8 Steps for Migrating Existing Applications to Microservices

PUBLISHED IN
Software ArchitectureA 2018 survey found that 63 percent of enterprises were adopting microservice architectures. This widespread adoption is driven by the promise of improvements in resilience, scalability, time to market, and maintenance, among other reasons. In this blog post, I describe a plan for how organizations that wish to migrate existing applications to microservices can do so safely and effectively.
In a typical monolithic application, all of the data objects and actions are handled by a single, tightly knit codebase. Data is typically stored in single database or filesystem. Functions and methods are developed to access the data directly from this storage mechanism, and all business logic is contained within the server codebase and the client application. It is possible to migrate several monolithic applications and/or platforms, each with its own data storage mechanisms, user interfaces, and data schema, into a unified set of microservices that perform the same functions as the original applications under a single user interface. Migrating these applications to microservices offers the following advantages:
- removing duplication of effort for manual entry
- reducing programmatic development risks
- providing a single, unified view of the data
- improving the control and synchronization of these systems
Software Architecture Patterns
Before describing the migration process from monolithic systems towards microservices, some descriptions of the relevant software architecture patterns would be useful.
Monolith
Many current legacy applications are implemented as monoliths, in which all data storage and processing are controlled by the monolith, and all functions for all data objects are processed using the same backend codebase.
Although this method of development is historically typical, it can lead to maintainability problems:
- Updating code for one set of data objects may break dependencies in other areas.
- Scaling the system can be hard because of intertwined data relationships.
- Providing multiple ways to programmatically locate, update, and access data can be challenging.
Microservices
The microservices software-development pattern provides a method to build a single, unified service out of a collection of smaller services. Each microservice component focuses on a set of loosely coupled actions on a small, well-defined dataset. Each microservice includes an independent storage system so that all of its data is located in a single location. By reducing the number of blocking operations on the data-storage backend, this architecture enables the microservice to scale horizontally, increasing capacity by adding more nodes to the system rather than just increasing the resources (RAM, CPUs, storage) on a single node.
Microservices can be written in any programming language and can use whichever database, hardware, and software environment makes the most sense for the organization. An application programming interface (API) provides the only means for users and other services to access the microservice's data.
The API need not be in any particular format, but representational state transfer (REST) is popular, in part because its human-readability and stateless nature make it useful for web interfaces. Other common API formats include gRPC and GraphQL, which each have different approaches and tradeoffs for how data is accessed.
Data Locality
Although each microservice maintains its own datastore, the data need not be stored on a single disk on a single machine. What is important is that the only method for the system and users to access the data is through the API. The underlying storage mechanism may be a single disk, or it may be a distributed, high-availability cluster that is mirrored through data replication and some form of quorum mechanism. The implementation details are up to the system owners and should reflect the needs of the system based on expected use.
Similarly, there is no requirement that the data-storage location for each microservice reside on separate hosts. The microservices pattern focuses on only the data directly reading its own dataset. Since it is not accessing those other datasets, it does not matter whether there are other co-located datasets on the same data-storage system. Again, system owners should weigh the cost and maintenance benefits of co-locating data with the risks associated with maintaining a single point of failure for their data.
The underlying mechanism and processes for storing, backing up, and restoring data for the monolithic system, the interim macroservices, and the final microservices remain the prerogative of the system owners.
Migrating from Monolith to Microservices
Scalability is one of the primary motivations for moving to a microservice architecture. Moreover, the scalability effect on rarely used components is negligible. Components that are used by the most users should therefore be considered for migration first.
Users want their interactions with a system to return the right data at the right level of detail, usually as fast as that data can be acquired. The jobs for users each involve one or more data objects, and each data object has a set of associated actions that can be performed. The development team that designs and implements the system must consider the collection of jobs, data objects, and data actions. A typical process to migrate from a monolithic system to a microservices-based system involves the following steps:
- Identify logical components.
- Flatten and refactor components.
- Identify component dependencies.
- Identify component groups.
- Create an API for remote user interface.
- Migrate component groups to macroservices (move component groups to separate projects and make separate deployments).
- Migrate macroservices to microservices.
- Repeat steps 6-7 until complete.
I describe "components," the "remote user interface," and "macroservices" in more detail below.
In this process, developers perform steps 1-5 once at the beginning of the migration project. The team can revisit these steps as processes get migrated or when new information becomes available during the migration process, but once the steps are completed, it should not be necessary to revisit them.
Step 6 is an interim step that may not be needed for some projects. If a macroservice is not needed, developers can skip step 6; step 7 then becomes, "Migrate component groups to microservices." Likewise, developers can skip step 7 or a particular iteration if the migration from macroservice to microservice appears too hard or if the macroservice transition is adequate by itself.
Step 8 exists because developers need not perform the entire migration at once. They can pull components out of the legacy monolith and make them into microservices, either singly or in groups as the development warrants.
Components and Component Groups
The components are the logical sets of data objects and the actions that the system performs on those objects. The actions performed on data objects are typically encoded in software functions and methods, and these functions and methods are typically stored in software libraries. The component groups roughly correspond to software libraries, but the migration process may rearrange the contents of existing software libraries to meet the migration goals.
Macroservices
A macroservice is similar to a microservice with two primary differences. First, a macroservice may share the datastore with the legacy monolithic system or other macroservices. Second, unlike a microservice, a macroservice may provide access to multiple data objects and jobs to be done.
Because of these differences from microservices, macroservices may suffer the same problems as monolithic systems regarding scalability and maintainability. However, because they are typically focused on fewer data objects and interactions than the original monolithic systems, they can be a useful interim step during the migration process. It is possible to realize some benefits from the reduced complexity while the architects determine the best way to untangle the remaining interconnections.
API Proxy/Façade
The application programming interface (API) proxy is the mechanism through which all dataflows to the underlying services must traverse. This API is used by both user interfaces and backend systems. During the migration, the monolithic system must be modified so that the components that have been migrated (either to macroservices or microservices) use the API to access the migrated data. The monolithic system must also be modified so that the API proxy can communicate with the legacy system to perform the actions that have not yet been migrated. The API proxy can then be used to access the data whether it is accessible through the monolithic service, a microservice, or an interim macroservice.
Only a single migrated microservice may be allowed to access the data directly. All other users of that data must use the API for access. When the migration is complete, the API remains the only means to access the data.
Ideally, a macroservice would have the same exclusive access to its datastore for all relevant information, but sometimes it might need to access the datastore of the legacy monolithic application or another macroservice. However, if the macroservice does include a datastore that is separate from the legacy monolithic application, that monolith should not be able to access the macroservice's datastore directly; the monolith should always use the API for that data.
This API proxy is sometimes referred to as the façade because it masquerades as the actual microservices that are behind it. After the underlying services have been migrated and can respond to API calls directly, the API proxy may be removed.
The 8-Step Migration Process
1. Identify Logical Components
There are three main information components with the data used in the system:
- data objects
- data actions
- job to perform and use cases
The data objects are the logical constructs representing the data being used. The data actions are the commands that are used on one or more data objects, possibly on different types of data, to perform a task. The job to perform represents the function the users are calling to fulfill their organizational roles. The jobs to perform may be captured as use cases, user stories, or other documentation involving user input.

When combining multiple systems into a unified system, the data objects, data actions, and jobs to perform for each individual system must be identified. All these components are implemented as modules within the codebase with one or more modules representing each data object, data action, and job to perform. These modules should be grouped into categories for working with later steps. This grouping is indicated by color coding in Figure 1.
System architects may find it easiest to identify the data objects used within a system. Working from this dataset, they can then determine the data actions and map these to the jobs to performed by users of the system. The codebase is usually object-centric, and each code object is associated with functions and jobs to perform.
During this part of the migration process, system architects should be asking the following questions:
- If two or more applications provide similar data, can this data be merged?
- What should be done about data fields being different or missing in similar objects?
The migration from a monolithic system to microservices does not typically affect the user interface directly. The components that are best for migrating are thus determined by which components
- are used by the most users
- are used most frequently
- have the fewest dependencies on other components
- are performing too slowly
2. Flatten and Refactor Components
After all the modules have been uniquely identified and grouped, it is time to organize the groups internally. Components that duplicate functionality must be addressed before implementing the microservice. In the final system, there should be only one microservice that performs any specific function. Function duplication will most likely be encountered when there are multiple monolithic applications being merged. It may also arise where there is legacy (possibly dead) code that is included in a single application.
Merging duplicated functions and data will require the same considerations as when designing the ingestion of a new dataset:
- Check data formats.
- Verify datatypes.
- Verify data accuracy.
- Verify data units.
- Identify outliers.
- Deal with missing fields or values.
Since one of the effects of this migration is to have a single data repository for any piece of data, any data that is replicated in multiple locations must be examined here, and the final representation must be determined. The same data may be represented differently depending on the job to be done. It is also possible that similar data may be obtained from multiple locations, or that the data may be a combination from multiple data sources. Whatever the source and however the data will be used, it is essential that one final representation exists for each unique datatype.
3. Identify Component Dependencies
After the components have been identified and reorganized to prepare for the migration, the system architect should identify the dependencies between the components. This activity can be performed using a static analysis of the source code to search for calls between different libraries and datatypes. There are also several dynamic-analysis tools that can analyze the usage patterns of an application during its execution to provide an automated map between components. Figure 2 below shows an example of a map of component dependencies.
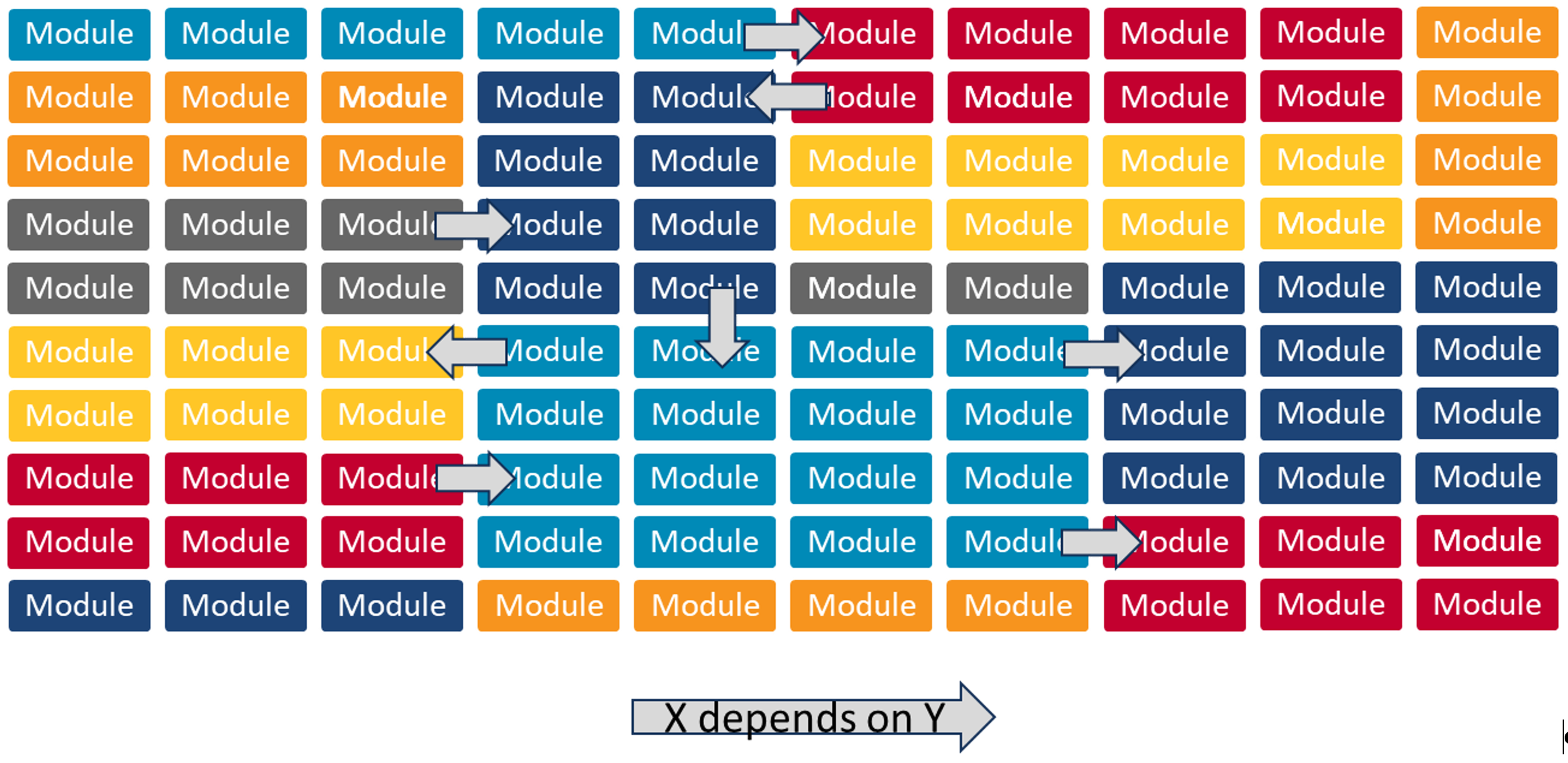
One tool that can be used for identifying component dependencies is SonarGraph-Explorer. This tool includes a view of the elements arrayed in a circle or in a hierarchy, which allows an analyst to visualize how each component is associated with other components in the codebase.
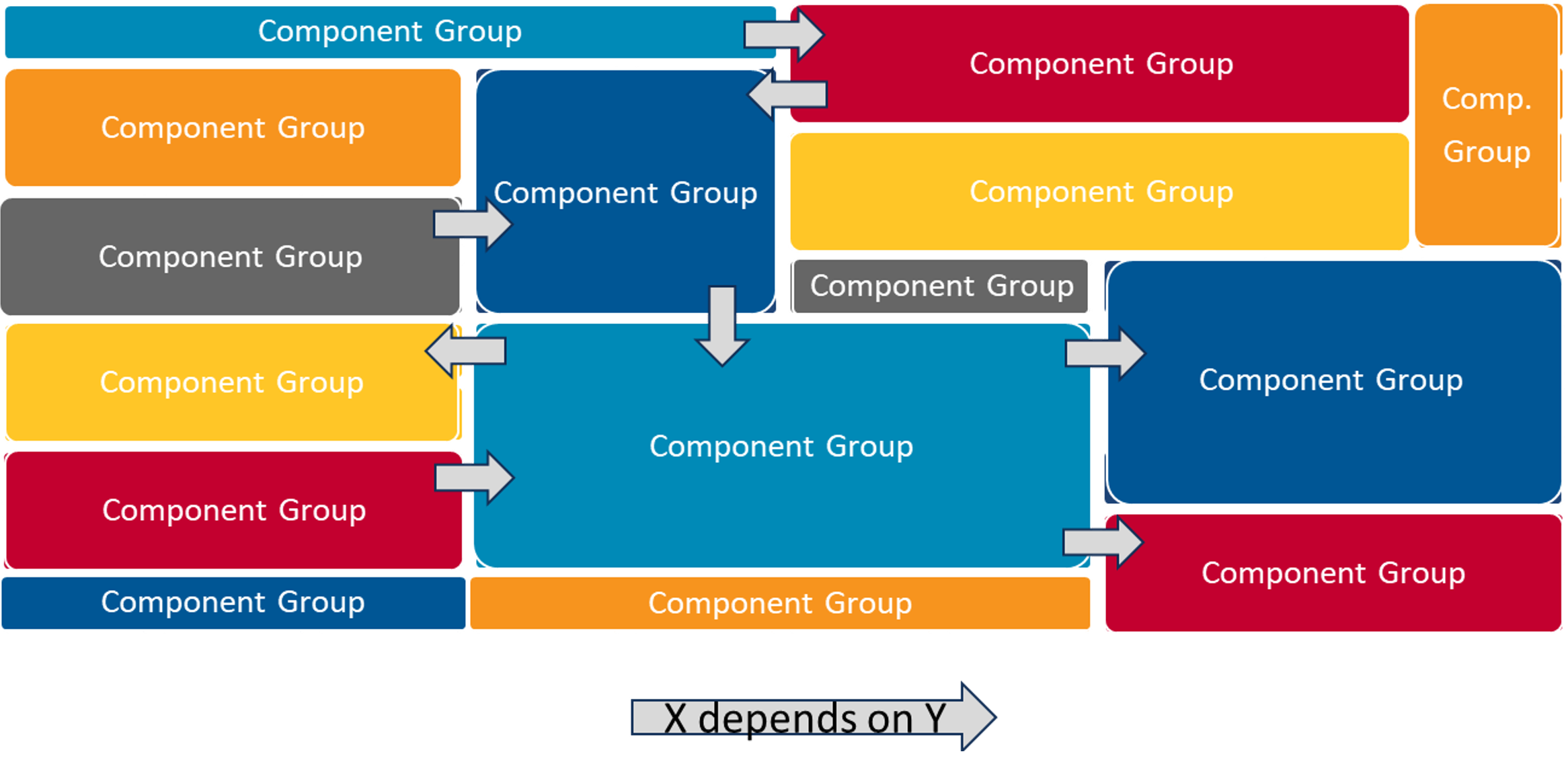
4. Identify Component Groups
After the dependencies have been identified, the system architect should focus on grouping the components into cohesive groups that can be transformed into microservices, or, at least, macroservices. The distinction between macroservices and microservices at this point is not important. The goal is to identify a small set of objects and their constituent actions that should be logically separated in the final system.
5. Create an API for Remote User Interface
The remote user interface is intended as the sole mode of communication between the system, its components, and the system's users. It is vitally important that this interface be scalable and well planned to avoid problems as the system evolves over time. The underlying interface must be usable both during the migration and afterwards, so it is likely change as components are reworked from the monolithic system to macroservices and microservices.
The key output from this migration effort is a unified API that the user interface(s) and applications can use to manipulate the data. Everything else depends on this API, so it should be engineered to ensure that existing data interactions will not change significantly. Instead, it should allow for the addition of new objects, attributes, and actions as they are identified and made available. After the API layer is in place, all new functionality should be added through the API, not through the legacy applications.
The design and implementation of the API is key to the success of the migration to microservices. The API must be able to handle all data-access cases supported by the applications that will use the API. In keeping with standard practice of software version-control numberings, a change to the API that breaks the backward compatibility with earlier versions should trigger a change of the "major" revision number for the API.
Changes to the API that break backward compatibility should be infrequent and planned in advance to prevent recurring deployment problems. The API should provide a mechanism so that the application can check the API version being used and warn users and developers about incompatibilities. The only changes to the API should be those that add new data objects and functions and that do not modify the format of the existing outputs or expected inputs. For microservices to work properly, all data access must be provided through the API to the micro-services or, during the migration transition period, to the macroservices or legacy application.
To maximize the scalability of the final system, the API should be
- stateless
- able to handle all data objects represented within the system
- backward compatible with previous versions
- versioned
Although a REST API is typical, it is not strictly mandated for microservices.
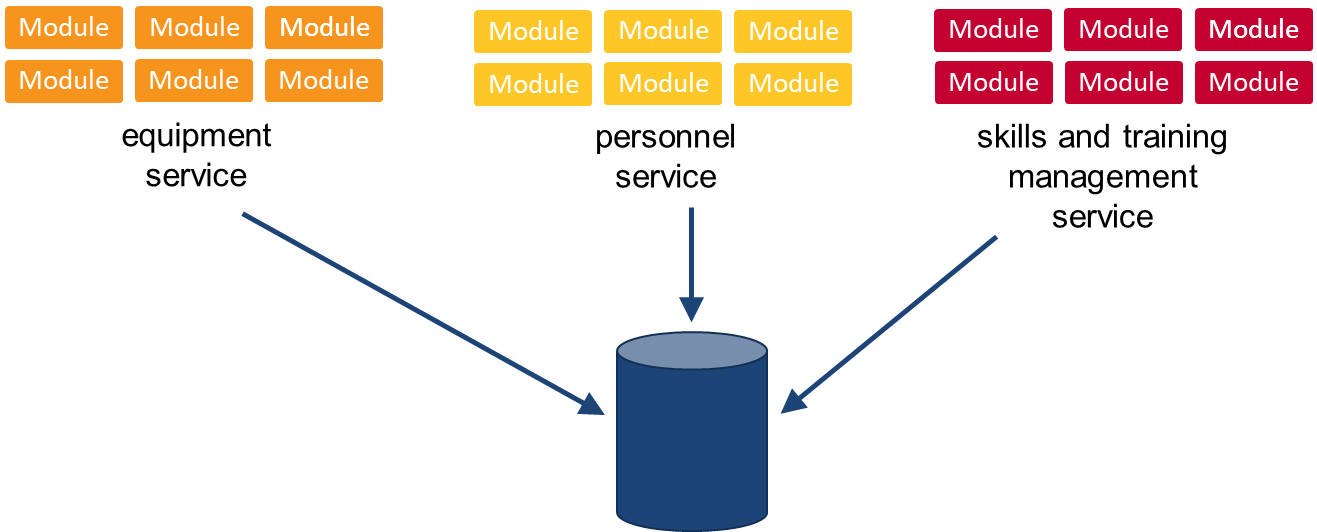
6. Migrate Component Groups to Macroservices
Macroservices have a more relaxed posture toward sharing data repositories and allow more complex interactions with data objects. It may therefore be useful to consider their use as an interim step toward migrating to full microservices. The main reason for not moving directly to microservices is complexity. A monolithic system is typically built with intertwined logic that may cause problems when converting to microservices. If the monolith is continuously changing, then migrating to microservices in a single step will be a continuously changing target as well.
The key goal at this step is to move component groups into separate projects and make separate deployments. At a minimum, each macroservice should be independently deployable from within the system's continuous integration (CI) and continuous deployment (CD) pipeline.
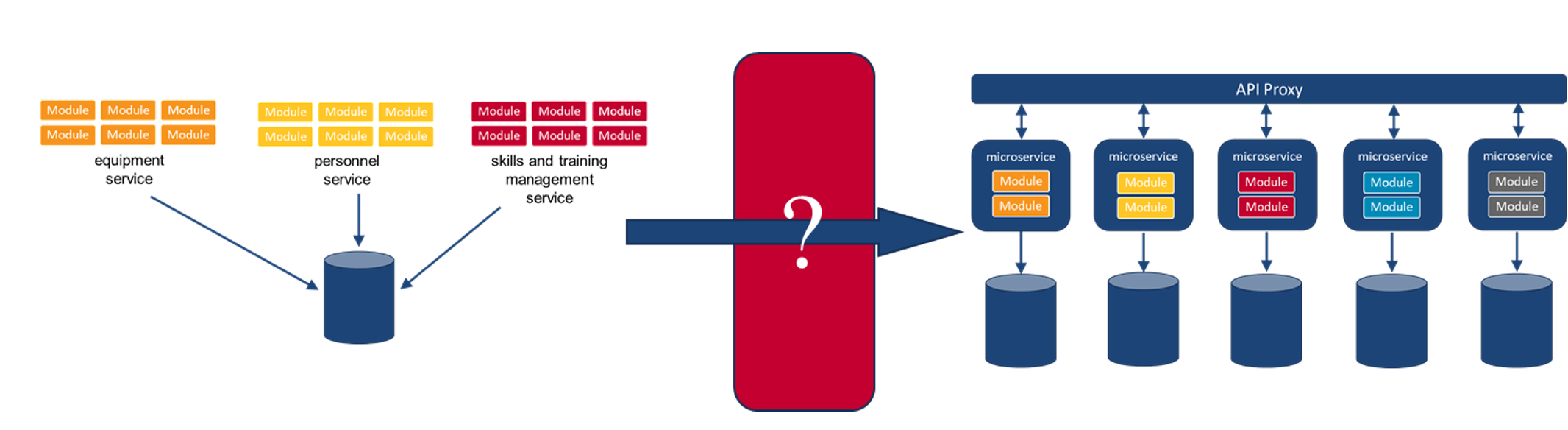
7. Migrate Macroservices to Microservices
The process of pulling the components, data objects, and functions out of the monolithic system and into macroservices will provide insight into how these components can be further separated into microservices. Remember, each microservice maintains its own datastore and performs only a small set of actions on the data objects within that datastore.
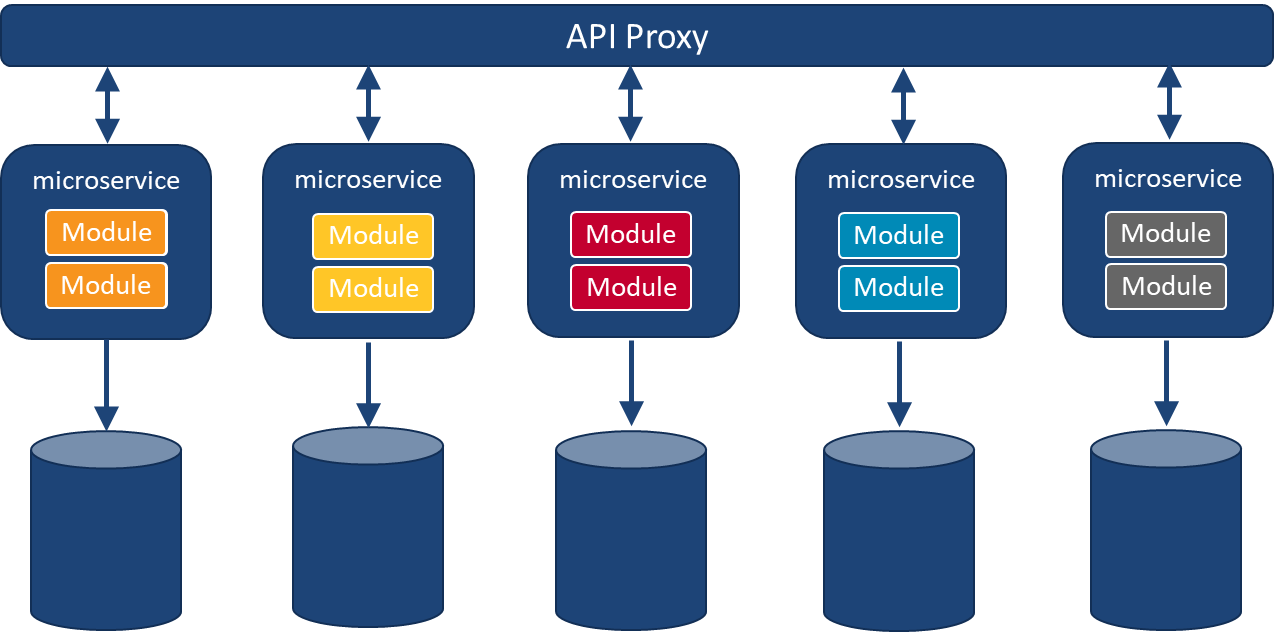
8. Deployment and Testing
Once a macroservice or microservice is ready for deployment, the next step involves integration testing and deployment. The monolithic system must be configured to use the new service for its data needs rather than its legacy datastore.
Finding all calls to the datastore from within the legacy monolithic system can be hard. In a testing environment, it should be possible to remove the legacy data related to the migrated dataset for which the new microservice is now responsible. All functions that access the migrated data should be tested in all user interfaces to ensure that there is no function that still attempts to use the old datastore through a previously undetected method. If possible, accesses to the old dataset on the old datastore should be logged and flagged in case old or refactored code is still able to access the legacy data. Access controls should be updated to prevent users from accessing the old data directly from the datastore; users may be notified how to access the data using the new API interface if such direct accesses are permitted.
After testing indicates that the remaining monolithic code is accessing the new service for its information and that there don't appear to be any remaining connections with the old datastore, the new service can be deployed to the production systems.
Consolidating Multiple Services
When this process is used to consolidate multiple services rather than just migrating a single legacy system, there may be one or more instances where the same or similar data is stored by more than one legacy system. This consolidation poses a problem of how to handle the data during the migration period. At the end of the migration, this data should be stored as one or more microservices and accessed through the API by all components that want to use that data.
Ideally, as part of Step 2, Flatten and Refactor Components, a single authoritative system should be identified to handle the data and all dataflows would be configured to use this single system. The API would point to this system, and the legacy applications would be configured to use the API to access this data in its authoritative location.
The API should always read data from one authoritative location. Ideally, this data should always write data to a single authoritative location as well. However, an interim macroservice may be configured to write data to multiple datastores concurrently, possibly including the datastore for the legacy monolithic system. At some point before the completion of the migration process, the multiple writes must be removed so that only a single datastore contains the relevant data.
Wrapping Up
This plan for migrating existing applications to microservices is intended to enable organizations to realize benefits of microservice architectures, such as resilience, scalability, improved time to market, and easier maintenance, with maximum efficiency and minimal disruption to existing applications and services.
Additional Resources
Read the SEI blog post, Defining Microservices.
Read the SEI blog post, Microservices Beyond the Hype: What You Gain and What You Lose.
Watch the SEI webinar, Quality Attribute Concerns for Microservices at the Edge.
Written By

More By The Author
More In Software Architecture
PUBLISHED IN
Software ArchitectureGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed