A Technical DevSecOps Adoption Framework


DevSecOps practices, including continuous-integration/continuous-delivery (CI/CD) pipelines, enable organizations to respond to security and reliability events quickly and efficiently and to produce resilient and secure software on a predictable schedule and budget. Despite growing evidence and recognition of the efficacy and value of these practices, the initial implementation and ongoing improvement of the methodology can be challenging. This blog post describes our new DevSecOps adoption framework that guides you and your organization in the planning and implementation of a roadmap to functional CI/CD pipeline capabilities. We also provide insight into the nuanced differences between an infrastructure team focused on implementing a DevSecOps paradigm and a software-development team.
A previous post presented our case for the value of CI/CD pipeline capabilities and we introduced our framework at a high level, outlining how it helps set priorities during initial deployment of a development environment capable of executing CI/CD pipelines and leveraging DevSecOps practices. Figure 1 below depicts the DevSecOps ecosystem, with the full integration of all components of a CI/CD pipeline involving stakeholders from multiple departments or groups.
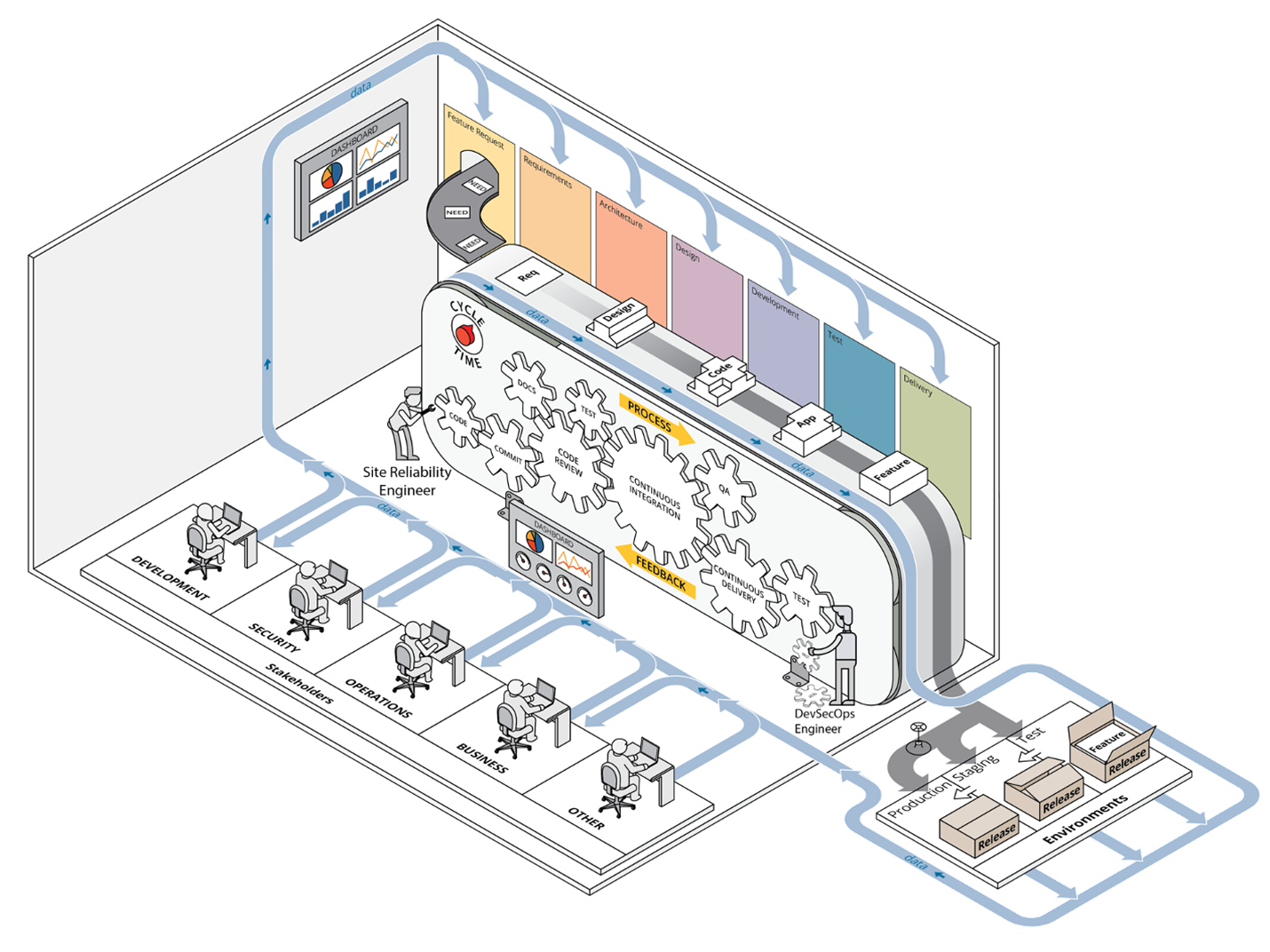
Our framework builds on derived principles of DevSecOps, such as automation by the inclusion of configuration management and infrastructure as code, collaboration, and monitoring. It provides guidance for applying these DevSecOps principles to infrastructure operations in a computing environment by providing an ordered approach toward implementing critical practices in the stages of adoption, implementation, improvement, and maintenance of that environment. Our framework also leverages automation throughout the process and is specifically targeted at the development and operations teams, sometimes referred to as site-reliability engineers, who are charged with managing the computing environment in use by software-development teams.
The practices we outline are based on the actual experiences of SEI staff members supporting on-premises development environments tailored to the missions of the sponsoring organizations. Our framework applies whether your infrastructure is running on-premises in a physical or virtual environment or leveraging commercially available cloud services.
The Framework in Detail
The stages of our framework, shown in Figure 2, are
0. building the foundation
1. normalization
2. standardization
3. continuous integration and continuous testing
4. infrastructure as code (IaC) and continuous delivery
5. automated security and compliance as code
6. automated compliance reporting and vulnerability remediation
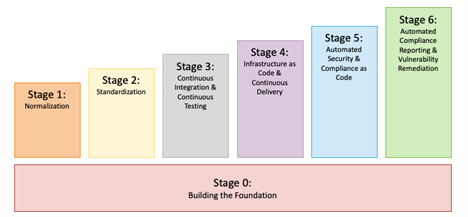
Breaking the work down in this way ensures that effort is spent implementing basic DevSecOps practices first, followed by more advanced processes later. This approach is consistent with the Agile practice of producing small, frequent releases in support of end users, which in this case are software-development teams. Not only are there dependencies in the early stages, but also a definite progression in the complexity and difficulty of the practices in each stage. In addition, our framework enables adaptation to changing requirements and provides ample opportunities for problem solving because many pieces of hardware and software must be integrated together to achieve the goal of implementing a fully automated CI/CD pipeline.
Our framework addresses technical activities that will most likely be implemented by technical staff. It does not specifically address the organization’s cultural changes that will also be required to successfully transition to DevSecOps. Such cultural shifts within organizations are challenging to implement and require a different set of skills and organizational mettle to implement than the practices in our technical framework. While you may observe some overlap in the technical and cultural practices—because it is hard to separate the two entirely—our framework focuses on the technical practices that enable your DevSecOps ecosystem to evolve and mature. To read more about spearheading a successful cultural shift, read this blog post.
The following sections describe practices we consider as key to each stage, based on our experiences deploying, operating, and maintaining computing infrastructure in support of development teams. A common theme across all the stages is the importance of monitoring. There are myriad monitoring solutions, both manual and automatic. Paying close attention to a team’s current situation is invaluable to making sound decisions. Your monitoring techniques must therefore evolve along with your DevSecOps and CI/CD capabilities at each stage.
Stage 0—Building the Foundation
We’ve numbered this Stage 0 because it is a prerequisite for all CI/CD activities, though it doesn’t directly contain practices specifically related to CI/CD pipelines.
Before you can have any ability to build a pipeline, you must have collaboration tools in place, including a wiki, an issue-tracking system, and a version-control system. You must have your identity-management system implemented correctly and be capable of collecting logs of system and application events and observing the health of your collaboration tools. These are the first steps to enabling solid monitoring capabilities in later stages. For more information about the process of deploying a computing environment from scratch in an on-premises or co-located data center, read our technical note.
Stage 1—Normalization
This stage focuses on getting organized through the adoption of DevSecOps practices and the minimization of redundancy (such as when performing database normalization). Encourage (or require) teams responsible for the deployment and operation of your computing environment to use the collaboration tools you set up in stage 0. The normalization stage is where developers start tracking code changes in a version-control system. Likewise, operations teams store all scripts in a version-control system.
Moreover, everyone—the teams managing the infrastructure and the development teams they support—starts tracking system issues, bugs, and user stories in an issue-tracking system. Any deployments or software installations that are not scripted and stored in version control should be documented in a wiki or other collaborative documentation system. The infrastructure team should also document repeatable processes in the wiki that cannot be automated.
In this stage, you should be cognizant of the variables within your environment that could be redundant. For example, you should begin to limit support of different operating system (OS) platforms. Each supported OS adds a significant burden when it comes to configuration management and compliance. Developers should develop on the same OS on which they’ll deploy. Likewise, operations teams should use an OS that is compatible with—and provides good support for—the systems they’ll be administering. Be sure to track other reasonable opportunities to eliminate overhead.
Stage 2—Standardization
This stage focuses on removing unnecessary variations in your environment. Ensure that your infrastructure and pipeline components are well monitored to remove the large variable of wondering whether your systems are healthy. Infrastructure monitoring can include automated alerts regarding system issues (e.g., low disk-space availability) or periodically generated reports that detail the overall health of the infrastructure. Define and document in your wiki standard operating procedures for common issues to empower everyone on the team to respond when those issues arise. Use consistent system configurations, ideally controlled by a configuration-management system.
For example, all your Linux systems might use the same configuration settings for log collection, authentication, and monitoring, no matter what services those systems provide. Reduce the complexity and overhead of operating your computing environment by adopting standard technologies across teams. In particular, have all your development teams use a single database product on the back end of their applications or the same visualization tool for metrics gathering. Finally, institute sets of standard criteria for the definition of done to ensure that teams have completed all necessary work to consider their tasks fully complete. In addition to monitoring the infrastructure, continue tracking remaining opportunities to normalize and standardize tool usage across teams.
Stage 3—Continuous Integration and Continuous Testing
This stage focuses on implementing continuous integration, which enables the capability of continuous testing. Continuous integration is a process that continually merges a system’s artifacts, including source-code updates and configuration items from all stakeholders on a team, into a shared mainline to build and test the developed system. This definition can easily be expanded for operations teams to mean frequent updates to configuration-management settings in the version-control system. All stakeholders should frequently update documentation in the teams’ wiki spaces and in tickets when appropriate, based on the type of work being documented. This approach enables and encourages the codification and reuse of deployment patterns useful for building applications and services.
Changes made to a codebase in the version-control system should then trigger build and test procedures. Continuous testing is the practice of running builds and tests each time a change is committed to a repository and should be a standard practice for software developers and DevSecOps engineers alike. Testing should encompass all types of changes, including code for software projects, shell scripts supporting system operation, or infrastructure as code (IaC) manifests. Continuous testing enables you to get frequent feedback on the quality of the code that’s committed.
Unit, functional, and integration tests should all be triggered when code is committed. You want to monitor the results of your automated tests to obtain accurate feedback about whether the builds were successful. Likewise, these tests increase confidence that code is working correctly before pushing it into production.
Our experience shows that it’s easy to miss certain failure modes and pass non-functioning code, particularly when you’re not diligent about adding error checking and testing for common failures. In other words, your monitoring systems must be mature and robust enough to communicate when problems are occurring with the changes made to infrastructure or code. Moreover, teams’ definition-of-done criteria should evolve to ensure that standard practices also evolve based on individual and team experiences to avoid common failure modes from occurring frequently.
Stage 4—Infrastructure as Code and Continuous Delivery
This stage accelerates your automated deployment processes by integrating infrastructure as code (IaC) and continuous delivery. IaC is the capability of capturing infrastructure deployment instructions in a textual format. This approach enables you to quickly and reliably deploy parts of your environment on either a bare-metal server, a virtual machine, or a container platform.
Continuous delivery is the practice of automatically applying changes (features, configurations, bug fixes, etc.) into production. IaC promotes environment parity by eliminating creeping configuration changes across systems and environments that could produce different outcomes. The chief benefit of using IaC and continuous delivery together is reliability. The IaC capability can increase confidence in your environment deployments. Likewise, the continuous-delivery capability increases confidence in your automated change delivery to those environments. Launching these two capabilities creates many possibilities.
Since you started leveraging automated testing in Stage 3, Stage 4 enables you to enforce the requirement that all tests be successful before changes are deployed into production. In turn, this enables you to
- leverage these capabilities to manage network devices with code in your version-control system
- test newly built software products by deploying them into newly built virtual environments or existing environments
- deploy into production when those changes are proven out
- automatically provision hosts to expand your current compute capabilities.
At this point, your infrastructure and the product under development become a tightly integrated system that enables you to fully understand the overall state of your system. To repeat a key practice from the previous stage, all these possibilities are enabled by a robust monitoring system. In fact, advancing past this stage into the next stage is virtually impossible without a continuous monitoring capability that quickly and accurately provides information about the state of the system and the system’s components.
Stage 5—Automated Security and Compliance as Code
This stage advances your automation capabilities beyond infrastructure and code deployments by adding security automations and compliance as code. Compliance as code means you’re tracking your compliance controls in scripts and configuration management so that tools can automatically ensure that your systems are compliant with applicable regulations and issue an alert when non-compliance is detected. These efforts combine the work of the security teams and the DevSecOps teams because your security teams will likely define requirements for the security controls, which provides the opportunity for technical people to automate adherence to those controls. There are many software pieces that come together to make this work, so you really need the previous four stages in place before undertaking this effort in this stage.
One tool that is essential in this stage is a dedicated vulnerability-scanning tool. You’ll also want your monitoring system to alert the correct set of people when security issues are detected automatically. Other tools can be leveraged to automatically install system and application updates and to automatically detect and remove unnecessary software.
Stage 6—Automated Compliance Reporting and Vulnerability Remediation
This final stage is the ultimate in supporting DevSecOps ecosystems because now that you’ve automated your system configurations, testing, and builds, you can focus on automating security patches and continuous feedback by means of automated report generation or notifications across DevSecOps pipelines. Compliance with security regulations often involves periodic reviews and assessments, and having reports readily available that have been automatically generated can greatly reduce the effort required to prepare for an assessment. Exactly what reports should be generated depends on your specific environment, but a few examples of useful reports include
- the output of automated vulnerability scans over time
- logs aggregated from your identity-management system
- records of patches applied to system firmware and software
- a summary from your network anomaly-detection system.
Moreover, new vulnerabilities often become known at random intervals based on vendor releases and research announcements. The ability to automatically generate reports about system status, security issues, and the impact of new vulnerabilities on your systems and applications means that your team can quickly and efficiently prioritize the work that must be done to ensure that your computing environment is as secure as it should be. Moreover, automating the installation of security patches to your systems and software helps to reduce the amount of manual effort spent maintaining compliant system and application configurations and can reduce the number of findings in your automated vulnerability scans. Likewise, being able to automatically monitor the outcomes of all these automated processes ensures that the people on your team can step in to repair problems as they arise.
Divergence from Traditional DevSecOps Perspectives
As mentioned above, we created our DevSecOps adoption framework specifically to support teams that deploy and maintain computing environments upon which other teams will design and use CI/CD pipelines. This perspective is similar to—but ultimately contrasts with—the typical use of DevSecOps practices. Figure 3 below focuses on the capability delivery branch, while most developers and DevSecOps practitioners are focused on the products branch.
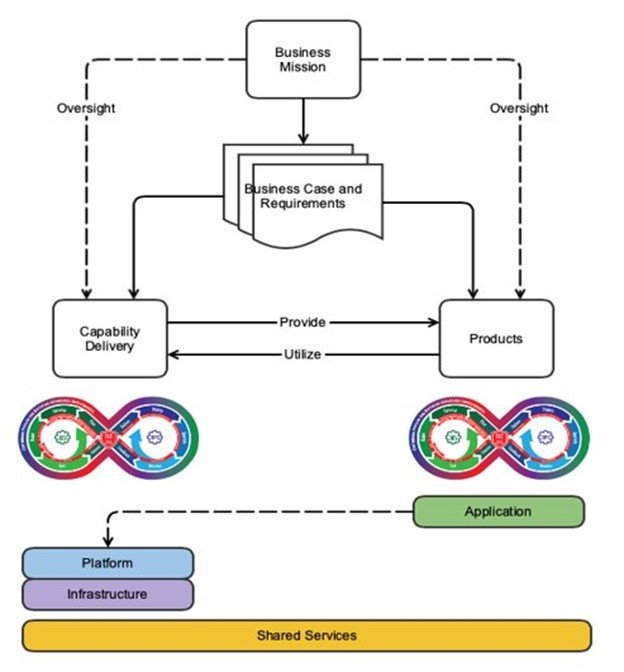
The DevSecOps Platform-Independent Model shown in Figure 3 explores this concept at an abstract level. Both the capability delivery branch and the products branch are designed to meet the mission needs of the business, but their designs produce two different plans: a system plan and a product plan. There are two distinct plans because there are two distinct entities at play here: the pipeline/system and the product that is being developed. Though they are related, they are distinct. Here we offer one example of the distinction between the two, which is the vast distance between the product operators and the developers of those products.
In an example of a DevSecOps team focused on the products branch, operations personnel work to support the production environment on which the software product is deployed. This experience allows for interesting insights, like “Release X caused instability at production scale because it increased CPU usage by 50 percent.” This insight can then be quickly and efficiently fed back to the developers who can work to address the underlying issue. In other words, the operations personnel and the development personnel are connected closely by means of the DevSecOps feedback loop. Ultimately, developers, security personnel, and operational personnel are closely knit by a common business mission and work toward a common goal of providing the best possible software product.
Conversely, the DevSecOps teams focused on the capability delivery branch are responsible for the operation and maintenance of a development computing environment, and they work to provide access to a significant number of tools to various stakeholders. The development personnel require access to development tools and software libraries. The security personnel require access to vulnerability-scanning tools and reporting tools. The operations personnel themselves require access to monitoring tools, visualization tools, and hardware-management tools.
Few if any of these tools are developed in-house—instead they are either open-source or commercial-off-the-shelf tools. This dynamic provides an important separation of the operations team from the product-development team. In contrast to the typical scenario described above, when the operations team notices that a new release breaks something in their environment, they can appeal to the developers of the product for a fix that could get implemented if it affects enough customers. In other words, the operations teams do not collaborate with the development teams under the same business mission, but instead are simply customers of the vendors who provide the products in use.
What’s more, when the unpredictability of infrastructure failures and user trouble tickets are added, they can disrupt the Agile practices of backlog grooming, sprint planning, and the metric of velocity. These dynamics are different from a pure DevSecOps strategy and they may be uncomfortable for people used to working in a development environment, where the entire team is focused one hundred percent of the time on a single project. But with a few adaptations to that traditional DevSecOps model, this framework can be applied to provide the benefits of DevSecOps practices in an operationally focused environment.
Realizing the Promise of DevSecOps and CI/CD Pipelines
The goal of implementing a resilient computing environment that can support a DevSecOps ecosystem is ambitious, in the same way that “develop working software” is an ambitious—yet essential—goal. However, the benefits of implementing DevSecOps practices—including CI/CD pipelines—often outweigh the costs of those difficulties.
Proper planning at the early stages can make the later stages easier to implement. Our framework therefore advocates for breaking the process down into small, manageable tasks, and prioritizing repeatability first, automation second. Our framework orders the tasks in a logical progression so that the fundamental building blocks for automation are put in place before the automation itself.
The progression through the stages is not a one-time effort. These practices require ongoing effort to keep your development environment and software products up to date with the latest in technological advancements. You should periodically evaluate your current practices against the available knowledge, tools, and resources, and adjust as necessary to continue to support your organization's mission in the most effective way possible.
Additional Resources
Read the SEI blog post, A Framework for DevSecOps Evolution and Achieving Continuous-Integration/Continuous-Delivery (CI/CD) Capabilities.
Read more about SEI work in DevSecOps.
Read more about SEI work in Agile.
Read the SEI blog post, Continuous Integration in DevOps.
Read the SEI blog post, Why You Should Apply Agile-DevOps Earlier in the Lifecycle.
Read the SEI blog post, Integrating Your Development and Application Security Pipelines Through DevOps.
Read the SEI blog post, Modeling DevSecOps to Protect the Pipeline.
Read the SEI blog post, Six Remedies to Employee Resistance to DevOps.
Read the SEI technical note, Planning and Design Considerations for Data Centers.
Explore the DevSecOps Platform-Independent Model.
Written By


More By The Authors
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed