Experiences Using IBM Watson in Software Assurance

Since its debut on Jeopardy in 2011, IBM's Watson has generated a lot of interest in potential applications across many industries. I recently led a research team investigating whether the Department of Defense (DoD) could use Watson to improve software assurance and help acquisition professionals assemble and review relevant evidence from documents. As this blog post describes, our work examined whether typical developers could build an IBM Watson application to support an assurance review.
Foundations of Our Work
The team of researchers I work with at CERT--in addition to myself, the team includes Lori Flynn, and Chris Alberts--focuses on acquisitions and secure software development. We thought general assurance would be an appropriate area to test the cognitive processing of IBM Watson. Assurance often involves taking vast amounts of information--such as documentation related to mission, threats, architecture, design, operations, and code analytics--and examining them for evidence suggesting a particular question can be answered (e.g., is there a high level of confidence that this software module is free from vulnerabilities?).
Contracting offices and program managers review acquisition documents and artifacts for information related to risk. As software changes, these reviewers struggle to find assurance information related to changes in risk. Our aim was to see if we can feed Watson a large number of acquisition-related documents and have it use the information contained in those documents in a question-and-answer application.
We were also interested in determining whether this type of application could be developed with skill sets one would find in a typical organization that does software development. Our preliminary results suggested the following:
- A user does not need a Ph.D. in artificial intelligence or natural language processing to build a functional application hosted on Bluemix, the IBM cloud system hosting Watson software.
- A significant amount of time will be spent building the knowledge database, which IBM refers to as the "corpus." In our experience, as with other Watson developers we contacted, most of our time was devoted to building the knowledge database--far more than the application itself. Significant automation will be required for the corpus preparation and maintenance.
- A subject matter expert is needed to help structure the knowledge into chunks that a consumer could use. This was surprising because we had incorrectly assumed that, with natural language processing, Watson would be able to read a whole document and extract the relevant piece.
- End user involvement is needed to guide and improve training. The expert structures the knowledge, but then one needs to train the system so that it can answer the questions that might be posed by users. The use of certain keywords, phrases, and word ordering affects the ordering of answers delivered by the application. To make Watson most effective, it must be trained with the style and focus of questions employed by users. This training is accomplished by running human experiments with the system to elicit the types of questions to answer and then adding these new questions and appropriate answers to the data used to train Watson.
- For cognitive processing applications, such as the one we aspired to build, it is necessary to augment Watson with other tools. IBM Watson provides one particular type of capability, but Watson's cognitive processing must be coupled with other types of artificial intelligence capabilities and natural language processing capabilities to help build the corpus, update the data and training for the application, and expand the results to get the full application benefits.
Our Approach
Our aim with this project was to simulate a development process for building a Watson application using the skill set that would most likely be found in a federal agency or organization. We wanted to test a hypothesis that a development team did not require members who had advanced research experience in cognitive systems.
We focused our assurance questions around information generated during source code evaluation. Specifically, we focused on building a corpus of CERT Secure Coding Standards and MITRE's Common Weakness Enumerations (CWEs). The intent of our work was to answer a specific question about technology maturity. Moreover, our intent was to create a program and train Watson to continually ingest new information and respond to queries based on that information. To support continuous corpus updating and training, we needed to automate the preprocessing of standards and enumerations, and the creation of training questions and answers.
We assembled a team of CMU computer science students that included Christine Baek, Anire Bowman, Skye Toor, and Myles Blodnick. We picked team members who were experienced in Python, which we used to build the application, but we did not seek any special skills in natural language processing or artificial intelligence.
There were two phases to our work:
Preparatory phase. Three subject matter experts spent two weeks creating the strategy for organizing the information to be retrieved from the corpus. They also determined the types and subject focus of questions that a user would ask.
In this phase, we relied on the knowledge and experience of three SEI researchers with experience in secure coding and assurance. During this phase, our experts determined that we should focus our assurance questions around information gathered during source-code evaluations.
Our experts also developed sample training questions and answers, and they documented a fragmentation strategy for breaking rules and enumerations into answer-sized chunks that could be processed by Watson. These specifications drove the automation built by the development team.
Development phase. This phase took 11 weeks. Student developers built the application and the corpus, which included about 400 CERT rules and 700 CWEs.
Developing the corpus iterated through the following steps in each sprint:
- Scrape web pages from the CERT rules and CWEs to be used for the corpus. Because these web sites are continuously evolving, the automation of scraping allowed us to quickly use the most recent information. The scrapers are Python scripts. The CERT rules scraper identifies URLs for each of the coding rules for C, Java, C++, and Perl. It parses the coding standards for those languages starting from the SEI CERT Coding Standards landing site and then traverses subsections of each of those standards, eventually identifying a URL for each rule. For each URL, the source code of the web page for that rule is downloaded. For CWEs, the entire set of weaknesses is downloaded by the user in one file from https://cwe.mitre.org/data/slices/2000.html. Our parser for CWE uses this data for each weakness.
- Identify and format inputs to expand corpus. We performed two types of processing. First, we split the web page into many logical fragments. The selection of fragments was driven by the SME specification that defined the most useful information to be extracted from a web page, which would be used to answer questions that would be expected about a rule or weakness. Each rule or weakness typically resulted in 11 Solr documents, the storage system (a NoSQL database) processed by Watson. Second, we scraped web pages for elements of interest only and modified the format and content of those elements so the data we stored was relevant and uniform, and also labeled and formatted the data as required to interact properly with Watson.
- Update training. As the size of the corpus grew and test results were analyzed, we expanded and modified the training questions and answers, to help Watson tune its algorithms.
- Revise schema and scraper. As new topics and pages were introduced, the concepts to be queried and the richness of new pages required that we expanded the corresponding metadata and automation.
Our project relied on the Watson Retrieve and Rank service, hosted on BlueMix.
We evaluated our application against the following factors:
- Recall, which refers to the fraction of relevant instances that are retrieved. We measure this quantity to analyze the system's selection of relevant set of documents to a query. We then used this measure to determine how well the system minimizes false negatives, i.e., makes sure that a relevant answer was not excluded. We analyzed returned results to determine the fraction of relevant answers (as identified in a "ground truth" file provided to Watson) that were actually returned in response to questions.
- Precision, which refers to the fraction of retrieved instances that are relevant. We use it to analyze the priority ordering of retrieved documents that answer a query. Precision measures how well the system minimizes false positives, i.e., makes sure that all of the retrieved answers were relevant to the question. For example, one precision measure involved determining how many of the top three answers in a "ground truth" file provided to Watson were also in the top five ranked results from Watson, over a series of questions. Another precision metric involved determining whether the order of the ranked returned answers was the same as that in the top five ground-truth-provided answers. Another precision metric we used involved checking if the majority of the returned ranked results referred to the rule or weakness the question was asked about.
To help evaluate the team's progress, we were lucky to engage Dr. Eric Nyberg, who was part of the original Jeopardy Watson project. Dr. Nyberg is a professor in Carnegie Mellon University's School of Computer Science and director of the Master of Computational Data Science Program. Dr. Nyberg provided helpful feedback on our automated training strategy and the use of human trainers to tune Watson. He suggested testing methods that we used, and others we hope to use in the future. He and his graduate student Hugo Rodrigues provided insight into natural language processing and artificial intelligence, along with good research paper references about the current state of automated question variation and generation research.
Example of a Query Application
As an example, we presented our coding-rule question-and-answer application with the following query:
What is the risk of INT33-C?
As illustrated in the figure below, with respect to recall, all six-of-six relevant answers were returned, so recall was good. On the precision front, the exact subtext describing risk was returned as the best document. All the documents our application returned were related to INT33-C but the cost of fixing the violation and the rule title are not related to the risk, so one precision metric is 6/8.
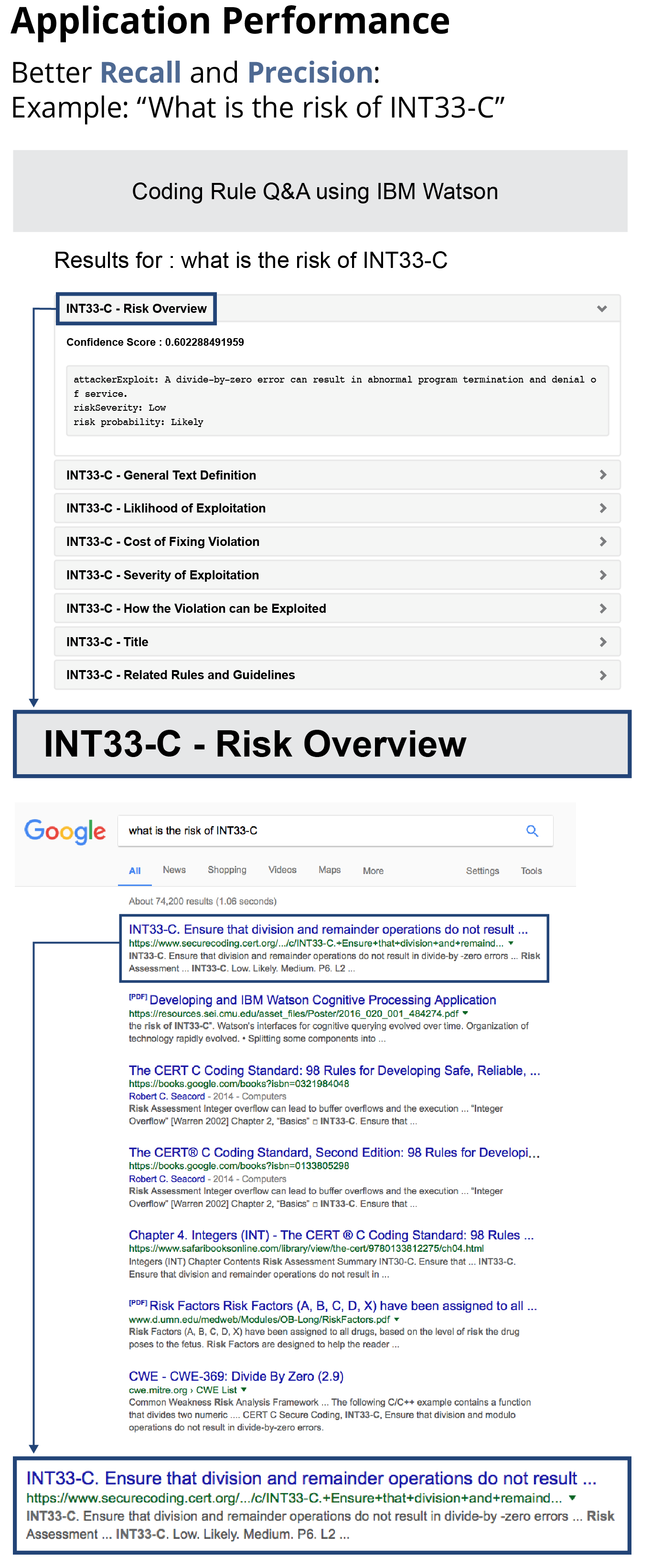
We then submitted that same query to Google, which returned an entire document with no subcomponents. Recall was spread across irrelevant documents, and the excerpt was imprecise. While not strictly an apples-to-apples comparison, the exercise provided evidence of the utility of using cognitive processing, in general, and of Watson, in particular.
Challenges and Lessons Learned
As stated earlier, we had a hard time achieving precision in developing our question-and-answer application. The following is a summary of our lessons learned on this project:
- The Watson platform required a tremendous amount of training and automation. To ensure that Watson had the best possible answer to a query, we created tools to convert approximately 1,000 original web-page documents into 15,000 Solr document fragments of potential answers. To train Watson in the desired level of precision, we similarly used automation to generate approximately 150,000 questions.
- Watson can only ask questions whose answer exists in a single particular document fragment. We incorrectly assumed that if Watson had one information artifact from one document and one information artifact from another document, it could assemble the two artifacts together and return them in response to a query.
- Watson is just one part of a cognitive processing application. The document fragmentation process, the training question-and-answer process, the answer delivery (visualization) process and the continuous training feedback process could all be improved by using additional cognitive processing to support their automation.
Wrapping Up and Looking Ahead
Having built our question-and-answer application, we found the corpus to be the most interesting artifact of our work. The government can acquire our corpus and our tools for any application. We have also licensed our database and supporting automation tools to SparkCognition in Austin, Texas, for use in their Watson-based applications.
The project expanded and deepened our skills in building cognitive processing and Watson applications. Watson, as well as the capabilities of other cognitive processing tools, continue to evolve. With the help of appropriate subject matter experts, the technology can be put into practice to solve DoD needs. Organizations interesting in collaborating with us should send an email to info@sei.cmu.edu.
We wish to acknowledge and thank IBM and SparkCognition for discussions on our approach to Watson application development.
We welcome your feedback on our work in the comments section below.
Additional Resources
View a video of Mark Sherman discussing his work at the 2016 SEI Research Review.
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed