Automating Design Analysis

PUBLISHED IN
Software ArchitectureSoftware design problems, often the result of optimizing for delivery speed, are a critical part of long-term software costs. Automatically detecting such design problems is a high priority for software practitioners. Software quality tools aim to automatically detect violations of common software quality rules. However, since these tools bundle a number of rules, including rules for code quality, it is hard for users to understand which rules identify design issues in particular. This blog post presents a rubric we created that quickly and accurately separates design rules from non-design rules, allowing static analysis tool users to focus on the high-value findings.
Our team (myself, Stephany Bellomo, Rod Nord, and Ipek Ozkaya) conducted an empirical study using a structured categorization approach and manually classified 466 software quality rules from three industry tools: CAST, SonarQube, and Ndepend. We found that most of these rules were easily labeled as either non-design (55 percent) or design (19 percent). The remainder (26 percent) resulted in disagreements among the labelers.
Our results are a first step in formalizing a definition of a design rule, to support automatic detection and ultimately, to reduce technical debt. This blog post, which is excerpted from a paper detailing this work, presents the latest installment in our ongoing research on technical debt and the results of our analysis on distinguishing between design and non-design rules in automated tools.
An Emphasis on Code-Level Rules over Design
Static analysis tools evaluate software quality using rules that cover many programming languages, quality characteristics, and paradigms. The first tool to automate rule checking was the C language tool lint in 1979. Since that time, static analysis tools have traditionally focused on what many developers would call the "code-level" rather than design-level concerns.
A challenge for users of static analysis tools is making sense of the results. Static analysis tools often generate many false positives, leading developers to ignore the results. One way to address this problem that we believe shows promise is separating design rules from non-design rules.
Separating Design from Non-Design Rules
Our research focused on how some current tools detect design and paradigm level violations. In particular, we identified two questions:
- What is a design-related rule?
- What kind of design-related rules do common tools provide?
To make possible the labeling of a given quality rule as either design or non-design, we created a classification rubric for evaluating design rules.
The figure below shows our final version of the rubric.
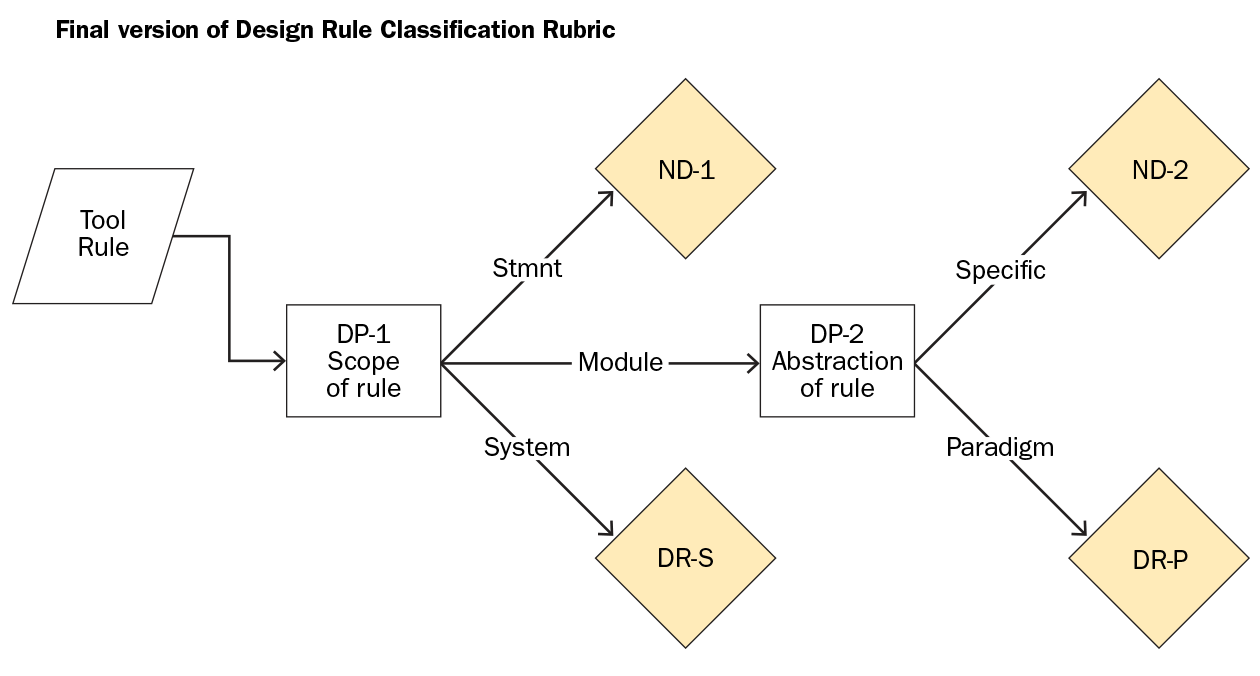
The first decision point in the rubric is rule scope (decision point DP1, above), with three potential branches that we refer to as statement-level, module-level, and system-level. To explain how it works, we give examples of each branch of the tree below.
- Statement-level: At the first filter, statement level, scope is limited to a single code statement, and rules are typically syntax related. We categorized as ND-1 (not-design rule) if the rule scope is limited to a single code statement (e.g., internal to method [switch, case, if/else, expression]). Empty methods and dead stores also fit here.
- Module-level: The module-level filter leads into the decision point DP2, about rule abstraction level. Modules include groups of statements (that might be bundled into a file or package) or a language construct (method or class) that can be executed independently, reused, tested, and maintained, or is a composition of other modules. This category includes module-level, syntax-specific violations, similar to statement level, and rules that check for design paradigms.
We discarded module-level syntax checking rules as non-design (ND-2 in our classification rubric). These rules typically cannot translate easily into another language or paradigm, or encapsulate keywords or reserved words or concepts that cannot be translated to a generalizable concept. For instance, violating Spring naming conventions is a rule with no obvious commonalities in other frameworks. Another example is the rule Don't call GC.Collect() without calling GC.WaitForPendingFinalizers().
Module-level rules that check for design paradigm (DR-P in our classification rubric), aim to identify rules that encapsulate known design paradigm principles. These rules include object-oriented, functional, and imperative programming; architectural styles, such as concurrent, model-view control, and pipe-and-filter; and the use of particular design patterns and paradigms, such as exception handling, singletons, and factories. Action Classes should only call Business Classes is a rule labeled as DR-P because it enforces an aspect of the model-view-controller pattern.
- System scope: The system scope filter includes problems detected across system boundaries (e.g., between languages and/or architectural layers). This filter also includes rules where system-level metric thresholds are reported (e.g., complexity and dependency propagation). Avoid having multiple artifacts deleting data on the same SQL table is an example of such a rule labeled DR-S. This rule is a design rule because not only are multiple system elements involved, but their architectural responsibilities are critical (in this case, enforcing the data model).
Our study artifacts include the design rules spreadsheet, categorization labeling results, and the categorization guidance document (with rubric). They are available on the SEI website.
Results of Our Analysis
Of the 466 rules we analyzed, 55 percent were easily labeled as "not design" (ND) and 19 percent were labeled as "clearly design." Labelers disagreed on the remaining rules, which were hard to classify.
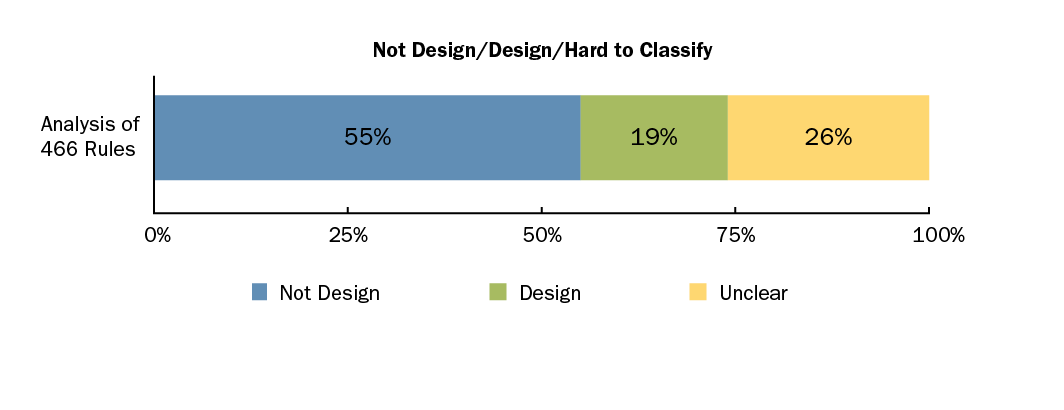
The figure below shows examples of design, non-design, and hard-to-classify rules.

Looking Ahead
As our analysis illustrates, the separation of design rules and code quality rules could have a great impact by allowing developers to focus on design-related issues, which often lead to technical debt. Our study suggests that progress in automated design analysis can be achieved by addressing the following tasks:
- Defining design rule scope. Our classification results revealed that design rules go beyond statement-level quality checks. Tools that reported scope of impact (and not just time to fix, as many do currently) would facilitate classification.
- Validating properties of design rules. We extracted the initial properties of the design rules we identified. For example, we found that the quality attribute filter was not helpful, because nearly every rule, even syntax rules, had some quality impact. Existing know-how on design tactics and expert observations can help validate and improve the properties of automatable design rules.
- Improving context sensitivity. The hard-to-label rules in our data are an important outcome of our study. Often, the reason they were hard to label was due to context sensitivity. As reported by Microsoft researchers, you can only achieve real impact when your analytics work closely with the information needs of the stakeholders.
The SEI Architecture Practices team is a pioneer in advancing the research agenda for technical debt. In addition to our ongoing research and industry work, we have also helped to organize the international Managing Technical Debt Workshop series. Our early efforts have focused on providing software engineers visibility into technical debt from strategic and architectural perspectives. Our ongoing efforts focus on developing tools and practices for providing comprehensive technical debt detection and visualization for developers, architects, and business stakeholders.
This work represents the latest effort in this arena.
We welcome your feedback in the comments section below.
Additional Resources
This conference paper from which this blog post is excerpted will appear in the Proceedings of the IEEE International Conference on Software Architecture (ICSA 2017).
Written By

More By The Author
More In Software Architecture
PUBLISHED IN
Software ArchitectureGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed