Cultivating Kubernetes on the Edge


PUBLISHED IN
Continuous Deployment of CapabilityEdge computing is now more relevant than ever in the world of artificial intelligence (AI), machine learning (ML), and cloud computing. On the edge, low latency, trusted networks, and even connectivity are not guaranteed. How can one embrace DevSecOps and modern cloud-like infrastructure, such as Kubernetes and infrastructure as code, in an environment where devices have the bandwidth of a fax machine and the intermittent connectivity and high latency of a satellite connection? In this blog post, we present a case study that sought to import parts of the cloud to an edge server environment using open source technologies.
Open Source Edge Technologies
Recently members of the SEI DevSecOps Innovation team were asked to explore an alternative to VMware’s vSphere Hypervisor in an edge compute environment, as recent licensing model changes have increased its cost. This environment would need to support both a Kubernetes cluster and traditional virtual machine (VM) workloads, all while being in a limited-connectivity environment. Additionally, it was important to automate as much of the deployment as possible. This post explains how, with these requirements in mind, the team set out to create a prototype that would deploy to a single, bare metal server; install a hypervisor; and deploy VMs that would host a Kubernetes cluster.
First, we had to consider hypervisor alternatives, such as the open source Proxmox, which runs on top of the Debian Linux distribution. However, due to future constraints, such as the ability to apply a Defense Information Systems Agency (DISA) Security Technical Implementation Guides (STIGs) to the hypervisor, this option was dropped. Also, as of the time of this writing, Proxmox doesn’t have an official Terraform provider that they maintain to support cloud configuration. We wanted to use Terraform to manage any resources that had to be deployed on the hypervisor and didn’t want to rely on providers developed by third parties outside of Proxmox.
We decided to choose the open source Harvester hyperconverged infrastructure (HCI) hypervisor, which is maintained by SUSE. Harvester provides a hypervisor environment that runs on top of SUSE Linux Enterprise (SLE) Micro 5.3 and RKE Government (RKE2). RKE2 is a Kubernetes distribution commonly found in government spaces. Harvester ties together with Cloud Native Computing Foundation-supported projects, such as KubeVirt and Longhorn. Using Kernel Virtual Machine (KVM), KubeVirt enables the hosting of VMs that are managed through Kubernetes and Longhorn and provide a block storage solution to the RKE2 cluster. This solution stood out for two main reasons: first, the availability of a DISA STIG for SUSE Linux Enterprise and second, the immutability of OS, which makes the root filesystem read only in post-deployment.
Creating a Deployment Scenario
With the hypervisor selected, work on our prototype could begin. We created a small deployment scenario: a single node would be the target for a deployment that sat in a network without wider Internet access. A laptop with a Linux VM running is attached to the network to act as our bridge between required artifacts from the Internet and the local area network.
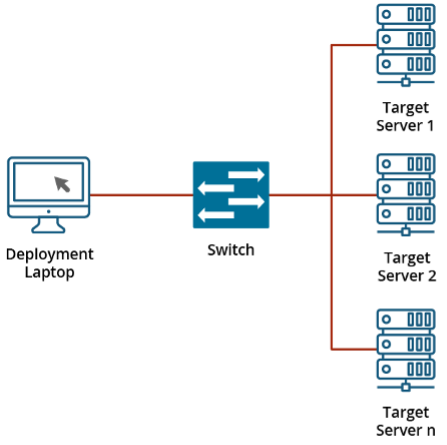
Harvester supports an automated install using the iPXE network boot environment and a configuration file. To achieve this, an Ansible playbook was created to configure this VM, with these actions: install software packages including Dynamic Host Configuration Protocol (DHCP) support and a web server, configure these packages, and download artifacts to support the network install. The playbook supports variables to define the network, the number of nodes to add, and more. This Ansible playbook helps work towards the idea of minimal touch (i.e., minimizing the number of commands an operator would need to use to deploy the system). The playbook could be tied into a web application or something similar that would present a graphical user interface (GUI) to the end user, with a goal of removing the need for command-line tools. Once the playbook runs, a server can be booted in the iPXE environment, and the install from there is automated. Once completed, a Harvester environment is created. From here, the next step of setting up a Kubernetes cluster can begin.
A quick aside: Even though we deployed Harvester on top of an RKE2 Kubernetes cluster, one should avoid deploying additional resources into that cluster. There is an experimental feature using vCluster to deploy additional resources in a virtual cluster alongside the RKE2 cluster. We chose to skip this step since VMs would need to be deployed for resources anyway.
With a Harvester node stood up, VMs can be deployed. Harvester develops a first-party Terraform provider and handles authentication through a kubeconfig file. The use of Harvester with KVM enables the creation of VMs from cloud images and opens possibilities for future work with customization of cloud images. Our test environment used Ubuntu Linux cloud images as the operating system, enabling us to use cloud-init to configure the systems on initial start-up. From here, we had a separate machine as the staging zone to host artifacts for standing up an RKE2 Kubernertes cluster. We ran another Ansible playbook on this new VM to start provisioning the cluster and initialize it with Zarf, which we’ll get back to. The Ansible playbook to provision the cluster is largely based on the open source playbook published by Rancher Government on their GitHub.
Let’s turn our attention back to Zarf, a tool with the tagline “DevSecOps for Airgap.” Originally a Naval Academy post-graduate research project for deploying Kubernetes in a submarine, Zarf is now an open source tool hosted on GitHub. Through a single, statically linked binary, a user can create and deploy packages. Basically, the goal here is to gather all the resources (e.g., helm charts and container images) required to deploy a Kubernetes artifact into a tarball while there is access to the larger Internet. During package creation, Zarf can generate a public/private key for package signing using Cosign.
A software bill of materials (SBOM) is also generated for each image included in the Zarf package. The Zarf tools collection can be used to convert the SBOMs to the desired format, CycloneDX or SPDX, for further analysis, policy enforcement, and tracking. From here, the package and Zarf binary can be moved into the edge device to deploy the packages. ZarfInitPackageestablishes components in a Kubernetes cluster, but the package can be customized, and a default one is provided. The two main things that made Zarf stand out as a solution here were the self-contained container registry and the Kubernetes mutating webhook. There is a chicken-and-egg problem when trying to stand up a container registry in an air-gapped cluster, so Zarf gets around this by splitting the data of the Docker registry image into a bunch of configmaps that are merged to get it deployed. Additionally, a common problem of air-gapped clusters is that the container images must be re-tagged to support the new registry. However, the deployed mutating webhook will handle this problem. As part of the Zarf initialization, a mutating webhook is deployed that will change any container images from deployments to be automatically updated to refer to the new registry deployed by Zarf. These admission webhooks are a built-in resource of Kubernetes.
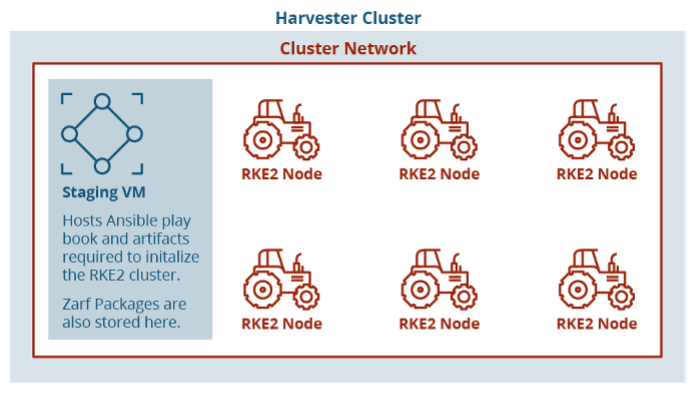
Automating an Air-Gapped Edge Kubernetes Cluster
We now have an air-gapped Kubernetes cluster that new packages can be deployed to. This solves the original narrow scope of our prototype, but we also identified future work avenues to explore. The first is using automation to build auto-updated VMs that can be deployed onto a Harvester cluster without any additional setup beyond configuration of network/hostname information. Since these are VMs, additional work could be done in a pipeline to automatically update packages, install components to support a Kubernetes cluster, and more. This automation has the potential to remove requirements for the operator since they have a turn-key VM that can be deployed. Another solution for dealing with Kubernetes in air-gapped environments is Hauler. While not a one-to-one comparison to Zarf, it is similar: a small, statically linked binary that can be run without dependencies and that has the ability to put resources such as helm charts and container images into a tarball. Unfortunately, it wasn’t made available until after our prototype was mostly completed, but we have plans to explore use cases in future deployments.
This is a rapidly changing infrastructure environment, and we look forward to continuing to explore Harvester as its development continues and new needs arise for edge computing.
Additional Resources
Read the SEI blog post Migrating Applications to Kubernetes by Richard Laughlin.
Written By




More By The Authors
More In Continuous Deployment of Capability
PUBLISHED IN
Continuous Deployment of CapabilityGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Continuous Deployment of Capability
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed