based communication mechanisms. If restructuring the application is not possible (or not desirable) due to business constraints, then the processes that are communicating must be placed in the same Pod and communicate via an emptyDir volume.
6. How will log data be read from Pods?
Kubernetes expects all Pods to log everything worth logging to STDOUT and STDERR. If the application does not support the ability to modify logging options, then a sidecar container (e.g., fluentd or logstash) can be used to read logs from a shared volume and transfer them into a log aggregation system.
7. Does the Kubernetes environment support network policy?
If the Kubernetes environment supports network policy, then the host and port information gathered should be used to create a NetworkPolicy object.
Wrapping Up
Kubernetes helps organizations achieve their DevOps goals and streamlines operations. However, some applications require a great deal of effort to migrate. Establishing the goals of the migration and gathering relevant data allow for design trade-offs to consider before modifying the application or starting the migration process. The series of questions presented above helps to gather information about the application relevant to migration. The information gathered then makes the migration straightforward by determining how to represent the application in Kubernetes.
Additional Resources
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed