Automated Code Repair to Ensure Memory Safety

Memory-safety vulnerabilities are among the most common and most severe types of software vulnerabilities. In early 2019, a memory vulnerability in the iPhone iOS, reportedly exploited by the Chinese government, allowed attackers to take control of a phone when the user visited a malicious website. A similar vulnerability discovered in the Android Stagefright library allowed an attacker to gain control simply by sending a Multimedia Messaging Service (MMS) message to a vulnerable phone. For each of the past three years, the Common Weakness Enumeration (CWE) category for spatial memory violations (CWE-119) have been the most or second most frequent type of Common Vulnerabilities and Exposures (CVEs) recorded in the NIST National Vulnerability Database. In the past three years combined, spatial memory violations composed 24 percent of the critical-severity CVEs and 15 percent of all CVEs. In this blog post, we present research that aims to develop automated techniques to repair C source code to eliminate memory-safety vulnerabilities.
Our Approach
Existing static-analysis tools try to detect memory vulnerabilities, but they either report an enormous number of false alarms or fail to report true vulnerabilities. Consequently, teams are able to eliminate only a fraction of the vulnerabilities. Therefore, codebases often contain an unknown number of security vulnerabilities.
In our latest work on automated code repair, we have designed and implemented a technique for automatically repairing, in the source code, all potential violations of spatial memory safety (modulo the limitations described later in this blog post). We do not need to solve the challenging problem of distinguishing false alarms from true vulnerabilities: we can simply repair all potential memory safety vulnerabilities, at a cost of an often small runtime overhead. Our approach inserts code to abort the program (or call a user-specified error-handling routine) immediately before a memory violation would occur, ensuring that attackers are no longer able to exploit the program.
As I described in a previous post, static analysis to detect defects works best on an intermediate representation (IR), such as LLVM's IR. Furthermore, it is often advantageous to perform certain optimization passes, such as converting to static single assignment (SSA) form. To enable subsequent translation of the repaired IR back to source code, we record the correspondence of source code to IR during the forward translation (source -> IR), and we annotate the IR with this information.
There has been a significant amount of previous work on adding safety checks as part of the compilation process. Our work is novel in that it repairs the original source code such that the result is human-readable and maintainable. Some advantages of source-level repair are shown below in Table 1.

Table 1: Benefits of repair of source code,
compared to repair as a compiler pass
Usually, only a small percentage of a codebase is performance critical. Repairs to this part of the codebase might require manual tuning, but with an amount of effort much less than that of manually repairing all potential memory-safety vulnerabilities in the codebase.
For this work, we are collaborating with Dr. Ruben Martins, a systems scientist in Carnegie Mellon University's (CMU's) School of Computer Science, whose research interests include constraint solving, program synthesis, program analysis, and program verification. Martins is working to reduce the number of false alarms in our tool by using program analysis and invariant inference. His goal is to reduce the overhead (in time and memory) imposed by repairs. Martins is also using formal-verification tools, such as Symbiotic, to verify that our tool really does ensure memory safety on benchmark programs.
Our tool is designed for use as both a one-shot repair on legacy codebases and to periodically repair an in-development codebase, as part of a DevOps toolchain.
Pipeline for Repair of Source Code
Our pipeline for the repair of source code is shown below:
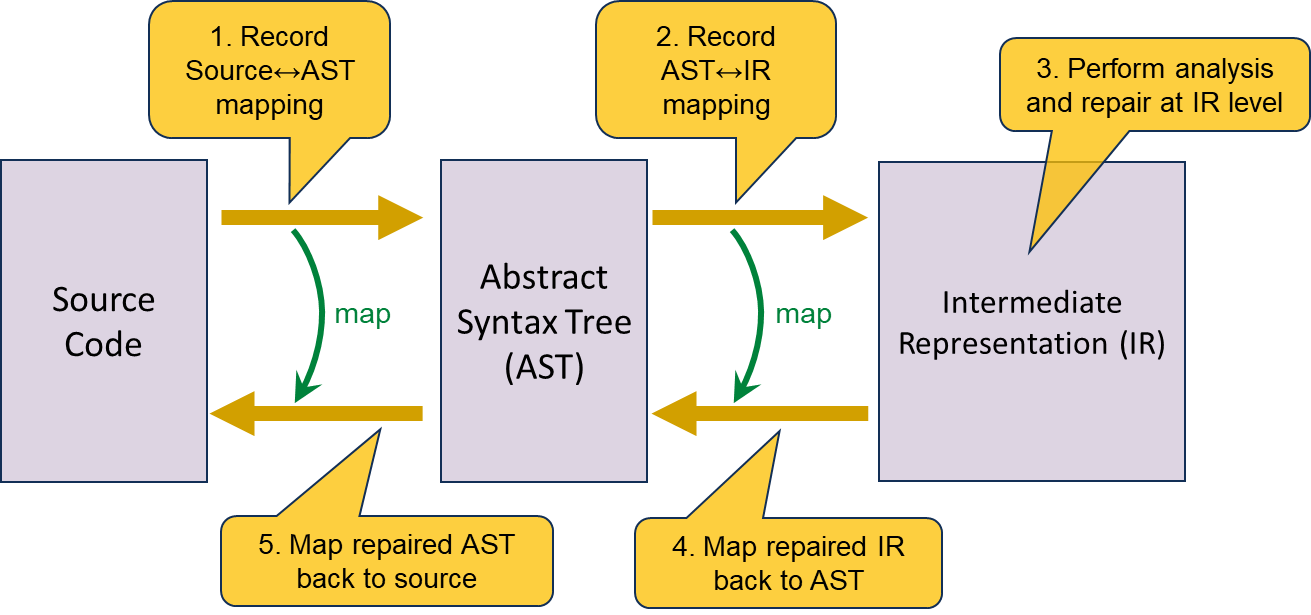
- The source code is parsed into an Abstract Syntax Tree (AST), and we record the source<->AST mapping. Specifically, we annotate each AST node with the corresponding range of original (unpreprocessed) source code.
- The AST is transformed to IR, and the IR is annotated with information about how to transform the IR back to the original AST.
- The IR is analyzed and repaired.
- The repaired IR is transformed back to an AST using the annotations.
- Our IR-to-AST transformation is sound (semantics-preserving) by construction. - The repaired AST is transformed back to source code.
- If an AST node is unmodified, the corresponding original source text is used. Otherwise, new source code is generated from the modified AST node.
- Due to the complexities of the C preprocessor, we have not been able to ensure that our technique will always faithfully reconstruct the source code file; for example, if an #ifdef ... #endif block encloses a syntactically ill-formed fragment, it is possible that our tool will remove the #ifdef but not the #endif (or vice versa), resulting in invalid code. Instead, we make a best-effort attempt and then verify that Clang parses the resulting source code into an AST that is equivalent to the AST from which source code was reconstructed. In the rare event that reconstructed source code fails to compile to an equivalent AST, the tool will notify the user of the failure.
Our tool currently works on the SVCOMP memory-safety benchmarks. We are adding missing features to handle the SPEC2006 benchmarks.
Fat Pointers
As part of our approach, we ensure special memory safety by replacing raw pointers with fat pointers, which include bound information. A fat pointer is a structure containing three fields: the raw pointer itself, the base of the memory region, and the size of the memory region, in bytes. Our tool inserts code to perform a bounds check immediately before dereferencing a fat pointer.
For each pointer type T*, we introduce a fat-pointer type defined as follows:
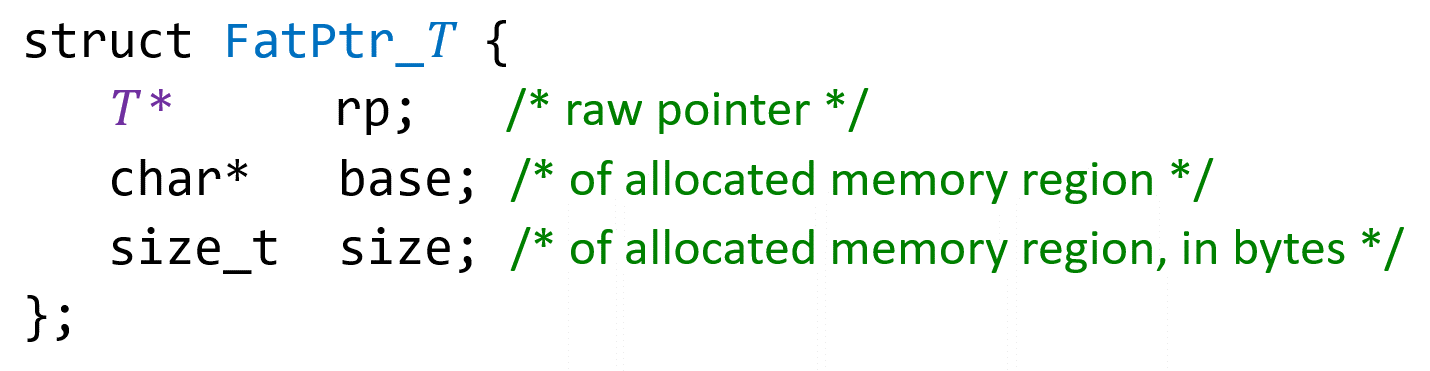
Previous work including that of Todd Austin et al. and Wei Xu et al. have performed fattening of pointers as a compiler pass. Our work is novel in that it makes human-readable repairs to the source code rather than only producing repaired executable code.
The figure below shows the output of our tool when run on example source code.

Limitations of Our Approach
One limitation of our approach is that there is no guarantee of memory safety in the presence of concurrency. For example, consider a race condition in which one thread non-atomically overwrites a fat pointer in a memory location and concurrently another thread non-atomically reads a fat pointer from the same memory location. In this scenario, the reading thread may read an invalid value in which only some of the fields of the fat-pointer struct have been updated by the writing thread.
Another limitation of our approach is that we only fatten those pointers that we can statically determine are safe to fatten (by "safe", we mean that the required changes to the program's memory layout and function signatures won't break any code). Examples of program features that may render pointers ineligible for fattening include:
- external code that accesses program memory or returns pointers
- non-standard pointer tricks (e.g., XOR-linked lists)
- reuse of memory for different types (except via unions)
- dynamically loaded code, including code compiled just in time (JIT)
Multiple Build Configurations
The C preprocessor can conditionally include or exclude pieces of code depending on the configuration chosen at compile time. Examples of options specified in a configuration include:
- target platform (e.g., Windows, Linux, etc.)
- including or excluding certain features (e.g., FIPS-compliant mode in OpenSSL)
- debug vs. release mode
We repair configurations separately and then merge the results such that the final repaired source code is correct under all desired configurations.
Wrapping Up and Looking Ahead
Our focus at the SEI is on making software trustworthy in construction and correct in implementation. Our long-term aim with this body of work is to develop a tool that the Department of Defense (DoD) can use to ensure memory safety, both spatial and temporal, for all software projects with code written in memory-unsafe languages, such as C and C++.
In the near term, we are focusing on
- adding features and fixing remaining bugs so that our tool handles all of the C language and gcc/clang extensions that are commonly used in real-world code
- optimizing to remove unnecessary bounds checks and fattenings
- working with DoD transition partners to evaluate our tool for DoD use
Please feel free to contact us if you're interested in partnering with our research efforts.
Additional Resources
Read the blog post Automated Code Repair in the C Programming Language that I coauthored with Will Snavely.
Listen to the podcast Is Java More Secure Than C? by David Svoboda.
Read the blog post Prioritizing Alerts from Static Analysis to Find and Fix Code Flaws by Lori Flynn.
Read the SEI technical note Improving the Automated Detection and Analysis of Secure Coding Violations.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed