Introducing MLTE: A Systems Approach to Machine Learning Test and Evaluation


PUBLISHED IN
Artificial Intelligence EngineeringWithout proper testing, systems that contain machine learning components (ML-enabled systems, or ML systems for short) can fail in production, sometimes with serious real-world consequences. Testing these systems can help determine if they will perform as expected—and desired—before going into production.
However, ML systems are notoriously difficult to test for a variety of reasons, including challenges around properly defining requirements and evaluation criteria. As a result, there are currently few accepted best practices for testing ML systems. In this blog post, we introduce Machine Learning Test and Evaluation (MLTE), a new process and tool jointly developed by SEI and the Army AI Integration Center (AI2C) to mitigate this problem and create safer, more reliable ML systems.
Problems in ML Development
In our research into challenges faced during test and evaluation (T&E) of ML systems, we noted three common issues in the ML model development process that are barriers to effective T&E processes.
- Communication barriers between product development team members. Team members are often siloed across organizations, leading to problems in gathering requirements and communicating model evaluation results.
- Documentation problems for ML model requirements. Documenting requirements is often a challenge for organizations, and documentation for ML system requirements is challenging to produce and often missing or low quality.
- Evaluating requirements. Even if requirements are properly defined and documented, there is no ML-specific method for implementing and evaluating them.
To address these challenges, we designed MLTE to help teams more effectively negotiate requirements, document, and evaluate ML systems.
How does MLTE Work?
MLTE is both a process that facilitates the gathering and evaluation of requirements for ML systems, and a tool to support the T&E process. The MLTE process includes several major steps and principles:
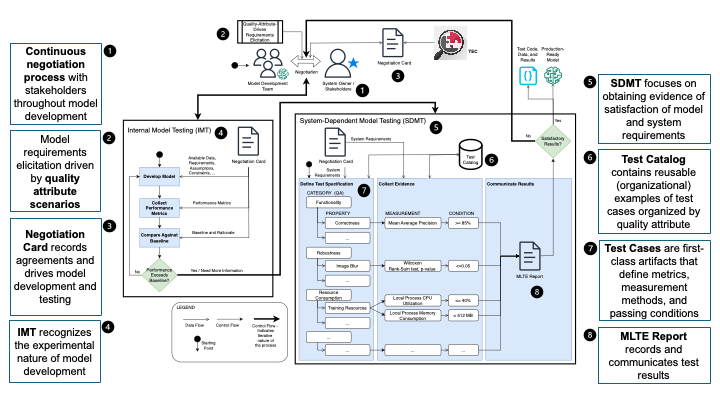
- Continuous negotiation. One of the main goals of MLTE is for developers and other stakeholders to be able to clearly discuss requirements throughout the development process and communicate the results of T&E.
- Negotiation cards. As part of the negotiation, teams fill out a MLTE negotiation card which allows them to record agreements and that drives model development and testing. Negotiation cards are used throughout the whole process to guide each step and provide a reference for all generated artifacts.
- Quality attribute (QA) scenarios. A major piece of the negotiation card are the QA scenarios, developed by the team as part of the requirements gathering process. QA scenarios specify the desired model quality requirements and are used to define test cases to determine if these requirements have been met. Teams select which quality attributes are the most important to their project to create the scenarios that apply to them. QA scenarios are defined from a system-level perspective to specify how the ML model should behave when integrated into the system that will use it.
- Internal model testing (IMT). Using information from the negotiation card, teams begin the IMT process of developing an initial model and testing it against the baseline performance requirements. The negotiation card can be refined as needed in this step.
- System-dependent model testing (SDMT). When a model performance exceeds the baseline requirements, the process moves to the SDMT stage. In this step, testing determines if a model will function as intended as part of a larger system. Teams start by defining a test specification based on the QA scenarios, converting them into code with measurable conditions that will have to be validated. After defining the MLTE test specification, teams create tests with the help of the test catalog to measure the behavior of the model and determine if the model satisfies the requirements. The test catalog contains test code examples that can be reused by model developers to define their own test cases.
- A MLTE report. After teams execute the test cases, they can produce a report to communicate the test results and examine the findings. If the test results are satisfactory, the evaluation is complete, and the model can be considered production ready. If more testing is required, stakeholders should reevaluate the requirements and renegotiate if necessary.
MLTE in Action
We have included demo notebooks in our GitHub repository to illustrate how MLTE works. In these demos, we evaluate an ML system used to identify flowers in botanical gardens based on pictures taken by visitors. We have simplified the details below, but you can view the full demo in our repository. Both demo notebooks in the repository operate only using the MLTE library for simplicity purposes. MLTE also includes a frontend that is the preferred method for viewing and editing negotiation card and other artifacts.
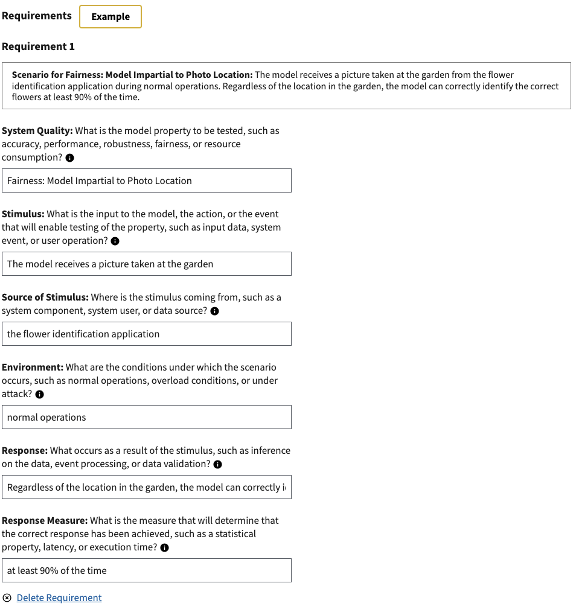
For this example, the team began by identifying the QA scenarios that are key to defining the ML model’s success. For example, the team determined that it was important for the model to correctly identify the correct flowers 90 percent of the time, regardless of where the photo was taken in the garden (fairness). Using these requirements, the team built out a negotiation card. The image below illustrates how the QA scenario appears in the negotiation card in the MLTE frontend.
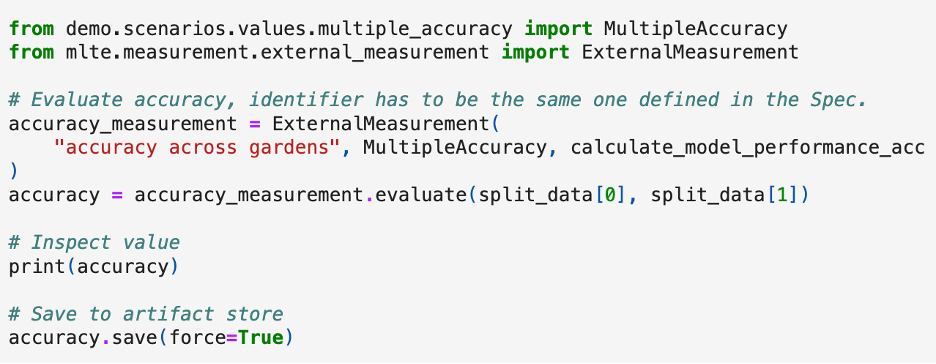
The team used a pre-existing model trained on flower categories as the resulting output of the IMT stage for the demo. The notebooks then define conditions and measurements derived from the QA scenarios for the SDMT phase, which are put together to create a MLTE test specification. The code snippet below shows part of this test specification. In this case, the quality attribute category (also called property) is Fairness, and within fairness the test is measuring a quality attribute for accuracy across different gardens. The condition to be evaluated is that a value of MultipleAccuracy has to be greater than 0.9.

For the next steps, there are demo notebooks that collect evidence to determine if the model meets the requirements. The code snippet below illustrates the process of evaluating the accuracy of the model across different data sets, and storing the result of the measurement, to be validated later against the conditions defined for that test:
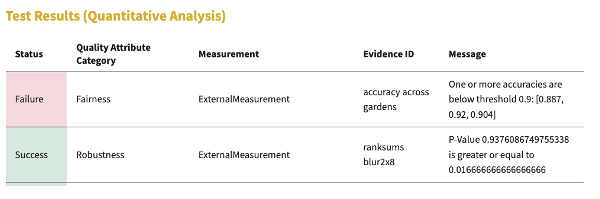
Once all of the evidence is collected, MLTE can automatically validate the measurement data from the tests against the test specification and generate a report to communicate the results. In this image of the report results in the MLTE frontend, we can see that the measurement for accuracy across gardens did not meet the test threshold condition, while the measurement for robustness did. From here, the team could decide to refine the model or the tests to improve the accuracy. This report also includes important pieces of information from the negotiation card and can be exported to be saved as a PDF.
Work with Us
MLTE can support ML projects from many disciplines and is designed to be extensible to suit differing user needs. Contact us if you would like help instantiating MLTE within your organization. We welcome feedback through email or GitHub issues.
Additional Resources
Download MLTE from GitHub.
Read the paper "MLTEing Models: Negotiating, Evaluating, and Documenting Model and System Qualities."
Read the paper "Using Quality Attribute Scenarios for ML Model Test Case Generation."
Written By



More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed