A Technique for Decompiling Binary Code for Software Assurance and Localized Repair

PUBLISHED IN
Secure DevelopmentThe DoD has a significant amount of software that is available only in binary form. Currently, it is impractical to ensure that this software is free from vulnerabilities and malicious code. Our goal in this project is to increase software assurance of binary components.
For example, some of our current DoD customers are concerned about preventing return-oriented programming attacks. Concerns over such an attack escalated in July of this year when it was reported that at least one attacker had exploited a remote code execution vulnerability in the SolarWinds Serv-U product, which is used by U.S. industrial base entities and software companies.
In this post, I describe a research effort that addresses the need for software assurance for binary code. Specifically, I will present a technique of decompiling binary code for the purpose of analysis and localized repair.
Use of Decompilation for Software Assurance of Binaries
Our work will evaluate the feasibility of decompiling binary libraries to enable static analysis and localized repairs to functions of a binary library or binary executable. More specifically, we aim to
(1) develop a tool for determining whether individual functions have been correctly decompiled
(2) measure what percentage of functions are decompiled correctly on typical real-world binary code
(3) measure how close static analysis on decompiled code approximates static analysis on the original source code
We will adapt an existing open-source decompiler, Ghidra, to produce decompiled code suitable for static analysis and repair. We will then evaluate it with real-world, optimized binary files. It is important to note that Ghidra was never designed to produce recompilable code. For the purposes of this work, therefore, we are pushing it beyond its original design goals.
A key insight behind this project is that a perfect decompilation of the entire binary is not required to get a significant benefit, provided that enough relevant functions are correctly decompiled. If successful, this project will lay the groundwork for (1) enabling the DoD to more accurately perform software assurance for projects that include binary components and (2) developing a framework for making manual or automated localized repairs to functions of a binary. This work should be of interest to DoD organizations involved in software assurance for systems that include binary-only software components.
This work draws on the SEI’s expertise in binary static analysis and formal methods. We are working with Cory Cohen and Jeffrey Gennari, senior malware reverse engineers experienced in automated binary static analysis. We are also collaborating with Ruben Martins, an assistant research professor at Carnegie Mellon University’s Institute for Software Research, and Arie Gurfinkel, an associate professor in electrical and computer engineering at the University of Waterloo, a leading expert in formal methods and the author of SeaHorn, a verification tool that we are using for proving semantic equivalence.
Difficulties in Decompilation
It is widely recognized that state-of-the-art decompilers usually cannot fully decompile binaries that were compiled with optimizations. As an example, consider an expression such as array[index - c], where c is a numeric constant. A concrete example is shown in the code snippet below.
An optimizing compiler will partially perform the pointer arithmetic at compile-time, combining c and the address offset of the array into a single numeric constant. This optimization prevents a straightforward decompilation of the code because the base address of the array cannot easily be determined. With more advanced static analysis, a decompiler could determine that the dereferenced pointer always points inside the array, but existing decompilers do not perform this type of analysis.
State-of-the art research in decompiling to correct recompilable code has mostly focused on unoptimized whole programs. A recent paper found that Ghidra correctly decompiled 93 percent of test cases (averaging around 250 LoC each) in a synthetic test suite. This analysis focused on only unoptimized code and did not include structs, unions, arrays, or pointers. Additionally, the programs considered did not have any input or nondeterminism, which made it easy to check whether the decompilation was correct: the original and decompiled programs can simply be executed once and their output compared for equality. Our work differs by (1) considering optimized real-world binaries without any of the above-mentioned restrictions, and (2) doing correctness checking at the function level rather than at the whole-program level.
Pipeline for Decompilation and Assurance
Our techniques can be used on both stand-alone binary executables and on binary libraries that are linked with software available in source form. The envisioned pipeline for analysis and repair of a source-and-binary project is shown below:
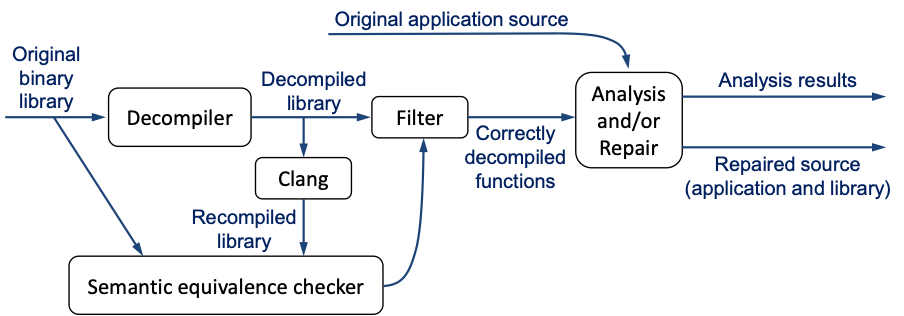
Only those functions that are correctly decompiled—semantically equivalent to the original—will be passed along for static analysis and/or repair, together with the available original source code. Two functions are semantically equivalent if and only if they always have the same side effects and the same return value.
We aim to enable localized repairs, i.e., repairs that are confined to a single function and can’t break code elsewhere. Localized repairs can be feasible even if the binary as a whole cannot be correctly decompiled. In Linux, repaired functions can be recompiled into a separate library file, and the LD_PRELOAD environment variable can be used to load repaired functions, overriding the unrepaired functions. With additional work, the repaired functions can be inserted directly into the original binary file. Our work on this project builds a foundation for supporting binary repair.
The Challenges of Equivalence Checking
Equivalence checking is often very hard. Any two stable sorting algorithms are semantically equivalent—except possibly in regards to allocating, clearing, and freeing memory—but verifying this equivalence can require a lot of work. To enable efficient equivalence checking, we will take advantage of the fact that both functions originally came from the same source code. In this context, we expect that the sequence of operations with side effects, such as function calls and memory accesses, should be the same in both the original function and the recompiled function. Our preliminary investigation supports this assertion. By exploiting this similarity, we expect that verifying equivalence will be practical for many functions. If verification fails, our tool will attempt to find a counterexample demonstrating non-equivalence.
We will evaluate our proposed technique on two metrics:
- Percentage of functions that are proved to be correctly decompiled, i.e., semantically equivalent to original. To our knowledge, our tool will be the first tool capable of measuring this quantity.
- Similarity of static analysis results (original source versus decompiled) on extracted code. We define this metric as the percentage of distinct static-analysis alerts that are shared in common between the results on the original source code and the results on decompiled code. For example, if there are 4 distinct alerts, and 2 of them occur in both the results for the original code and the results for the decompiled code, then the similarity score is 2 / 4 = 50 percent. Here, alerts are identified by a tuple of (filename, function name, alert type). The line number is omitted because it won’t match between the original and the decompiled.
One risk to operational validity is that the performance of a decompiler can be highly dependent on the compiler that was used to produce the binary. To mitigate this risk, we will study binaries produced by a wide variety of compilers, including multiple versions of GCC, Clang/LLVM, and Visual Studio.
Analysis of the Recompilability of Decompiled Functions
Our first task was to automate extraction of decompiled code from Ghidra and measure the baseline success rate. We wrote a script to take an executable file, decompile it with Ghidra, and split the decompiled code into separate files so that each function could be recompiled separately. We encountered minor syntactic problems, such as missing semicolons and missing declarations, that often prevented recompilation of the decompiled code, giving an out-of-the-box success rate close to zero. This low success rate isn’t too surprising because, as we noted earlier, Ghidra was designed to aid manual reverse engineering of binaries, not for recompilation.
Next, we focused on low-hanging fruit to improve decompilation with a postprocessing script aimed at resolving most of the syntactic errors. We are now seeing a success rate between 32 percent and 75 percent of functions being decompiled to a form that can be recompiled. Many of the remaining syntactic errors arise from incorrectly inferring the number and types of arguments of a function, resulting in a mismatch between the function declaration and its callsites.
To date, the most mature aspect of our work has been the analysis of recompilability of decompiled functions. On a set of real-world programs (shown in the below table), about half of the functions decompiled to syntactically valid (i.e., recompilable) C code.
| Project | Source Functions | Recompiled Functions | Percent Recompiled |
|---|---|---|---|
| dos2unix | 40 | 17 | 43% |
| jasper | 725 | 377 | 52% |
| lbm | 21 | 13 | 62% |
| mcf | 24 | 18 | 75% |
| libquantum | 94 | 34 | 36% |
| bzip2 | 119 | 80 | 67% |
| sjeng | 144 | 93 | 65% |
| milc | 235 | 135 | 57% |
| sphinx3 | 369 | 183 | 50% |
| hmmer | 552 | 274 | 50% |
| gobmk | 2684 | 853 | 32% |
| hexchat | 2281 | 1106 | 48% |
| git | 7835 | 3032 | 39% |
| ffmpeg | 21403 | 10223 | 48% |
| Average | 52% |
Preventing Future Attacks
With existing solutions for analyzing binary components, investigating warnings requires significant manual effort by experts. Repairing binary code is even harder and more expensive than analysis. Currently, the effort required to fully assure binary components is impractical, leading to production use of potentially vulnerable or malicious code. If our work is successful, the DoD will be able to find and fix potential vulnerabilities in binary code that might otherwise be cost-prohibitive to investigate or repair manually.
Additional Resources
Read the post Automated Code Repair to Ensure Memory Safety by Will Klieber.
Written By

More By The Author
PUBLISHED IN
Secure DevelopmentGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed