Inference of Memory Bounds: Preventing the Next Heartbleed

Invalid memory accesses are one of the most prevalent and serious of software vulnerabilities. Leakage of sensitive information caused by out-of-bounds reads is a relatively new problem that most recently took the form of the Open SSL HeartBleed vulnerability. In this blog post, I will describe research aimed at detecting the intended bounds of memory that given pointers should be able to access.
Automated Code Repair
Automated code repair cuts the cost of addressing software vulnerabilities by making more effective use of existing human programming resources, reducing a system's attack surface, and improving system resilience.
The work Will Snavely, Cory Cohen, and I have undertaken on this project aims to develop an algorithm that automatically infers the bounds of memory regions intended to be accessible via specific pointer variables and repair certain memory-related defects in software. The results of this work will help the Department of Defense (DoD) improve software assurance of existing code at a fraction of the cost of manual inspection and repair. Specifically, our work focuses on detecting the intended bounds of memory that given pointers should be able to access.
In addition to traditional buffer overflows, we will tackle leakage of sensitive information caused by out-of-bounds reads, which are a relatively newer problem that is unaffected by mitigations such as address-space layout randomization (ASLR) and data execution prevention (DEP).
According to Common Weakness Enumeration, a community-developed list of software weakness types, an out-of-bounds read occurs when
The software reads data past the end, or before the beginning, of the intended buffer.... This typically occurs when the pointer or its index is incremented or decremented to a position beyond the bounds of the buffer or when pointer arithmetic results in a position outside of the valid memory location to name a few.
In general, reads should be bounded to the valid portion of the buffer for a reusable buffer with stale data. The problem of out-of-bounds reads affects even memory-safe languages, such as Java. For example, the Jetty web server (written in Java) had a vulnerability (nicknamed "JetLeak") that could leak passwords, authentication tokens, and any other data contained in an HTTP request (CVE-2015-2080). Figure 1 illustrates this type of situation. After processing an initial request, the buffer is tainted with sensitive data from this request. Then, supposing the server processes a second, smaller request, the upper bound for reading from the buffer should be the last written location (i.e., the location that was most recently written to), which corresponds to the end of the second request.
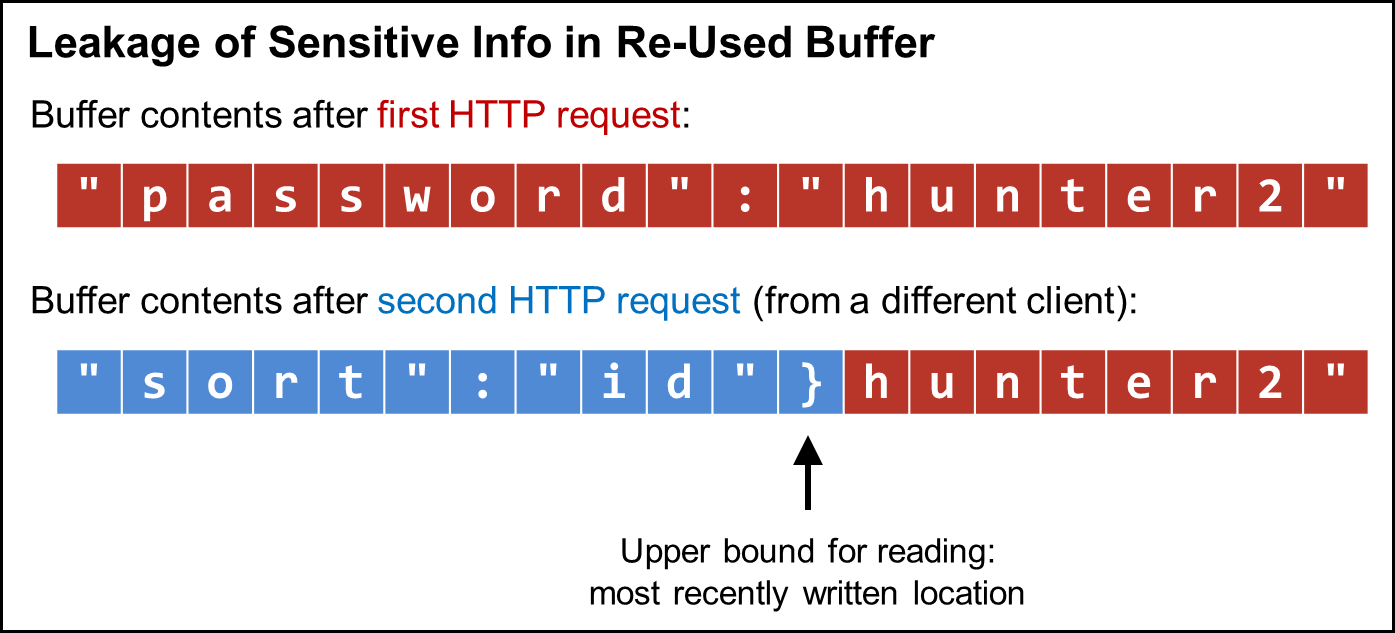
Figure 1: Leakage of sensitive information in a re-used buffer
Generalizing from the above example, we say that an array is a qualifying array if every write to the array is at either index 0 or at the successor of the last written position (LWP). As a heuristic, our assumption is that the valid portion of the array continues from the start of the array up to and including the LWP, and that any read beyond the LWP is an invalid read. This raises the following question: "How often do qualifying arrays occur in real-world programs?" To establish the ground truth, we have designed a dynamic analysis that
- records, for each allocated array, the allocation site (i.e., the location in the program text at which the memory was allocated) and the last written position (LWP)
- checks whether each write to an array is consistent with the definition of qualifying array
- flags any reads beyond the LWP of an array if all previous writes to the array have been consistent with the definition of qualifying array
- produces a summary of which arrays are still qualifying and have flagged reads at program termination
A finite-state machine representing this analysis is shown in Figure 2. We have implemented a few versions of this analysis:
1) a version for C/C++ using SAFECode
2) another version for C/C++ using a combination of Clang's Address Sanitizer and Intel's Pin tool
3) a version for Java using a Java agent to instrument ByteBuffers

Figure 2: Representation as a finite-state machine
Our dynamic analysis can also be used for runtime bounds enforcement by terminating the program upon a flagged read. We have used this technique to dynamically patch a vulnerable version of Jetty. As shown in Figure 3, when an attacker sends a specially crafted malformed request, Jetty builds an error message to return to the attacker. But there is a bug in the Jetty error-handling code that causes sensitive data from a previous request (from a different client) to be returned to the attacker. As shown in Figure 4, our dynamic patch intercepts the invalid read and terminates Jetty, so that the attacker receives no response.
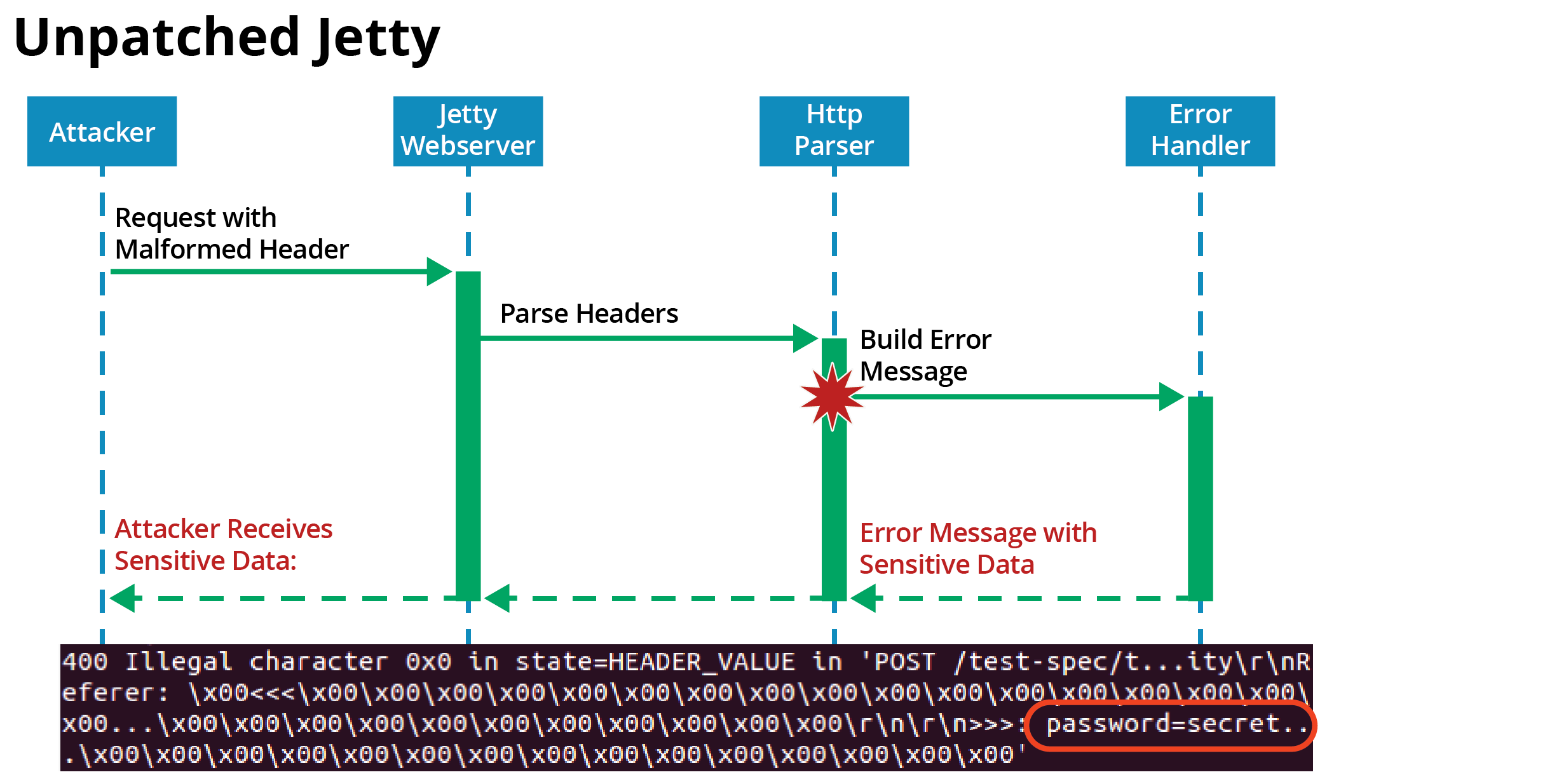
Figure 3: Attack on unpatched Jetty
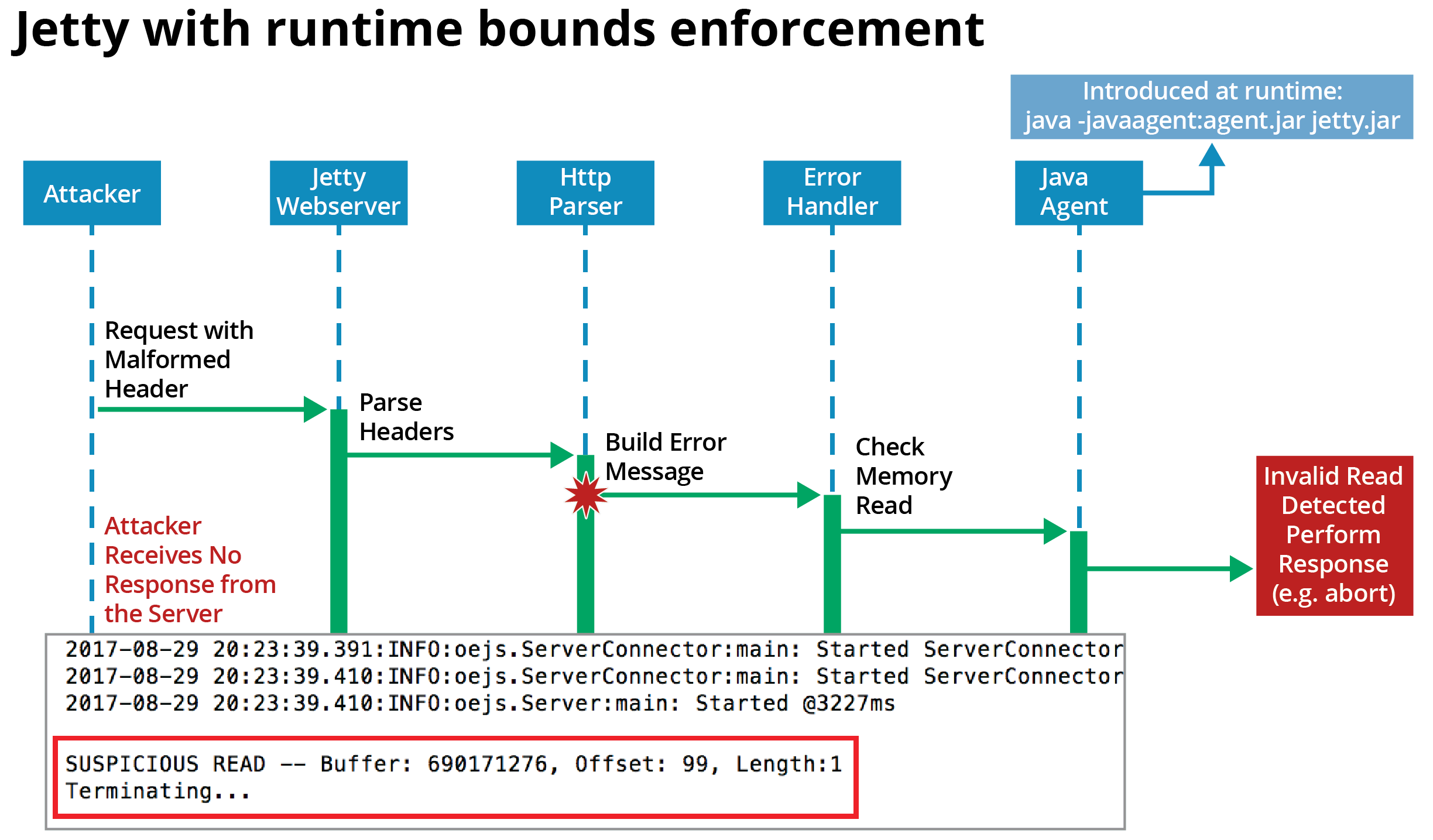
Figure 4: Attack on dynamically patched Jetty
Unfortunately, false positives are a problem with the above-described runtime enforcement: An array can, at first, coincidentally satisfy the definition of qualifying array but later turn out to be non-qualifying. To address this problem, we can perform a two-step process: 1) identify candidate bounds checks (either via static analysis or the above dynamic analysis), and then 2) perform a second dynamic analysis to weed out bad bounds checks. This second dynamic analysis proceeds as follows:
- We instrument the program to record which, if any, candidate bounds checks fail.
- We run the instrumented program to collect good traces (i.e., traces on which the program exhibits desired behavior). We try to get as close to complete coverage of the code as possible. To do this, we can use test cases and/or run the program in an actual environment.
- We divide the candidate bounds into three categories:
- Strongly supported: Many traces where the bounds check succeeded, with values near the bounds, and no failed checks.
- Likely incorrect: Some traces where the bounds check failed.
- Indeterminate: Insufficient log data about the check to place it into either of the two above categories.
- We discard bounds checks that aren't strongly supported. Optionally, results may be audited manually if there is reason to believe that failed bound checks might be suspicious (e.g., if bounds checks failed in only a very small percentage of traces).
For runtime enforcement, we repair the program to insert bounds checks, unless we determine via static analysis that the check is always satisfied.
The bounds-checking code can either soft-fail (just log an error message) or hard-fail (abort execution). If bounds checks are not manually verified, an organization would be encouraged to first use soft-fail in production and then, if no failures are logged, to switch to hard-fail.
Wrapping Up and Looking Ahead
Invalid memory accesses are one of the most prevalent and serious software vulnerabilities. Our work to address memory safety is part of our larger body of work on automated code repair. Our ultimate goal is to enable cost-effective remediation of defects in large DoD codebases.
This work is the first part of a four-year project on automated repair to enable a proof of memory safety. We welcome your feedback on this work in the comments section below.
Additional Resources
Read the SEI Blog Post that I co-authored with Will Snavely on Automated Code Repair in the C Programming Language.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed