Using the SEI CERT Coding Standards to Improve Security of the Internet of Things

The Internet of Things (IoT) is insecure. The Jeep hack received a lot of publicity, and there are various ways to hack ATMs, with incidents occurring with increasing regularity. Printers in secure facilities have been used to exfiltrate data from the systems to which they were connected, and even a thermometer in a casino's fish tank was used to gain access to the casino's infrastructure and extract data about customers, gamblers, etc. In this blog post, I describe how the SEI CERT Coding Standards work and how they can reduce risk in Internet-connected systems. This is the first installment in a two-part series; in Part 2, I will describe how to use static analysis to enforce the CERT coding rules.
Automobiles illustrate the risks intrinsic to the IoT. The number of embedded computers and amount of code in cars increases every year: high-end cars today have more than 100 million lines of code. We also know that reported cybersecurity incidents rose steadily between 2006 and 2014, the years during which the CERT Coordination Center kept and reported this data. The number of cybersecurity incidents has continued to increase since 2014 and is unlikely to decrease anytime soon. Taking into account benchmarks for numbers of defects per thousand lines of code (KLOC), more code usually equates to more opportunities for vulnerabilities.
Figure 1: CERT Annual Reported Cybersecurity Incidents, 2006-2014
There are multiple ways today for attackers to reach into a car--Bluetooth, WiFi, cellular connectivity, and radio-frequency identification (RFID)--and cyberattacks are increasing in frequency and sophistication. For example, an attacker can use a car's tire-pressure monitoring system to reach into the car and change things.
The infotainment systems in cars require communication with the outside world. Navigation systems need to communicate with the Global Positioning System (GPS) and with cellular networks and satellites, and AM/FM radios need to communicate via radio channels. Many other features require access to the Internet. Infotainment systems also allow users to plug their own devices into the car via USB ports, Bluetooth, and even to play old-fashioned CDs.
While these capabilities serve legitimate purposes, all this connectivity with the outside world exposes a number of interfaces that can be attacked to communicate with the car in unintended and potentially dangerous ways. By exploiting vulnerabilities in infotainment systems, attackers can gain access to the car's infotainment computer, and through that to the controller area network (CAN) bus. Once attackers have access to that, there are few, if any, functions of the vehicle they cannot control.
Secure Coding
Secure-coding practices can reduce the risks I have just described. People like to think that coders are simply translators who take a software design and faithfully create a secure, functional program from the design. Unfortunately, the coding phase of the software development lifecycle is where the bulk of vulnerabilities are introduced. In fact, a study showed that 64 percent of vulnerabilities originate during the coding phase. While some vulnerabilities originate in the design phase, coding problems are responsible for many commonly exploitable vulnerabilities including buffer overflows, injection vulnerabilities, and cross-site scripting. Security bugs are also quality issues, a consequence of developers making coding errors (along with some design errors). So to solve this problem, we must
- Train developers in secure coding so that they can prevent or at least find and fix security problems.
- Design and build systems with a deliberate focus on quality and security.
- Collect and measure defect data (about code quality AND security) and use it to assess and improve development practices.
To address these problems, we have built the SEI CERT C Coding Standard, one of several coding standards developed by the CERT Secure Coding team for commonly used programming languages such as C, C++, Java, and Perl, and the Android platform. These standards are developed through a broad-based community effort by members of the software-development and software-security communities. The first edition of the CERT C standard was published in 2008, and the 3rd edition, published in 2016, is freely available as a downloadable PDF. The most up-to-date version is freely available on our wiki, which can also be used to submit comments, pose questions, or flag errors.
There are 103 rules and 169 recommendations in the SEI CERT C Coding Standard. Rules in the standard must meet the following criteria:
- The violation is likely to result in a defect that may adversely affect the security of a system and can also cause safety and reliability problems.
- The rule does not rely on source-code annotations or assumptions.
- Conformance can be determined through automated analysis (either static or dynamic), formal methods, or manual inspection.
SEI CERT Coding Rules
Most SEI CERT coding rules have a consistent structure. Each rule has a unique identifier, which is included in the title. The title and the introductory paragraphs define the rule and are typically followed by one or more pairs of non-compliant code examples and compliant solutions. Each rule also includes a risk assessment, related guidelines, and a bibliography. Rules may also include a paragraph describing related vulnerabilities.
Recommendations are organized in a similar fashion. We refer to the rules and recommendations collectively as guidelines.
Non-compliant code examples illustrate code that violates the guideline under discussion. Non-compliant code examples are typically followed by compliant solutions, which show how the non-compliant code example can be recoded in a secure, compliant manner.
Any guideline may specify a small set of exceptions detailing the circumstances under which the guideline is not necessary to ensure the safety, reliability, or security of software. Exceptions are informative only and are not required to be followed.

Figure 2: SEI CERT Secure Coding Rules, Risk Assessment
Each rule has a risk assessment, whose values are explained by Figure 2. Developers of IoT systems can use the SEI CERT Coding rules to assess the risk to their systems. Having this prioritization of the rules enables triaging vulnerabilities when there are too many to fix at once.
The risk assessment consists of three metrics.
- Severity. If a vulnerability is designated to be low severity, it means the worst it can do is cause the program to crash or hang. That could be bad if, for example, the program is maintaining a web server or running your pacemaker, but under most circumstances, crashing or hanging is not necessarily that bad; you just restart the program. Level 2, medium severity, means it would be possible to extract data from the system or modify the data in it, but not to run code. Level 3, high severity, indicates that arbitrary or malicious code could be run on the system. The reason we rank these severities is that if you have Level 2 severity, you almost always will also have Level 1. If someone can exfiltrate information from your code, they can almost certainly crash it. Similarly, if you have Level 3 severity, if someone can run their own code, they can see any information that they want to see and can crash programs at will.
- Likelihood. Unlikely, probable, or likely.
- Cost. How difficult it is to fix the code? That is, can the vulnerability be detected automatically? Can it be fixed automatically by some code-rewriting mechanism? The highest level is actually the easiest and cheapest to fix, all automatic, and the lowest level is the hardest to fix, all manual.
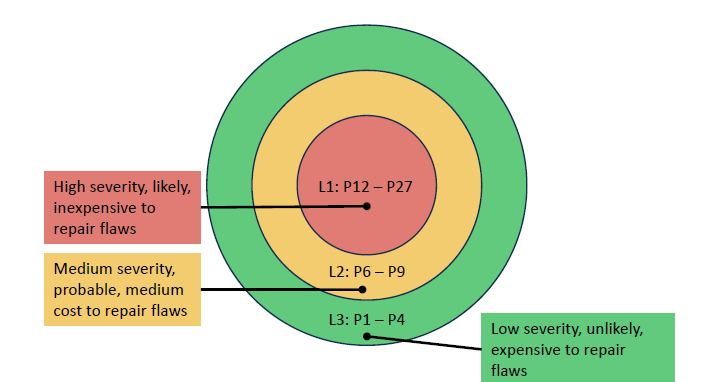
Figure 3: Priority Levels
Each of these three metrics yields an aggregate number between 1 and 3, as shown in Figure 3. We multiply the numbers for severity, likelihood, and cost to get a priority, which will be a number between 1 and 27. Priority 27 is the highest, and represents the most critical problems, while priority1 is the lowest. We finally partition these priorities into three levels, 1, 2, and 3. Again, 1 is the most severe, the most important to fix, and 3 the least important to fix. The highest aggregate numbers in this risk assessment, those of highest priority for fixing first, indicate vulnerabilities on which arbitrary code could be run and that are easy to detect and fix. The lowest priorities indicate vulnerabilities that have low severity--they lead only to crashes--and that are unlikely to happen and difficult to fix.
Looking Ahead: The Value of Static Analysis
To support a coding standard in your development efforts, you must enforce it in the code produced by your development team. Unless you are using static analysis to enforce your coding standard, then you must enforce it by hand, or through peer review. Both options are a lot of work, are prone to error, and in a system such as a single car, with a hundred million lines of code, are simply intractable. Furthermore, unlike peer review, static analysis is automatically enforceable and can confirm that a vulnerability, once identified, has been adequately fixed.
The disparity between the use of standards such as the SEI CERT Coding rules and the use of static analysis to identify deviations from those rules is illustrated by data from the Barr Group Embedded Security Safety Report from 2017 and 2018 (see Figure 4 below).
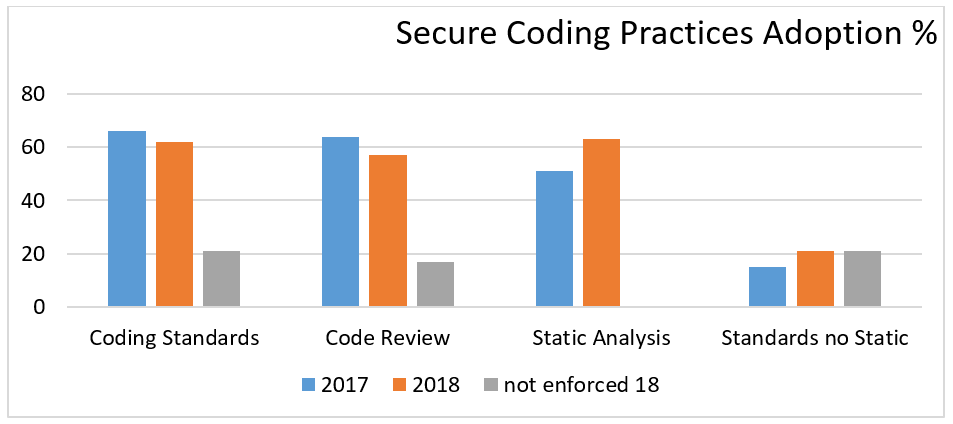
Figure 4: Barr Group Embedded Security Safety Report 2017 and 2018
The bars on the right show a gap between people using coding standards and people running a static-analysis tool, especially in 2017, where the gap is huge.
In Part 2 of this blog post, I will go into detail about how developers of large-scale systems, such as IoT systems in automobiles, can use static analysis to enforce CERT coding rules.
Additional Resources
Access current versions of CERT Secure Coding Standards.
Watch the Webinar, How Can I Enforce the SEI CERT C Coding Standard Using Static Analysis by David Svoboda and Arthur Hicken.
Read other SEI blog posts related to secure coding.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed