Detecting Mismatches in Machine-Learning Systems

PUBLISHED IN
Artificial Intelligence EngineeringThe use of machine learning (ML) could improve many business functions and meet many needs for organizations. For example, ML capabilities can be used to suggest products to users based on purchase history; provide image recognition for video surveillance; identify spam email messages; and predict courses of action, routes, or diseases, among others. However, in most organizations today (with the exception of large high-tech companies, such as Google and Microsoft), development of ML capabilities is still mainly a research activity or a standalone project, and there is a dearth of existing guidance to help organizations develop these capabilities.
Integrating ML components into applications is limited by the fragility of these components and their algorithms. They are susceptible to changes in data that could cause their predictions to change over time. They are also limited by mismatches between different system components.
For example, if an ML model is trained on data that is different from data in the operational environment, field performance of the ML component will be dramatically reduced. In this blog post, which is adapted from a paper that SEI colleagues and I presented at the 2019 Association for the Advancement of Artificial Intelligence (AAAI) fall seminar (Artificial Intelligence in Government and Public Sector), I describe how the SEI is developing new ways to detect and prevent mismatches in ML-enabled systems so that ML can be adopted with greater success to drive organizational improvement.
The Sources of Mismatches
One challenge in deploying complex systems is integrating all components and resolving any system-component mismatches. For systems that incorporate ML components, the sources and effects of these mismatches may be different from other software-integration efforts.
Apart from software engineering considerations, the expertise needed to field an ML component within a system frequently comes from outside the field of software engineering. As a result, assumptions and even descriptive language used by practitioners from these different disciplines can exacerbate other challenges to integrating ML components into larger systems. We are investigating classes of mismatches in ML systems integration to identify the implicit assumptions made by practitioners in different fields (data scientists, software engineers, operations staff) and find ways to communicate the appropriate information explicitly. To enable ML components to be fielded successfully, we will need to understand the mismatches that exist and develop practices to mitigate the consequences of these mismatches.
Mismatched Perspectives in Machine-Learning-Enabled Systems
We define an ML-enabled system as a software system that relies on one or more ML software components to provide required capabilities, as shown in Figure 1.
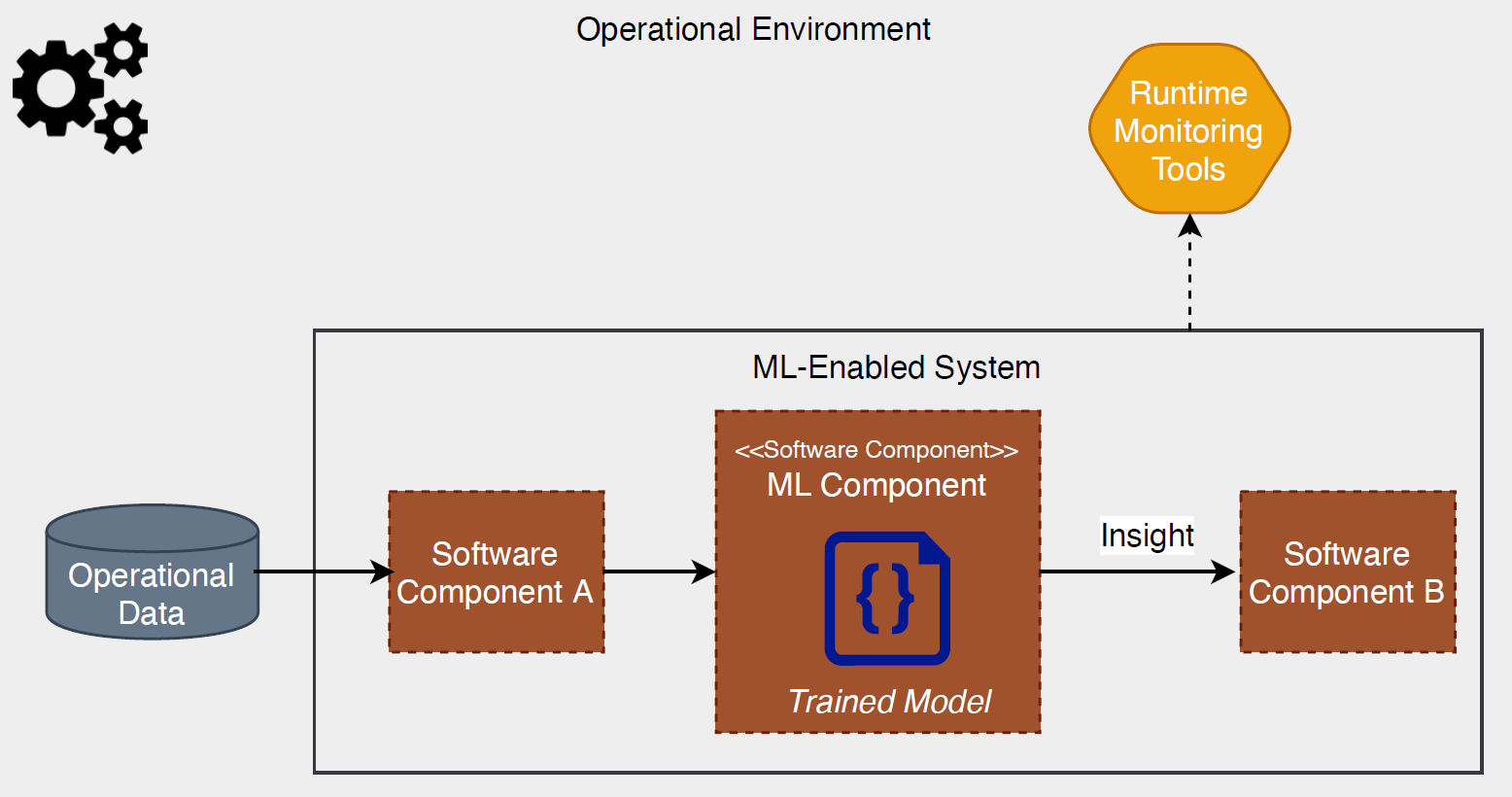
The ML component in Figure 1 receives processed operational data from one software component (i.e., upstream component) and generates an insight that is consumed by another software component (i.e., downstream component). A problem in these types of systems is that their development and operation involve three perspectives, with three different and often completely separate workflows and people.
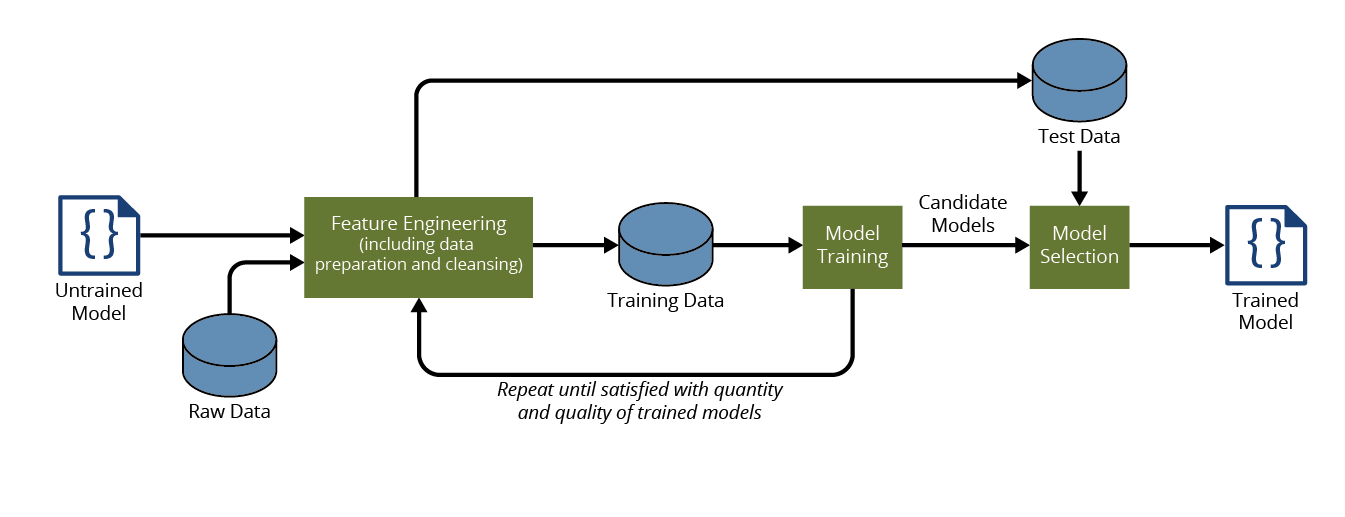
- The data scientist builds the model: The workflow of the data scientist, as shown in Figure 2, is to take an untrained model and raw data, and use feature engineering to create a set of training data that is then used to train the model, repeating these steps until a set of adequate models is produced. A set of test data is then used to test the different models, and the one that performs the best based on a set of defined evaluation metrics is selected. Out of this workflow comes a trained model.
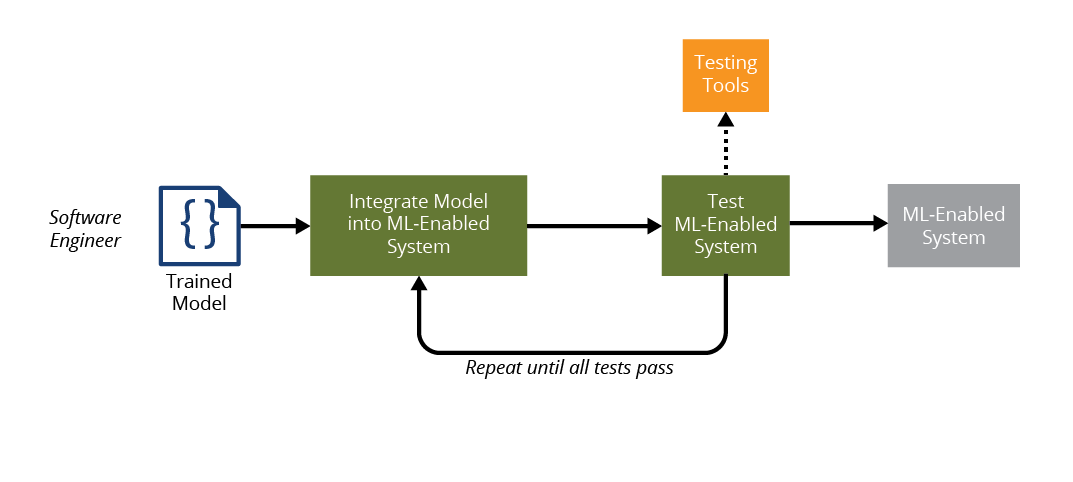
2. The software engineer integrates the trained model into a larger system: The workflow of the software engineer, as shown in Figure 3, is to take the trained model, integrate the model into the ML-enabled system, and test the system until it passes all tests. The ML-enabled system is then passed to operations staff for deployment.
3. Operations staff deploy, operate, and monitor the system. As shown in Figure 1, in addition to the operation and monitoring of the ML-enabled system, operations staff are also responsible for operation and monitoring of operational data sources (e.g., databases, data streams, data feeds).
These three perspectives operate separately and often use different terminology. As a result, there are opportunities for mismatch between the assumptions made by each perspective with respect to the elements of the ML-enabled system--the non-human entities involved in the training, integration, and operation of ML-enabled systems--and the actual guarantees provided by each element. This problem is exacerbated by the fact that system elements evolve independently and at different rhythms, which could over time lead to unintentional mismatch. In addition, these perspectives are likely to belong to three different organizations.
Late discovery of implicit and inconsistent assumptions about ML and non-ML elements of ML-enabled systems causes misbehavior and costly rework. Here are some examples:
- The system performs poorly because the computing resources that were used during testing of the model are different from the computing resources used during operations. This problem would be an example of a computing-resource mismatch.
- Model accuracy is poor because model training data is different from operational data. This problem would be a data-distribution mismatch.
- A large amount of glue code must be created because the trained model input/output is incompatible with operational data types. This problem would be application-programming interface (API) mismatch.
- The system fails when it was not tested adequately because the developers were not able to replicate the testing that was done during model training. This problem would be a test environment mismatch.
- Existing monitoring tools cannot detect diminishing model accuracy, which is the performance metric defined for the trained model. This problem would be a metric mismatch.
Based on the above, we define an ML mismatch as a problem that occurs in the development, deployment, and operation of an ML-enabled system due to incorrect assumptions made about system elements by different stakeholders that result in a negative consequence. The different stakeholders in our example are data scientist, software engineer, and release (operations) engineer. ML mismatch can be traced back to information that could have prevented problems if it had been shared among stakeholders.
Large high-tech companies, such as Google and Amazon, have addressed the ML mismatch problem by putting one team in charge of all three functions for a specific AI/ML microservice. Although this approach does not make the assumptions more explicit, it does solve some of the communication problems. In essence, developing an AI/ML model is a statistical problem that is relatively fast and cheap; but deploying, evolving, and maintaining models and the systems that contain them is an engineering problem that is hard and expensive.
Solution to Mismatch
The SEI is developing machine-readable ML-enabled-system element descriptors as a way of detecting and preventing mismatches. The goal of these descriptors is to ease adoption of ML systems by codifying attributes of system elements and therefore making all assumptions explicit. The descriptors would then be used by system stakeholders manually for information, awareness, and evaluation; and by automated mismatch detectors at design time and runtime for cases in which system attributes lend themselves to automation.
Benefits that we anticipate from this work include the following:
- Definitions of mismatch serve as checklists as ML-enabled systems are developed.
- Recommended descriptors provide stakeholders (e.g., government program offices) with examples of information to request or requirements to impose.
- Means for validating ML-enabled system-element attributes provide ideas for confirming information provided by third parties.
- Identification of attributes for which automated detection is feasible defines new software components for ML-enabled systems.
As the work progresses, we expect to learn answers to questions such as
- What are common types of mismatch that occur in the end-to-end development of ML-enabled systems?
- How can we best document data, models, and other ML system elements that will enable mismatches to be detected?
- What are examples of mismatch that could be detected in an automated way, based on the codification of machine-readable descriptors for ML system elements?
Approach and Validity
The technical approach for constructing and validating the ML-enabled system-element descriptors comprises three phases.
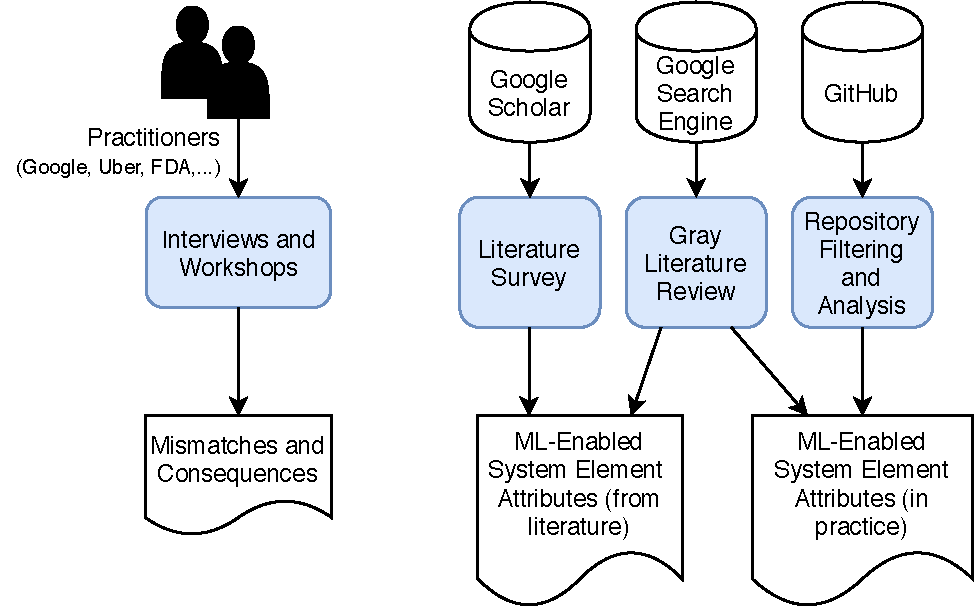
Phase 1, Information Gathering: As shown in Figure 4, this phase involves two parallel tasks. In one task, we elicit examples of mismatches and their consequences from practitioners through interviews. In the second task, we identify attributes currently used to describe elements of ML-enabled systems by mining project descriptions from GitHub repositories that contain trained and untrained models, a white literature review, and a gray literature review. This multi-modal approach provides both the practitioner and the academic perspective on how to describe ML-enabled system elements.
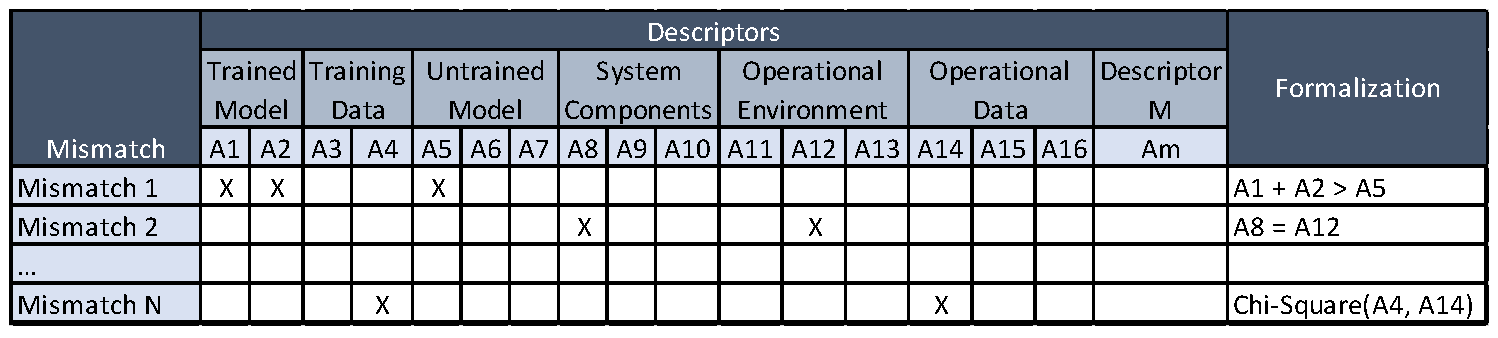
Phase 2, Analysis: The tasks in this phase are shown in Figure 5. After we elicit mismatches and attributes of elements of ML-enabled systems, we map these by producing an initial version of the spreadsheet shown in Figure 6. For each mismatch, we identify the set of attributes that could be used to detect that mismatch, and formalize the mismatch as a predicate over those attributes, as shown in the Formalization column in Figure 6. As an example, this figure shows that Mismatch 1 occurs when the value of Attribute 1 plus the value of Attribute 2 is greater than the value of Attribute 5.
The next step involves performing gap analysis to identify mismatches that do not map to any attributes and attributes that do not map to any mismatch. We then complement the mapping based on our domain knowledge by adding attributes and potentially adding new mismatches that could be detected based on the available attributes. Finally, there is a data-source and feasibility-analysis step where for each attribute we identify
- the data source (who provides the value)
- the feasibility of collecting those values (is it reasonable to expect someone to provide that value or is there a way of automating its collection?)
- how it can be validated (if necessary to validate that the provided value is correct)
- potential for automation (can the set of identified attributes be used in scripts or tools for detecting that mismatch?)
After the analysis phase, we have an initial version of the spreadsheet and an initial version of the descriptors derived from the spreadsheet.

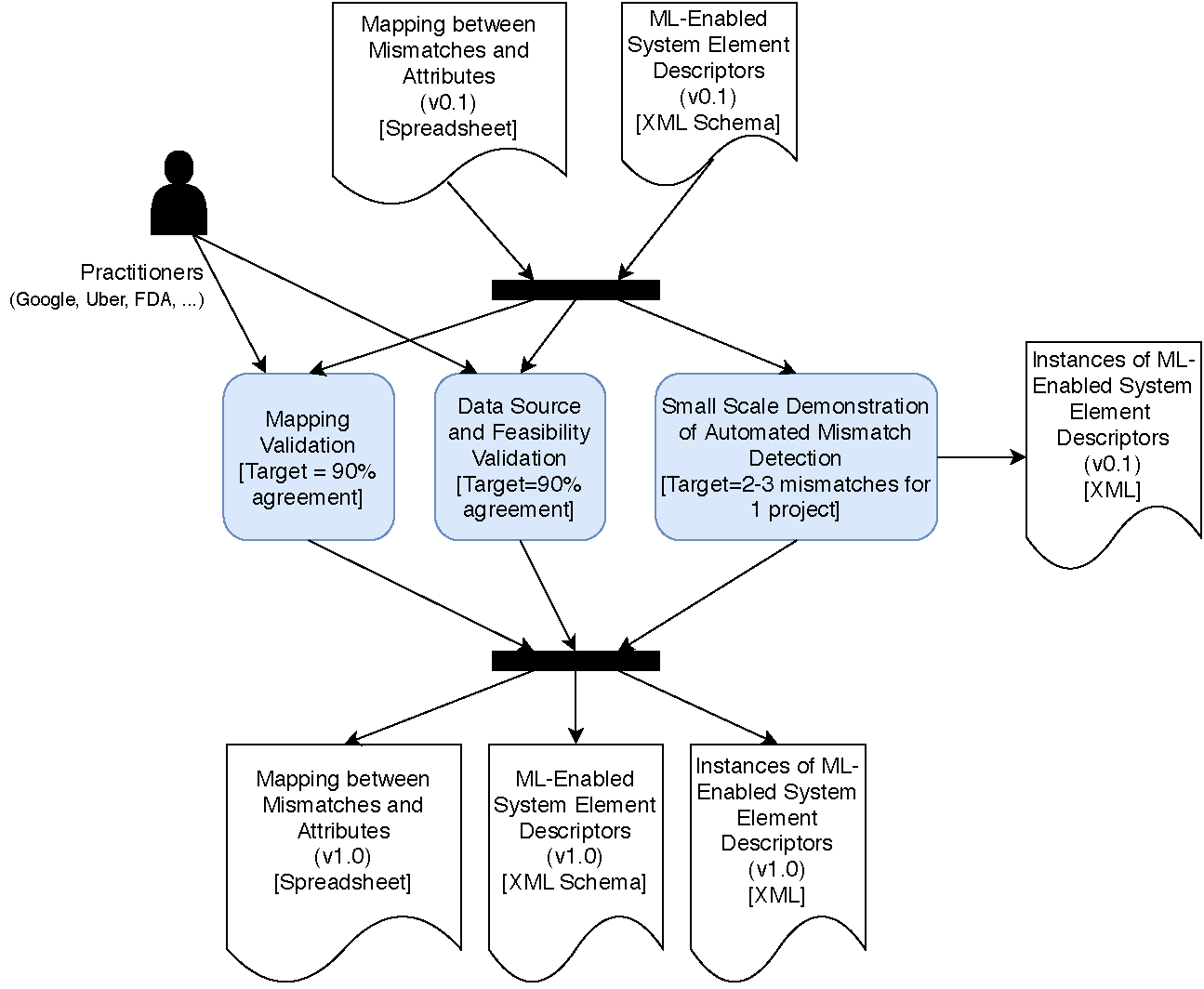
Phase 3, Evaluation: As shown in Figure 7, in this phase, we re-engage with the interview participants from the information-gathering phase to validate mapping, data sources, and feasibility. The evaluation target is a 90 percent agreement on the work developed in the analysis phase. We also develop a small-scale demonstration of automated mismatch detection, identifying mismatches in a project that can be detected through automation, and developing scripts that can detect the mismatch. In the end, the expected outcomes of this work are the validated mapping between mismatches and attributes, a set of descriptors created from that mapping, and instances of the descriptors.
Looking Ahead to Next Steps
As a result of our work, we envision communities beginning to develop tools for automatically detecting ML mismatches and organizations beginning to include mismatch detection in their toolchains for developing ML-enabled systems. As a step in this direction, we are working on the following artifacts:
- A list of attributes for ML-enabled system elements
- A mapping of mismatches to attributes (spreadsheet)
- An XML schema for each descriptor (one per system element) plus XML examples of descriptors
- A small-scale demonstration (scripts) of automated mismatch detection
Through the interviews I described in the information-gathering phase, we plan to socialize the concept of mismatch and convey its importance for the deployment of ML-enabled systems into production; elicit and confirm mismatches in ML-enabled systems and their consequences from people in the field; and obtain early feedback on the study protocol and resulting artifacts. If you are interested in sharing your examples of mismatch or in developing tools for mismatch detection, we encourage you to contact us at info@sei.cmu.edu.
Additional Resources
Read other SEI blog posts on artificial intelligence and machine learning.
Read the SEI blog post, Three Risks in Building Machine Learning Systems.
Read the SEI blog post, The Vectors of Code: On Machine Learning for Software.
Read the SEI blog post, Translating Between Statistics and Machine Learning.
Read the paper, Component Mismatches are a Critical Bottleneck to Fielding AI-Enabled Systems in the Public Sector by Grace Lewis, Stephanie Bellomo, and April Galyardt.
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed