Using Machine Learning to Detect Design Patterns


PUBLISHED IN
Artificial Intelligence EngineeringSoftware increasingly serves core DoD functions, such as ship and plane navigation, supply logistics, and real-time situational awareness. The complexity of software, however, makes it hard to evaluate software quality. The ability to evaluate software is critical both for software developers and for DoD program managers who are responsible for software acquisitions.
The quality of software can make or break a program budget. Quality attributes such as reliability, security, and modifiability are just as important as making sure the software computes the right answer. Any major design approach chosen by the developer will have quality attribute properties associated with it. Client-server is good for scalability, layering is good for portability, services are good for interoperability.
An important component of evaluating software quality attributes at scale is the ability to efficiently identify these design approaches in source code known as design patterns. This blog post explains why design patterns matter and reports promising results of an experimental use of machine learning (ML) to detect design patterns in source code.
Better Design Patterns Make Better Software
Our recent survey of more than 1,800 software developers had many responses similar to this one by a senior developer:
We have a model-view-controller (MVC) framework. Over time we violated the simple rules of this framework and had to retrofit later many functionality [sic] with a lot of added cost.
The MVC framework referenced in the above example is a design pattern, or a conceptual guideline for developing source code to promote flexibility, reliability, and security. There are many design patterns. Prominent patterns include pipe-filter, publish-subscribe, ping-echo, transaction processing.
One reason why design patterns might be violated over time is that developers do not have adequate tools to detect and reason about proper pattern implementation. Suboptimal software-implementation choices that contradict intended design patterns are often referred to as anti-patterns. These design flaws make the code hard to understand, modify, maintain, and evolve. They also tend to harm software quality and increase long-term maintenance and development costs. Thus, the ability to recognize design patterns and their anti-patterns in source code is necessary for any comprehensive evaluation of software quality.
Unfortunately, manual evaluation of design-pattern implementation is costly, particularly on the scale of the billions of lines of source code underlying DoD software. A manual evaluation involves highly-skilled software architects laboriously examining source code line-by-line, paying attention both to the content of each line and all relevant connections to other lines scattered throughout the repository.
Software Quality Evaluation Is Costly, But Machine Learning May be Able to Help
The high cost of design-pattern detection motivated us to apply code analysis and machine learning to automatically detect design patterns. As of October 2019, we have attempted to automatically label source-code files of the Spring MVC framework for Java source code. The MVC design pattern divides an interactive application into three interconnected elements:
- The model contains core functionality and data.
- Views display data to the user.
- Controllers handle user input.
The Spring MVC framework divides Java classes (or files, as there is ordinarily one class per file) into these disjoint groups and further decomposes the model, as shown in Figure 1.
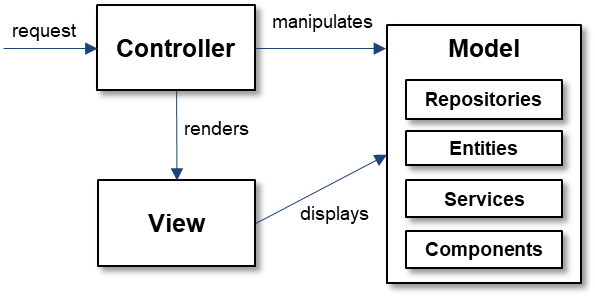
Figure 1: The Spring MVC framework requires each Java file to belong to one of several disjoint functional groups with a rigid set of expectations about intergroup relationships. Image source: Aniche et al (2017).
MVC is a relevant pattern for industry and DoD software capabilities in enterprise IT and operations centers that provide intelligence to the battlefield. It is widely used and understood, and is representative of the kinds of structures used to develop systems at scale. It is also too complex to handle in a large-scale software project using simple tools.
We built a classifier that estimates the MVC group label (with six possible values) for each file in a Java source-code repository. Applicable MVC group labels are controller and repository, entity, service, and component that compose the model (the view element of the MVC pattern is out of scope of the code we examined). All other files are labeled other. Figure 2 shows the hold-out test performance of our classifier.
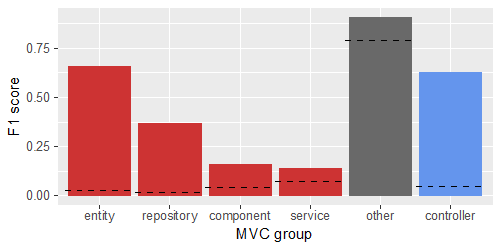
Figure 2: The F1 score is the harmonic mean between precision and recall; the best possible value of this score is 1. The horizonal dashed line on each bar indicates the F1 score that corresponds to random guessing. The four red bars are subcategories of the "Model" group and the grey bar represents all other files not related to MVC.
The classifier uses machine learning informed by programming-language semantics. Feature engineering incorporates different source-code representations providing multiple input signals for learning to detect MVC groups based on textual, behavioral, and structural semantics. The MVC groups exhibit a range of different characteristics. A developer looking at the code for a controller would notice that it's more coupled than the average as it responds to user input and manages the flow between the model and view. However, the code for a component may not look as different from the others as it provides utility classes to the rest of the model. Reviewing the performance results with respect to these characteristics provides an opportunity to evaluate the machine-learning model to guide further improvements.
The classifier presented here is not accurate enough to put into production for design-pattern detection, but it demonstrates that machine learning can detect design patterns to some significant degree in support of the goal to reduce the cost of software quality evaluation. Future improvements in feature engineering will lead to far greater accuracy. Ultimately, a highly accurate and trusted MVC classifier could indicate MVC design-pattern nonconformance by spreading its prediction probability weight over two or more MVC groups, hinting that the file needs to be reorganized or split apart to cleanly conform with a single group in the MVC framework.
Details of Classifier Methods and Results
We describe here our methods and results, including partial details on
- the raw data that we used to train and test our classifier,
- the methods we used to identify numeric features for each file that could contain design-pattern information,
- the classifier that we used to predict a file's MVC group based on its numeric features, and
- an evaluation of the performance of the classifier.
Raw data: We reused 104 projects from the collection of open-source Java projects that Aniche and his colleagues previously labeled and analyzed at the file level with MVC group labels. Our projects in total contain about 54,000 files.
We split the data at the project level into a training set (71 projects) and a testing set (33 projects). Splitting at the project level (as opposed to randomly splitting among all 54,000 files) supports a rigorous evaluation of the classifier's accuracy by preventing the classifier from leveraging project-specific idiosyncrasies at test time. In particular, the performance metrics we report are plausibly representative of the performance on a never-before-seen Java repository following the Spring MVC framework.
The 71-projects training set includes more than 38,000 files while the 33-projects test set includes more than 15,000 files. The data are imbalanced, however, such that the least frequent of the six MVC groups, repository, is represented by 990 files in the training set and 283 files in the test set.
Feature engineering: The goal of feature engineering in this context is to identify numeric features for each file that hold information about the design patterns of the file. In our case, this was in the form of a vector of numeric features for each file, which we refer to as a file vector. We experimented with five groups of numeric features as outlined below and illustrated in Figure 3.
- (Classic CK metrics) Chidamber and Kremerer (1994) defined several measures of harmony between a sample of source code and the principles of object-oriented design (e.g., coupling between objects, lack of cohesion in methods). These metrics produce a file vector.
- (Entity relation counts) SciTools Understand is a static-analysis toolkit that computes a graph of several types of relationships among all the entities (e.g., variables, methods, classes) defined in the project. We extracted nearly 4,000 distinct types of (entity, relationship, entity) triples from the graphs of all the projects. An example of such a triple is (public method, use, private variable). We counted the appearances of each type of triple in a file to produce a file vector.
- (code2vec* on entity relations) We used Keras in Tensorflow 2.0 to refactor the code2vec neural network architecture and modified it slightly to predict MVC group at the file level, calling the result code2vec*. This architecture accepts a fixed-size collection of (entity, relationship, entity) triples as input; in this case we used a random sample of 200 triples for each file. We trained the network on our training set and then scored each file in both the training and test sets to obtain a file vector by extracting the activations of the penultimate layer of the network.
- (code2vec* on AST paths) Again following the methods of Alon and colleagues, we constructed the abstract syntax trees (ASTs) for every file and randomly sampled 200 (leaf node, connecting path, leaf node) triples and used these to train the code2vec* network and score each file just as we did with the (entity, relationship, entity) triples.
- (Pretrained code2vec) Finally, we applied a pretrained code2vec model (downloadable here). We trained this model to predict method elements, which may not be strongly related to MVC group, but our rationale was that the semantic information in predicting method names may overlap with design-pattern concerns. In addition, the pretrained model appears to have been trained on a far larger training set than we discussed here, such that the network should have learned semantics more deeply. As with code2vec* on AST paths, we used the pretrained model to generate a file vector based on a random sample of 200 AST paths from each file.

Figure 3: We used a variety of methods to produce five groups of numeric features that could contain information about the design patterns of each file.
Classifier: We trained several different instances of a gradient-boosting machine (specifically LightGBM) to estimate the MVC group label for each file. First we created five separate classifiers by training each one exclusively on one of the five feature sets introduced above. We then created a final "all features" classifier. Figure 4 reports the average performance, over the six MVC groups, with equal weighting, of each of these classifiers in terms of several popular metrics. Our main metric is the area under the precision-recall curve (AUPRC) because it (a) incorporates both precision and recall and (b) is insensitive to global miscalibration (unlike the F1 score), measuring the ability of the classifier to rank-order its probabilistic predictions of files belonging to an MVC group.
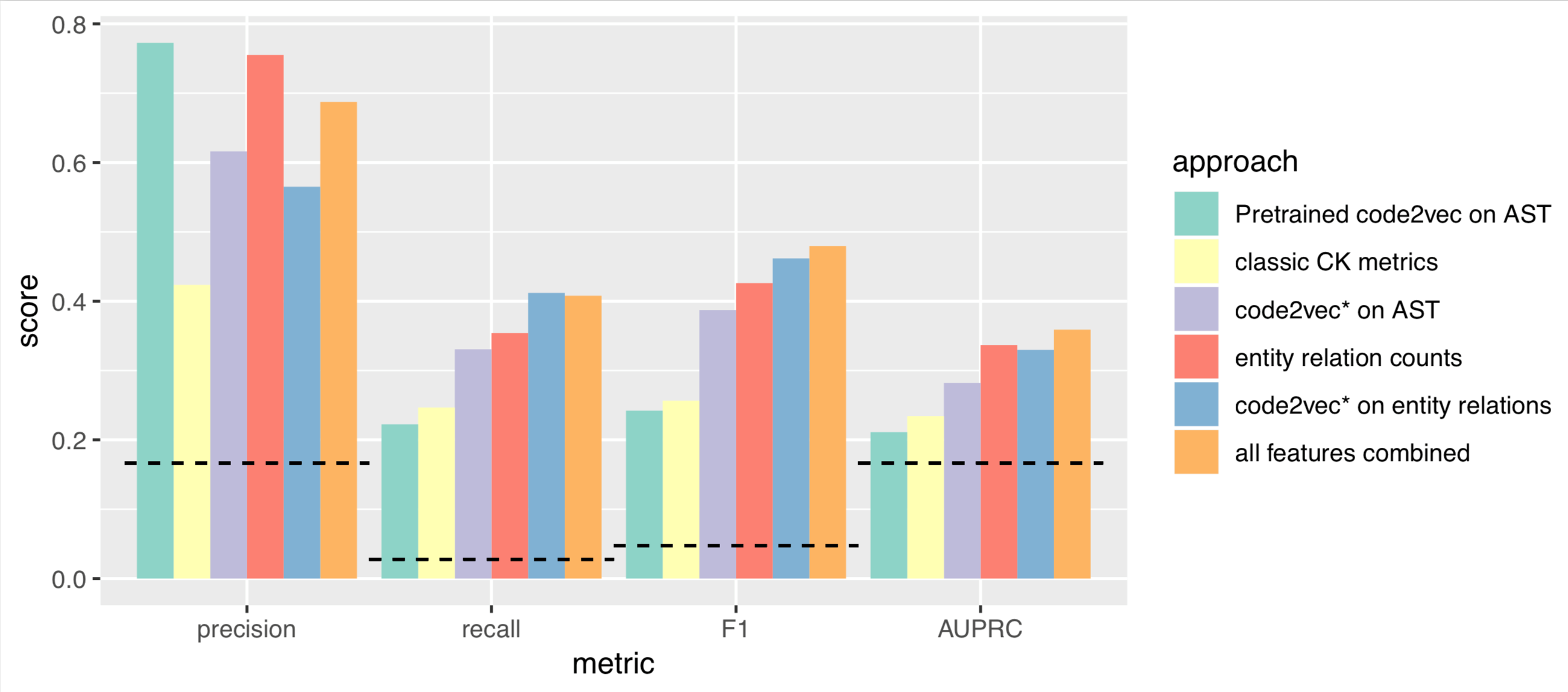
Figure 4: Average performance of each feature set in terms. The horizonal dashed line on each group indicates the baseline score for random guessing.
The performance results shown in Figure 4 are encouraging. The all-features model performs the best both in terms of the F1 and AUPRC metrics presumably because it has access to the most predictive features. Among the feature sets, the features based on entity-relation triples understandably do the best because these features capture MVC-style relationships between classes. The AST-based features do less well probably because we extracted AST features only within each file. We suspect that future work to extract features on a more global AST-like graph representation of the code over the entire repository will produce far more informative features with respect to the MVC design.
Discussion and Future Work
The work we presented above is not the first to automate the analysis of design patterns in source code. We were inspired by several threads of related work in the literature of machine learning for source code.
- Initial applications of machine learning for source code applied off-the-shelf machine-learning tools with hand-extracted features. The Metrics and Architecture Plugin for Eclipse (MARPLE) captures the context between design elements as microstructures in the code. It uses these structures (e.g., abstract class, abstract method invocation, and extended inheritance) to find correlations among code elements and roles or relations within design patterns. It detects simple single-level patterns well (e.g., Singleton and Adapter), but more complex multi-level patterns poorly; for example, the Composite pattern results in an F1 score of 0.56. The primary limitation to detecting more complex design patterns is potentially explained by the features that MARPLE uses to represent the code: the microstructures are hand-coded instead of being learned from representative code.
- Subsequent applications use the source code itself within machine learning drawing inspiration from natural language processing (NLP). NLP finds that modeling context around words improves performance. word2vec produces a vector space where words that share common context are located close to one another in the space. This preserves semantic relationships. doc2vec adds paragraph context to the word embedding to provide a representation for documents, which can dramatically improve performance for tasks that require capturing relationships at higher levels of abstraction.
- Current applications promise new machine-learning models informed by programming-language semantics. code2vec purports to achieve semantic understanding of source code because it can--with modest accuracy--predict the name of a method from the source code it contains. Although code2vec is observed to capture patterns well in the training data, its patterns are limited to those observable within isolated methods because code2vec uses paths along a method's AST to make its predictions. The representation therefore cannot capture the relationships between methods within a single class nor the relationship between classes.
Aligning the design of a system with its implementation improves product quality and simplifies product evolution. As abstraction in the form of design patterns increases, so does the challenge in detecting and analyzing the correct use of them. Bridging the abstraction gap is an important challenge to support automation that also requires bridging representations in design and code analysis and machine learning.
Our long-term vision is to create classifiers for not just one but many different types of design patterns. Ultimately, these classifiers would become the back end in a low-cost design-pattern conformance tool to (a) enable program managers to evaluate whether the implementation that is delivered matches the design that they contracted for in acquisitions of large-scale systems and (b) help guide software developers to engineer better source code during continuous integration and delivery, minimizing the accumulation of technical debt.
Additional Resources
Read the SEI blog post, The Vectors of Code: On Machine Learning for Software by Zachary Kurtz.
Read other SEI blog posts about machine learning.
Written By


More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed