Tackling Collaboration Challenges in the Development of ML-Enabled Systems

Collaboration on complex development projects almost always presents challenges. For traditional software projects, these challenges are well known, and over the years a number of approaches to addressing them have evolved. But as machine learning (ML) becomes an essential component of more and more systems, it poses a new set of challenges to development teams. Chief among these challenges is getting data scientists (who employ an experimental approach to system model development) and software developers (who rely on the discipline imposed by software engineering principles) to work harmoniously.
In this SEI blog post, which is adapted from a recently published paper to which I contributed, I highlight the findings of a study on which I teamed up with colleagues Nadia Nahar (who led this work as part of her PhD studies at Carnegie Mellon University and Christian Kästner (also from Carnegie Mellon University) and Shurui Zhou (of the University of Toronto).The study sought to identify collaboration challenges common to the development of ML-enabled systems. Through interviews conducted with numerous individuals engaged in the development of ML-enabled systems, we sought to answer our primary research question: What are the collaboration points and corresponding challenges between data scientists and engineers? We also examined the effect of various development environments on these projects. Based on this analysis, we developed preliminary recommendations for addressing the collaboration challenges reported by our interviewees. Our findings and recommendations informed the aforementioned paper, Collaboration Challenges in Building ML-Enabled Systems: Communication, Documentation, Engineering, and Process, which I’m proud to say received a Distinguished Paper Award at the 44th International Conference on Software Engineering (ICSE 2022).
Despite the attention ML-enabled systems have attracted—and the promise of these systems to exceed human-level cognition and spark great advances—moving a machine-learned model to a functional production system has proved very hard. The introduction of ML requires greater expertise and introduces more collaboration points when compared to traditional software development projects. While the engineering aspects of ML have received much attention, the adjacent human factors concerning the need for interdisciplinary collaboration have not.
The Current State of the Practice and Its Limits
Most software projects extend beyond the scope of a single developer, so collaboration is a must. Developers normally divide the work into various software system components, and team members work largely independently until all the system components are ready for integration. Consequently, the technical intersections of the software components themselves (that is, the component interfaces) largely determine the interaction and collaboration points among development team members.
Challenges to collaboration occur, however, when team members cannot easily and informally communicate or when the work requires interdisciplinary collaboration. Differences in experience, professional backgrounds, and expectations about the system can also pose challenges to effective collaboration in traditional top-down, modular development projects. To facilitate collaboration, communication, and negotiation around component interfaces, developers have adopted a range of strategies and often employ informal broadcast tools to keep everyone on the same page. Software lifecycle models, such as waterfall, spiral, and Agile, also help developers plan and design stable interfaces.
ML-enabled systems generally feature a foundation of traditional development into which ML component development is introduced. Developing and integrating these components into the larger system requires separating and coordinating data science and software engineering work to develop the learned models, negotiate the component interfaces, and plan for the system’s operation and evolution. The learned model could be a minor or major component of the overall system, and the system typically includes components for training and monitoring the model.
All of these steps mean that, compared to traditional systems, ML-enabled system development requires expertise in data science for model building and data management tasks. Software engineers not trained in data science who, nevertheless, take on model building tend to produce ineffective models. Conversely, data scientists tend to prefer to focus on modeling tasks to the exclusion of engineering work that might influence their models. The software engineering community has only recently begun to examine software engineering for ML-enabled systems, and much of this work has focused narrowly on matters such as testing models and ML algorithms, model deployment, and model fairness and robustness. Software engineering research on adopting a system-wide scope for ML-enabled systems has been limited.
Framing a Research Approach Around Real-World Experience in ML-Enabled System Development
Finding limited existing research on collaboration in ML-enabled system development, we adopted a qualitative strategy for our research based on four steps: (1) establishing scope and conducting a literature review, (2) interviewing professionals building ML-enabled systems, (3) triangulating interview findings with our literature review, and (4) validating findings with interviewees. Each of these steps is discussed below:
- Scoping and literature review: We examined the existing literature on software engineering for ML-enabled systems. In so doing, we coded sections of papers that either directly or implicitly addressed collaboration issues among team members with different skills or educational backgrounds. We analyzed the codes and derived the collaboration areas that informed our interview guidance.
- Interviews: We conducted interviews with 45 developers of ML-enabled systems from 28 different organizations that have only recently adopted ML (see Table 1 for participant demographics). We transcribed the interviews, and then we created visualizations of organizational structure and responsibilities to map challenges to collaboration points (see Figure 1 for sample visualizations). We further analyzed the visualizations to determine whether we could associate collaboration problems with specific organizational structures.
- Triangulation with literature: We connected interview data with related discussions identified in our literature review, along with potential solutions. Out of the 300 papers we read, we identified 61 as possibly relevant and coded them using our codebook.
- Validity check: After creating a full draft of our study, we provided it to our interviewees along with supplementary material and questions prompting them to check for correctness, areas of agreement and disagreement, and any insights gained from reading the study.
Table 1: Participant and Company Demographics
|
Type |
Break-Down |
|
Participant Role (45) |
ML-focused (23), SE-focused (9), Management (5), Operations (2), Domain expert (4) |
|
Participant Seniority (45) |
5 years of experience or more (28), 2-5 years (9), less than 2 years (8) |
|
Company Type (28) |
Big tech (6), Non-IT (4), Mid-size tech (11), Startup (5), Consulting (2) |
|
Company Location (28) |
North America (11), South America (1), Europe (5), Asia (10), Africa (1) |
Our interviews with professionals revealed that the number and types of teams developing ML-enabled systems, their composition, their responsibilities, the power dynamics at play, and the formality of their collaborations varied widely from organization to organization. Figure 1 presents a simplified illustration of teams in two organizations. Team composition and responsibility differed for various artifacts (for instance, model, pipeline, data, and responsibility for the final product). We found that teams often have multiple responsibilities and interface with other teams at multiple collaboration points.
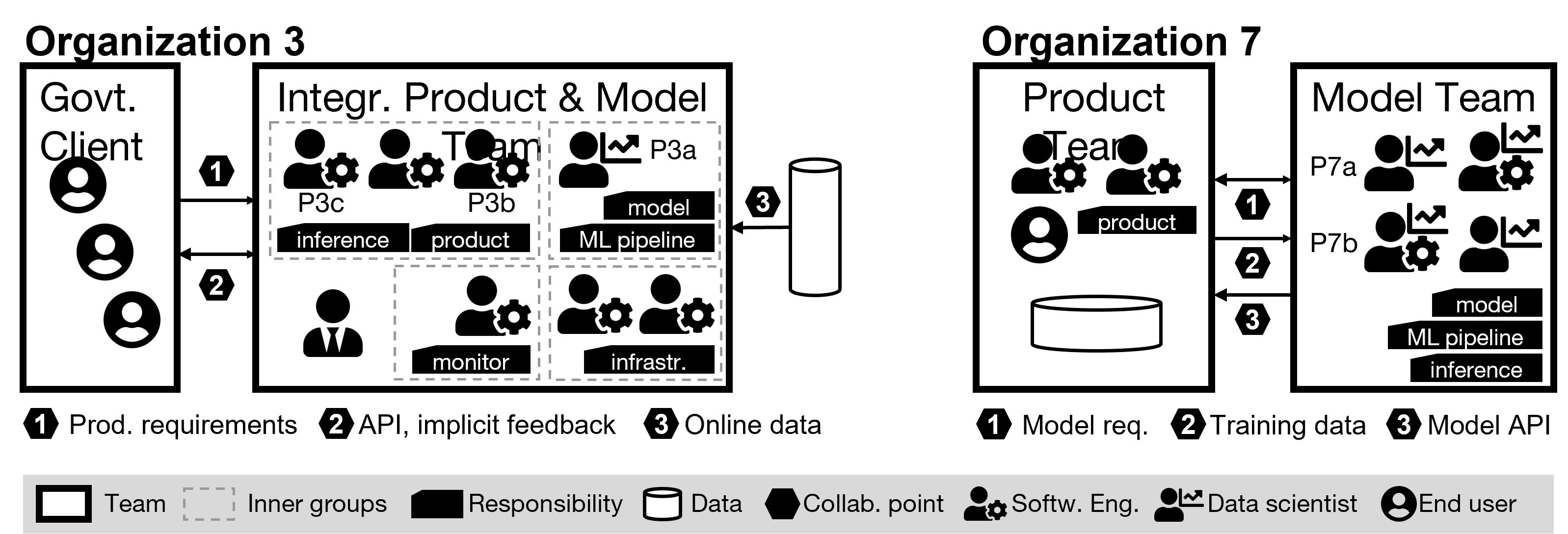
Some teams we examined have responsibility for both model and software development. In other cases, software and model development are handled by different teams. We discerned no clear global patterns across all the team we studied. However, patterns did emerge when we narrowed the focus to three specific aspects of collaboration:
- requirements and planning
- training data
- product-model integration
Navigating the Tensions Between Product and Model Requirements
To begin, we found key differences in the order in which teams identify product and model requirements:
- Model first (13 of 28 organizations): These teams build the model first and then build the product around the model. The model shapes product requirements. Where model and product teams are different, the model team most often starts the development process.
- Product first (13 of 28 organizations): These teams start with product development and then develop a model to support it. Most often, the product already exists, and new ML development seeks to enhance the product’s capabilities. Model requirements are derived from product requirements, which often constrain model qualities.
- Parallel (2 of 28 organizations): The model and product teams work in parallel.
Regardless of which of these three development trajectories applied to any given organization, our interviews revealed a constant tension between product requirements and model requirements. Three key observations arose from these tensions:
- Product requirements require input from the model team. It’s hard to elicit product requirements without a solid understanding of ML capabilities, so the model team must be involved in the process early. Data scientists reported having to contend with unrealistic expectations about model capabilities, and they frequently had to educate clients and developers about ML techniques to correct these expectations. Where a product-first development trajectory is practiced, it was possible for the product team to ignore data requirements when negotiating product requirements. However, when requirements gathering is left to the model team, key product requirements, such as usability, might be ignored.
- Model development with unclear requirements is common. Despite an expectation they will work independently, model teams rarely receive adequate requirements. Often, they engage in their work without a complete understanding of the product their model is to support. This omission can be a thorny problem for teams that practice model-first development.
- Provided model requirements rarely go beyond accuracy and data security. Ignoring other important requirements, such as latency or scalability, has caused integration and operation problems. Fairness and explainability requirements are rarely considered.
Recommendations
Requirements and planning form a key collaboration point for product and model teams developing ML-enabled systems. Based on our interviews and literature review, we’ve proposed the following recommendations for this collaboration point:
- Involve data scientists early in the process.
- Consider adopting a parallel development trajectory for product and model teams.
- Conduct ML training sessions to educate clients and product teams.
- Adopt more formal requirements documentation for both model and product.
Addressing Challenges Related to Training Data
Our study revealed that disagreements over training data represented the most common collaboration challenges. These disagreements often stem from the fact that the model team frequently does not own, collect, or understand the data. We observed three organizational structures that influence the collaboration challenges related to training data:
- Provided data: The product team provides data to the model team. Coordination tends to be distant and formal, and the product team holds more power in negotiations over data.
- External data: The model team relies on an external entity for the data. The data generally comes from publicly available sources or from a third-party vendor. In the case of publicly available data, the model team has little negotiating power. It holds more negotiating power when hiring a third party to source the data.
- In-house data: Product, model, and data teams all exist within the same organization and make use of that organization’s internal data. In such cases, both product and model teams need to overcome negotiation challenges related to data use stemming from differing priorities, permissions, and data security requirements.
Many interviewees noted dissatisfaction with data quantity and quality. One common problem is that the product team often lacks knowledge about quality and amount of data needed. Other data problems common to the organizations we examined included the following:
- Provided and public data are often inadequate. Research has raised questions about the representativeness and trustworthiness of such data. Training skew is common: models that show promising results during development fail in production environments because real-world data differs from the provided training data.
- Data understanding and access to data experts often present bottlenecks. Data documentation is almost never adequate. Team members often collect information and keep track of the details in their heads. Model teams who receive data from product teams struggle getting help from the product team to understand the data. The same holds for data obtained from publicly available sources. Even internal data often suffers from evolving and poorly documented data sources.
- Ambiguity arises when hiring a data firm. Difficulty sometimes arises when a model team seeks buy-in from the product team on hiring an external data firm. Participants in our study noted communication vagueness and hidden assumptions as key challenges in the process. Expectations are communicated verbally, without clear documentation. Consequently, the data team often does not have sufficient context to understand what data is needed.
- There is a need to handle evolving data. Models need to be regularly retrained with more data or adapted to changes in the environment. However, in cases where data is provided continuously, model teams struggle to ensure consistency over time, and most organizations lack the infrastructure to monitor data quality and quantity.
- In-house priorities and security concerns often obstruct data access. Often, in-house projects are local initiatives with at least some management buy-in but little buy-in from other teams focused on their own priorities. These other teams might question the business value of the project, which might not affect their area directly. When data is owned by a different team within the organization, security concerns over data sharing often arise.
Training data of sufficient quality and quantity is crucial for developing ML-enabled systems. Based on our interviews and literature review, we’ve proposed the following recommendations for this collaboration point:
- When planning, budget for data collection and access to domain experts (or even a dedicated data team).
- Adopt a formal contract that specifies data quality and quantity expectations.
- When working with a dedicated data team, make expectations very clear.
- Consider employing a data validation and monitoring infrastructure early in the project.
Challenges Integrating the Product and Model in ML-Enabled Systems
At this collaboration point, data scientists and software engineers need to work closely together, frequently across multiple teams. Conflicts often occur at this juncture, however, stemming from unclear processes and responsibilities. Differing practices and expectations also create tensions, as does the way in which engineering responsibilities are assigned for model development and operation. The challenges faced at this collaboration point tended to fall into two broad categories: culture clashes among teams with differing responsibilities and quality assurance for model and project.
Interdisciplinary Collaboration and Cultural Clashes
We observed the following conflicts stemming from differences in software engineering and data science cultures, all of which were amplified by a lack of clarity about responsibilities and boundaries:
- Team responsibilities often do not match capabilities and preferences. Data scientists expressed dissatisfaction when pressed to take on engineering tasks, while software engineers often had insufficient knowledge of models to effectively integrate them.
- Siloing data scientists fosters integration problems. Data scientists often work in isolation with weak requirements and a lack of understanding of the larger context.
- Technical jargon challenges communication. The differing terminology used in each field leads to ambiguity, misunderstanding, and faulty assumptions.
- Code quality, documentation, and versioning expectations differ widely. Software engineers asserted that data scientists do not follow the same development practices or conform to the same quality standards when writing code.
Many conflicts we observed relate to boundaries of responsibility and differing expectations. To address these challenges, we proposed the following recommendations:
- Define processes, responsibilities, and boundaries more carefully.
- Document APIs at collaboration points.
- Recruit dedicated engineering support for model deployment.
- Don’t silo data scientists.
- Establish common terminology.
Interdisciplinary Collaboration and Quality Assurance for Model and Product
During development and integration, questions of responsibility for quality assurance often arise. We noted the following challenges:
- Goals for model adequacy are hard to establish. The model team almost always evaluates the accuracy of the model, but it has difficulty deciding whether the model is good enough owing to a lack of criteria.
- Confidence is limited without transparent model evaluation. Model teams do not prioritize evaluation, so they often have no systematic evaluation strategy, which in turn leads to skepticism about the model from other teams.
- Responsibility for system testing is unclear. Teams often struggle with testing the entire system after model integration, with model teams frequently assuming no responsibility for product quality.
- Planning for online testing and monitoring is rare. Though necessary to monitor for training skew and data drift, such testing requires the coordination of teams responsible for product, model, and operation. Furthermore, many organizations don’t do online testing due to the lack of a standard process, automation, or even test awareness.
Based on our interviews and the insights they provided, we developed the following recommendations to address challenges related to quality assurance:
- Prioritize and plan for quality assurance testing.
- The product team should assume responsibility for overall quality and system testing, but it should engage the model team in the creation of a monitoring and experimentation infrastructure.
- Plan for, budget, and assign structured feedback from the product engineering team to the model team.
- Evangelize the benefits of testing in production.
- Define clear quality requirements for model and product.
Conclusion: Four Areas for Improving Collaboration on ML-Enabled System Development
Data scientists and software engineers are not the first to realize that interdisciplinary collaboration is challenging, but facilitating such collaboration has not been the focus of organizations developing ML-enabled systems. Our observations indicate that challenges to collaboration on such systems fall along three collaboration points: requirements and project planning, training data, and product-model integration. This post has highlighted our specific findings in these areas, but we see four broad areas for improving collaboration in the development of ML-enabled systems:
Communication: To combat problems arising from miscommunication, we advocate ML literacy for software engineers and managers, and likewise software engineering literacy for data scientists.
Documentation: Practices for documenting model requirements, data expectations, and assured model qualities have yet to take root. Interface documentation already in use may provide a good starting point, but any approach must use a language understood by everyone involved in the development effort.
Engineering: Project managers should ensure sufficient engineering capabilities for both ML and non-ML components and foster product and operations thinking.
Process: The experimental, trial-and error process of ML model development does not naturally align with the traditional, more structured software process lifecycle. We advocate for further research on integrated process lifecycles for ML-enabled systems.
Additional Resources
To take a deeper dive into our research, we invite you to read the entire paper, Collaboration Challenges in Building ML-Enabled Systems: Communication, Documentation, Engineering, and Process.
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed