Using Machine Learning to Increase the Fidelity of Non-Player Characters in Training Simulations


On November 9, 1979, the North American Aerospace Command’s (NORAD’s) early warning system interpreted a training scenario involving Soviet submarines as an actual nuclear attack on the United States. In the six minutes that followed, the American military went on the highest level of alert. Afterward, training simulations were explicitly moved outside of the NORAD complex to prevent such a situation from occurring again in the future.
While the outcome of this fall day at NORAD is undeniably terrifying to consider, those of us interested in training and exercise development work hard to bring realism to every scenario we design. But there are obstacles to creating realistic scenarios. In this blog post, extracted from a more detailed SEI technical report, we describe our use of machine-learning (ML) modeling and a suite of software tools to create decision-making preferences for non-player characters (NPCs) so that they will be more credible and believable to game players.
The best-case scenario is for players to not be able to distinguish between an exercise and their daily operations. Experiences that seem real to players in training and exercise scenarios enhance learning. Improving the fidelity of automated NPCs can increase the level of realism experienced by players.
In our research, we test ML solutions and confirm that NPCs can exhibit lifelike computer activity that improves over time. We bring the scenarios that we build to life through our GHOSTS framework, which is an NPC simulation-and-orchestration platform for realistic network behavior and resulting traffic. The concepts described in this post, however, could also be adapted to other NPC frameworks.
NPCs simulate real-world user activity and create accurate network traffic. The best cyber-defense teams triangulate their findings based on network traffic, logs, sensor data, and a growing host-based toolchain. We therefore focus on overall activity realism and confirm our approach by comparing NPC activity to real-world users performing the same activity. There is a large corpus of artifacts and data necessary for training and exercise scenarios, and designers must often create an entire universe to explain the people, places, and activity that will occur throughout the lifecycle of the training or exercise event.
We improve the realism of NPCs in training exercises with new software we have created called ANIMATOR. The ability of ANIMATOR to increase the realism of NPCs is relevant and useful to anyone who is tasked with developing training for cyberteams. Our primary goal in ANIMATOR is to make our data as realistic as possible by using weighted randomization for as many datapoints about NPCs for which we can find datasets.
Challenges
In the training-exercise scenarios we create, ML holds the key to building a thinking teammate or adversary. However, there are challenges to its application. In addition to the need for fidelity of user simulations, a key challenge is the tendency of participants to game the system.
Players are always looking for patterns and will quickly exploit NPC weaknesses. This gaming of the system is not cheating, nor is it an attempt to gain an unfair advantage. Rather, it happens in different ways—either knowingly or unknowingly—by leveraging game-isms (unrealistic patterns that occur in an exercise).
An example of a game-ism is when an exercise offers a limited, shared internet, where the scope of traffic in or out of a friendly network is unrealistically limited. This scenario makes it easy for players to (1) filter traffic to highlight potential issues quickly or (2) identify traffic from specific IP addresses as problematic. In the worst case, players can place IP blocks in approved or unapproved lists—a method that would not work in real-world network operations. This example underscores why realism should remain the highest priority for training and exercise builders.
Cybersecurity training requires the coordination of distributed software agents that drive NPCs and their activities. The automation required to achieve maximum fidelity and minimize game-ism is available only through the use of ML.
Realistic Browsing by NPCs
To improve the fidelity of user simulation, our GHOSTS software agents enable NPCs to browse the Internet using any major browser. We configure agents to associate NPCs with preferences by making requests in a particular order or randomly using a supplied list. Most implementations use randomness, which is a gameable attribute.
Players using monitoring techniques can infer information about browsing sessions, and these inferences enable them to filter and unrealistically track sessions. Our first hint of this problem was when we observed players tracking the NPC browser’s user-agent (UA) string in different ways while monitoring NPC-based outbound web requests. The UA string uniquely identifies the browser being used, including its version, operating system, and type of machine (e.g., laptops, phones, and other computing devices).
Previously, we built mechanisms to change this UA string periodically for each NPC or even randomize changes to it over time. Changing the UA string simulates how users might update or change their web browsers periodically over time. With this approach, we can also implement UA strings known to be questionable or malicious. However, we observed players gaming the system by looking for UA strings that didn’t follow the patterns of UA strings in recent releases of major browsers. As a result, players flagged our use of alternative or malicious strings immediately.
The extent to which player teams used this information in their filtering and monitoring forced us to rethink the value of true randomization and to re-examine what real-world browsing behavior looks like on a typical network. We used the GHOSTS framework to examine patterns in NPC browsing behavior and asked questions such as
- What does realistic web browsing look like to a network team?
- What is the motivation behind particular browsing patterns?
- In a large, distributed system, how can we introduce the right degree of randomness without alerting players that the randomness is computer generated?
When researching browsing patterns, we thought about what people do when browsing the web. An NPC that browses websites randomly—going from news, to sports, to shopping—seems artificial and inconsistent with the real world.
People often explore a website in depth. They may engage in reading long-form content that is not captured on a single page. They may search through long lists of content that is paginated by design due to its length. They may compare several different items that are showcased in detail on separate pages. They may read news articles that highlight their varied interests. As a result, we introduced the notion of a website’s stickiness (an enticement to browse beyond the home page). We implemented this configurable feature with some degree of randomness but also with the ability to have NPCs visit at least some number of additional pages from the page first visited within a site. After we incorporated stickiness into our approach, we were better able to simulate a user clicking relevant links on pages across a website, thereby increasing the fidelity of NPCs and the agents that control them.
NPC Context and Preferences
GHOSTS records every activity a software agent executes to control an NPC and the results. Agents can use that data to help the NPC make decisions, and past NPC decisions can affect future ones.
Examples of an NPC’s preferences are certain websites, particular tasks, and how it responds to emails. Preferences might also include some negative partiality (i.e., avoiding certain tasks). Although our primary goal is to improve how an NPC browses relevant links on a website, we also introduce a more ambitious capability: providing context for an NPC to make continuous decisions about its future. Context includes
- human factors—information about the user, social environment, and user’s task
- physical environment—location, infrastructure, and physical conditions
Social environment and tasking can be related when NPCs are part of a team that performs tasks specific to that team. In the past, we built training and exercises to model real-world team behaviors. For example, Team A performs this set of specific tasks, and Team B performs some other separate set of tasks (much as you might expect a logistics and marketing team to do in the corporate world). By assigning these preferences to NPCs, we replicate these team configurations more dynamically and enable them to evolve.
Our approach to solving the challenge of realistic browsing and learning from the context and decisions the NPCs make over time is to use ML techniques that focus on personalization. However, there are similar NPC behaviors in GHOSTS that can help us understand and improve these behaviors over time. The user models that are implemented in different exercises via GHOSTS are vast and will continue to grow; therefore, understanding how NPCs make decisions provides important guidelines to help player teams as they train and perform exercises in ever-evolving cyber scenarios.
Using Personas
The term preference as we use it includes comparison, prioritization, and choice ranking. If preferences are evaluations, therefore, they are valuable to an NPC and provide context to help inform decisions. Preferences also enable an NPC to compare similar things.
As GHOSTS NPCs make more informed and more complex decisions, there is a need for each NPC to (1) have an existing system of preferences when it is created and (2) be able to update those preferences over time as it makes decisions and measures the outcomes. To expedite creating NPCs with similar capabilities, the initial preferences are drawn from a predefined persona. Each persona has a set of ranked interest attributes, such as a preference for news, sports, or entertainment. To maintain an NPC’s heterogeneity, the values of a persona are copied to the individual NPCs randomly. An NPC is therefore assigned to an initial fixed value when a persona has a range for a given preference.
For example, an enclave of NPCs in logistics is drawn from a persona with several applications used to manage logistics tasks. The persona has a range for each of these applications; when agents are created, they get a random fixed number from that range. Among individual NPCs in the enclave, therefore, some prefer application A over B. Interests are typically multi-faceted, so a single NPC can have several interests; decisions must account for these multiple interests.
Including Preferences and Decision Making in ML Models
The goal is for a particular NPC’s browsing history to show patterns that reflect its activities (e.g., reading the news when the NPC starts its shift or shopping for new shoes over lunch). Examining a browsing history should identify overarching tasks. In this case, even a simple pattern that reflects a task is an improvement over purely random browsing.
Purely random browsing was a simple, common use case for most user simulations, but this approach doesn’t mirror human behavior. In human behavior, we can look for specific information or execute a specific task. But purely random browsing produces a browser history that bounces from site to site arbitrarily—with no apparent connections or reason, as though the NPC has no intent behind its browsing activities.
To shift from this arbitrariness, we (1) categorize all the websites an NPC visits and (2) build and apply a preference engine.
Classifying Websites
Classifying the websites that an NPC agent could visit should result in each website being a member of some number of categories. This type of categorization is a machine learning (ML) problem, and ML researchers are continually refining many different approaches to its solution.
Since we control the Internet in any simulation, training, or exercise event, we can pre-classify all websites that an NPC might browse. To do this, we created a list of top sites and categorized them with the same attributes we use to define interests for our NPCs. A simple way to think about categorization is to consider how a web directory might list a particular site. Web searches have become ubiquitous, so web directories aren’t as broadly used, but they still exist. For our purposes, DMOZ (short for directory.mozilla.org) is useful because it offers at least a single category for each site in our listing:
- arts
- business
- computers
- games
- health
- home
- kids
- news
- recreation
- reference
- science
- shopping
- society
Cross-referencing our list of domains with a category enabled us to align NPC browsing to the sites that match their preferences. We polled each site and captured relevant metadata—including the site’s keywords and description to cross-reference that information with our selected NPC categories. We did this cross-referencing by performing simple keyword matching for the keywords we previously built for our NPC categories, which enabled us to cross-reference sites with categories and tag each one appropriately, as shown in Table 1:

As GHOSTS agents make more informed and complex decisions, there is a need for each agent to have a system of preferences existing at the time the agent is created, and for an ability to update those preferences over time as the agent continues to make decisions and measure the outcome of those decisions afterward. To implement this capability, we created SPECTRE software, an optional package within the GHOSTS framework that enables GHOSTS agents to make preference-based decisions and to use the outcome of those decisions to learn and evaluate future choices more intelligently.
Our GHOSTS NPCs need a preference that motivates them to select which site to browse next. We represented each preference with a simple key/value pair. Keys can be any unique string, whereas values must be an integer ranging from 100 (representing a strong preference) to -100 (representing a particularly strong dislike). Using this approach, an NPC with a strong preference for computers and a strong dislike for printing would be represented as
[{"computers":100}, {"printing":-100}]
An NPC can have any number of preferences, and while they can have general preferences like “computers,” that preference can also be far more precise, perhaps indicating a specific preferred software application, printer, or file share. See Figure 1 for an example.
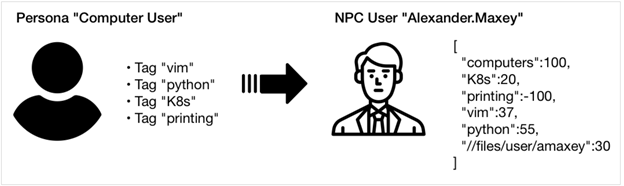
NPCs can collect new preferences and their existing preferences can change over time. These changes are handled transactionally, so increases or decreases in a particular preference are tracked. We can therefore go back to any point in time and determine what an NPC’s preference was and how it has changed.
Now that we have NPCs that prefer to do some things over others, we can look more closely at the tasks they might perform from a browser and how they might browse to complete that task. We can also align an NPC’s preferences to browse for information over lunch so that sports fans can get the latest scores. To accomplish our goal of building an ML model that improves NPC browsing patterns in a way that more closely matches its browsing history to its preferences, we need three sets of data:
- NPC preferences
- current NPC browser history
- list of categorized websites
With this data, we might consider each NPC in terms of the question, “Does your browser history match the content associated with your role and preferences?” As discussed previously, we have a list of websites and their classifications based on their content and a mechanism for assigning a persona to an NPC and acquiring the applicable preference settings. Since the detailed history of every GHOSTS NPC’s action is logged, we can reconstruct any single NPC’s browsing history.
We build an ML model that provides better browsing patterns in the same way that consumer sites use data (e.g., using a shopper’s previous activity or purchase history to recommend products that might interest them). If a shopper is looking for a new laptop, the consumer site might ask them if they are interested in buying an extra laptop charger as well. In our ML model, we ask the NPC these questions:
- Based on (1) sites that you have browsed in the past and (2) a site’s alignment to your preferences, would you browse this site in the future?
- If yes, would you be interested in browsing other sites?
- What might those sites be?
- Are those sites similar to this one?
Similar to consumers having a purchase history, we have an NPC’s browsing history. Using browsing history, we can perform the following steps:
- Determine if the site matches any NPC preferences, either positive or negative.
- Based on the matches found, add or remove the site from the next iteration of sites to browse.
- Based on the final set of sites the NPC is interested in, find sites that are similar to this set.
Step 3 incorporates our ML model, which finds sites similar to the NPC’s preferences after an iteration of browsing. NPC activity should also reflect the randomness that humans sometimes exhibit. We must therefore be careful to allow this type of randomness regardless of how many times the model is run.
Results and Future Research Questions
Using the methodology described here, we iteratively created and adjusted models leading to a 26 percent improvement in an NPC’s ability to browse sites that closely match its preferences. See our report for the full details of our results.
While our results show that an average of an NPC’s browsing history is more aligned to its primary preference, we understand that this is a greatly simplified representation of human browsing behavior. There remains great opportunity for future work to expand the notion of personas and the number of preferences that a single NPC might simultaneously maintain. Similarly, using the results of the model also offers future opportunity to answer questions such as
- Should the length of content an NPC consumes matter? Does long-form content matter more or less?
- Does the frequency of content matter? If an NPC sees content aligned to one preference far more than other preferences, how does that influence the NPC’s overall set of preferences?
- If frequency matters, what happens when an NPC saturates a particular preference? Does an NPC switch from its browser to another application to “take a break?”
- How should we reason about negative preferences? What impact do they have for an NPC in relation to correlating positive preferences?
- How do NPCs implement the results of a decision? For example, does the NPC linger on a page longer when it aligns with its preferences?
Additional Resources
Read the SEI blog post, Generating Realistic Non-Player Characters for Training Cyberteams.
Read the complete SEI technical report from which this blog post was extracted, Using Machine Learning to Increase NPC Fidelity.
Written By




More By The Authors
More In Cyber Workforce Development
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cyber Workforce Development
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed