Summarizing and Searching Video with Machine Learning

PUBLISHED IN
Artificial Intelligence EngineeringThe U.S. relies on surveillance video to determine when activities of interest occur in a location that is under surveillance. Yet, because automated tools are not available to help analysts monitor real-time video or analyze archived video, analysts must dedicate full attention to video data streams to avoid missing important information about ongoing activities and patterns of life. In tactical settings, warfighters miss critical information that would improve situational awareness because dedicating full attention to video streams is not feasible; for example, they may miss a telltale muzzle flash that gives away the location of an adversary while scanning the horizon for other forces. Moreover, video streams create mountains of data that currently require time- and resource-intensive human analysis before they can be used to advance the objectives of organizational missions.
In this blog post, I describe our efforts to improve the training of machine-learning algorithms for monitoring real-time video and analyzing archived video. These algorithms are intended to detect objects, track those objects more effectively, and recognize patterns of objects and object interactions.
Video Summarization and Search
Our goal in this project is to help analysts by increasing the volume of data that can be analyzed and providing insights into patterns of life that would be hard to identify otherwise. We concentrate on three core technologies to make video summarization and search possible in contexts that would be particularly useful to the DoD:
- Domain adaptation to address limitations of training data and improve object identification
- Geometry-aware visual surveillance to improve tracking of moving objects
- Pattern-of-life analysis to characterize the relationships and behaviors of those objects
Domain Adaptation
Despite impressive improvements in machine-learning systems in recent years, classifiers still do not perform as needed when there is little or no training data in the target environment. Solving machine-learning problems often starts with having sufficient data, but DoD datasets have limitations. They may not reflect future mission environments, they are often unlabeled, and there may be few examples of the target objects. Public datasets are not good analogs. There are semantic differences in perspective, scale, types of objects, and density of objects; texture differences due to varying environments; and differences in sensors and the metadata they produce.
Differences between the trained and real-world datasets hamper classifier performance. Performance hampering is particularly problematic in the tactical setting, where there is limited image data. Data from target environments may be scarce, or have few examples of object classes. Data may also be heterogeneous with regard to perspective, scale, and quality.

Figure 1: Influence of Training Data on Object Identification
This problem of inadequate training data is shown in Figure 1 above. In the image on the left, pretrained Microsoft common objects in context (COCO) weights were used, and they fail to classify many objects, probably because they have been trained using ground-level perspective. In particular, the photo demonstrates major problems with misclassifying building components as vehicles/personnel.
Our solution for domain adaptation is to use existing datasets to train a classifier for our new target domain. We stratify existing data to match the semantics of the target environment and use semantic information in the metadata of images to create a matched subset. We currently match only on object density, but in the future, we plan to expand to include other image features, such as perspective and scale.
For unsupervised style transfer between images and to match texture, we use CycleGAN, which uses machine learning to transform a set of images to appear more similar to another set of images. It can, for example, generate photos from paintings, turn horses into zebras, perform style transfer, and more.
For object detection and classification, we use Mask_RCNN trained on existing, labeled data that has had style transfer applied to it. We train Mask_RCNN classifiers using a combination of the original dataset, a small set of target data, and the adapted dataset.
Using a combination of adapted and target domain datasets for training, the photo on the right in Figure 1 shows significantly more objects correctly classified and only minor problems with misclassifying building components as vehicles or personnel. Our work suggests that with significantly different datasets, style transfer is insufficient to create a substitute for training data within the target domain. Moreover, supplemental data with or without style transfer to the target environment has shown minimal benefit as a supplement to target domain data.
After improved semantic matching, we can again ask if this observation holds where the target and source environments are semantically similar: after improved semantic matching, can the addition of supplemental data increase performance or act as a substitute for target data? Exploration of feature statistics indicates that automatic determination of object-identification quality may be possible.
Geometry-Aware Visual Surveillance
Tracking moving objects in a video is a fundamental problem in surveillance. This problem is made even more challenging if the camera is constantly moving, as it is in drone surveillance. Seen from the drone camera's perspective, everything is moving, including the ground (not just the object being tracked). As a result, tracking algorithms quickly lose the object or identify it as a different object.
In our work, we develop a pipeline that estimates camera motion on-the-fly while tracking, allowing us to "cancel" the camera motion before deploying our tracking algorithm. The tracker works by matching detected objects against future stabilized frames, with the help of a trajectory forecaster. Our geometry-aware object tracker stabilizes the 3D scene during tracking, improving its ability to match and forecast.
We operate on images from pairs of frames:
- Using the frames and the drone's approximate pose (height and angle from ground), we estimate the depth of each pixel.
- We stabilize for motion of the camera by reprojecting the 3D scene as it would look from a virtual camera placed in a stationary position.
- Using pairs of stabilized images, we create features for each image with a learned encoder-decoder.
- We crop the object to track from the ï¬rst feature map, and call this the template. Then we crop a relatively larger region from the second feature map and call this the search region.
- We cross-correlate the template with the search region, obtaining a map of possible matches.
- We reï¬ne the probability map using a velocity or trajectory estimate.
- We take the best unique match.
Our tracker achieves an average intersection over union (IOU) score of 0.7958 on our synthetic dataset, whereas a similar unstabilized tracker achieves 0.6428, as shown in Figure 2 below. In the future, we want to perform forecasting in this stabilized space, which we hope will further improve object detection and tracking.

Figure 2: Stabilization Improves Accuracy of Trajectory Information
Pattern-of-Life Analysis
Over the past five years, image recognition has improved dramatically thanks to new deep-learning architectures. It is now possible to start with a raw video feed and generate geo-located tracks of multiple human and nonhuman actors in real time. In the future, it will become possible to analyze raw video to identify and track objects, producing a new type of data that can serve as input to a form of downstream processing called pattern-of-life (POL) analysis.
In PoL analysis, we move from the question, "What is it?" to the question, "What is it doing?" At the lowest levels, a PoL analyzer might take track data for a set of objects and either identify targeted types of behaviors (e.g., roadblock, insurgents planting an improvised explosive device [IED], patrol of a compound, etc.), or report unusual or suspicious types of activity (i.e., anomaly detection). Higher level PoL analyzers might further refine these analyses to identify situations (e.g., compound with high value target).
While much progress has been made, real-time tracking is still an emerging technology. Tracks can be lost, or registration errors can occur. In addition, it is hard to obtain ground truth for this type of data. For these reasons, we have chosen to use simulation to generate synthetic patterns to explore the possibilities of PoL analysis with perfect data. We use the simulation of urban mobility (SUMO) traffic simulator and have explored both classification and anomaly-detection tasks using this data.
As image recognition and tracking algorithms improve, new types of data will emerge, enabling the design of higher order detectors, as shown in Figure 3:
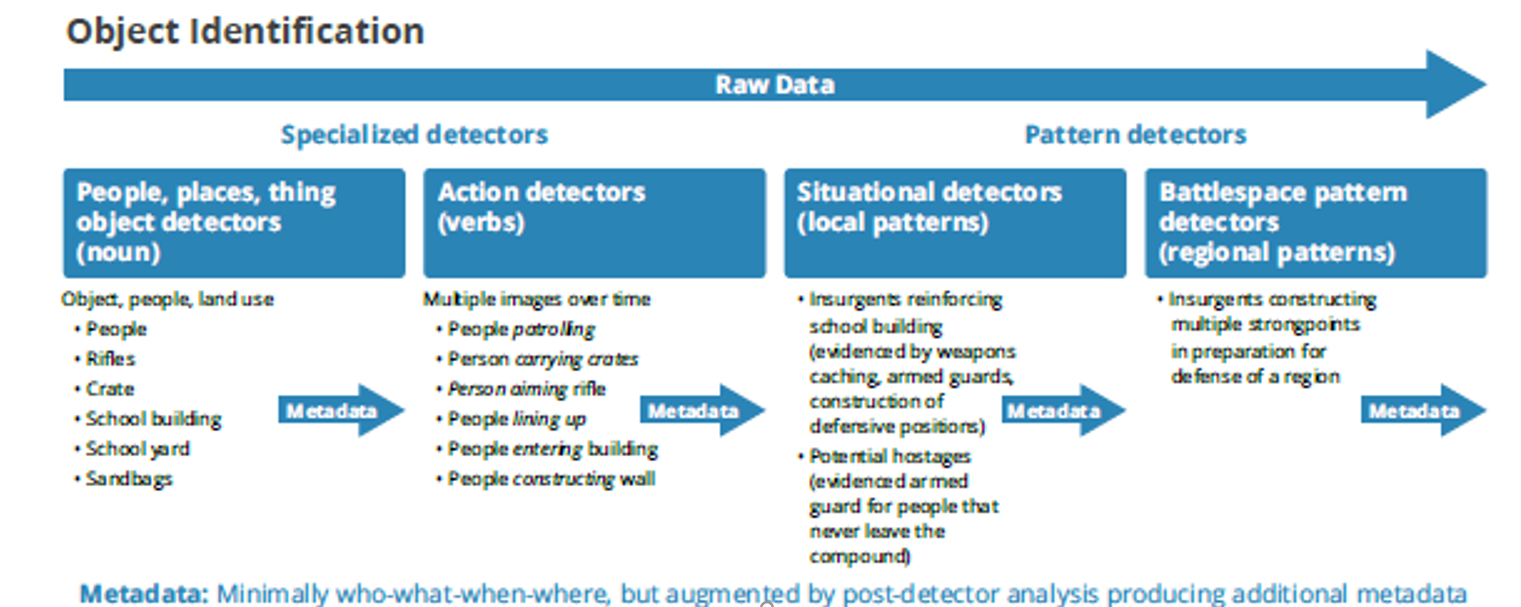
Figure 3: Pattern-of-Life Analysis: Hierarchy of Detectors
We have experimented with a "mall parking lot" example for using machine-learning techniques to analyze patterns of life. We analyzed simulated spaciotemporal tracks to identify specific types of activity.

Figure 4: PoL Mall Parking Lot Experiment
In Figure 4, the picture on the left shows a SUMO traffic simulator used to simulate vehicles and pedestrians including customers, employees, carpoolers, and drug dealers. In the picture in the center, for each track, we generated an ego-centric patch that is characterizing the movement of that vehicle or pedestrian and its relationship to other vehicles, pedestrians, and fixed reference points. The picture on the right shows how, using a convolutional neural network (CNN) classifier, we correctly identified the track type with 86 percent accuracy out of 10 possible classes.
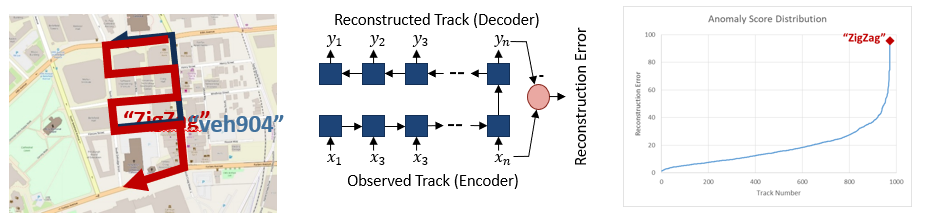
Figure 5: Anomaly Detection
In another experiment shown in Figure 5 above, we simulated 950 "best-path" vehicle trips into which we injected one with an unusual zig-zag path, shown in the picture on the left. We used an LSTM autoencoder to learn typical track behavior and compute a "reconstruction error" representing the degree to which a track is consider "unusual." Of the 950 tracks, our injected zig-zag track consistently scored in the top five in terms of reconstruction error, demonstrating the ability to identify anomalous behaviors.
We have recently applied our anomaly-detection approach to GPS tracks produced as "ground truth" for an exercise at a large training facility. The results are promising, with the approach identifying unusual automobile movements.
Wrapping Up and Looking Ahead
As this work progresses, we hope that increased training data for improved object identification, improved object tracking, and more faithful characterization of patterns of life will enable analysts to effectively process more data and identify more complex patterns. We are currently investigating a few short learning approaches to reduce the volume of training data necessary for building good classifiers. These approaches are designed to generalize to new tasks for which there are few examples for training from older tasks that have more training examples (in other words, to apply prior knowledge from old tasks to new). Ultimately, we anticipate a combination of approaches that makes the best use of existing data and synthetic data applied to new contexts in order to be useful.
Having demonstrated that our geometry-aware object tracker stabilizes the 3D scene during tracking, improving its ability to match objects and forecast positions, we are now investigating whether we can learn to track objects in 3D space without requiring training with 3D bounding-box annotations. The goal is to learn to track objects supervised only by moving and watching objects move.
Finally, we are expanding our research in anomaly detection to consider detection of anomalies involving multiple tracks and generating track predictions using context such as neighboring tracks. We intend to apply the approach to tracks detected by machine learning as object detection and tracking approaches improve.
Additional Resources
Read the SEI blog post, Video Summarization: Using Machine Learning to Process Video from Unmanned Aircraft Systems.
Read the SEI blog post, Experiences Using Watson in Software Assurance.
Read the paper, Applying video summarization to aerial surveillance.
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed