System Resilience Part 5: Commonly-Used System Resilience Techniques

If adverse events or conditions cause a system to fail to operate appropriately, they can cause all manner of harm to valuable assets. As I outlined in previous posts in this series, system resilience is important because no one wants a brittle system that cannot overcome the inevitable adversities.
- In the first post in this series, I addressed these questions by providing the following, more detailed, and nuanced definition of system resilience: A system is resilient to the degree to which it rapidly and effectively protects its critical capabilities from harm caused by adverse events and conditions.
- The second post identified the eight subordinate quality attributes categorizing the adversities (i.e., adverse conditions and events) that can disrupt the critical system.
- The third post covered the engineering of system resilience requirements and how they can be used to derive related requirements for subordinate quality attributes.
- The fourth post presented an ontology for classifying resilience techniques and clarified the relationships between resilience requirements and resilience techniques.
This fifth post in the series presents a relatively comprehensive list of resilience techniques, annotated with the resilience function (i.e., resistance, detection, reaction, and recovery) that they perform.
Commonly-Used Resilience Techniques
Ideally, the system's requirements will drive the selection of appropriate resilience techniques. It might be appropriate, however, to mandate the use of one or more of the resilience techniques outlined in this post as requirements in the form of architecture and design constraints. Some of these resilience techniques might be more appropriate for use in data centers than in cyber-physical systems, while the reverse may be true for other techniques. Multiple techniques are typically used in concert to address detection, response, and recovery and to provide adequate defense-in-depth.
Although by no means exhaustive, the following is a relatively complete and representative list of resilience techniques (many of these techniques can be further divided into more specific subclasses of resilience techniques):
- Alerts and Warnings—Reaction. Use alerts and warnings to inform operators and administrators of the detection of adverse conditions or events.
- Antivirus Software—Detection/Reaction. Use anti-virus programs to scan for, isolate, and remove malware before it can cause harm.
- Assertion Checking—Detection. Incorporate software that verifies whether assertions (e.g., preconditions and postconditions) are met to detect input errors and output faults/failures. Code-level assertions are typically combined with exception handling.
- Autoscaling—Reaction. Use automatic scaling of computing hardware and software (e.g., virtual machines or containers) to prevent overload during periods of excessive demand.
- Autonomous Cybersecurity Agents—Detection/Reaction/Recovery. Incorporate software agents that autonomously detect and react to adverse security conditions and events. [De Lucia et al. 2019]
- Back-Off Retry Algorithms—Detection/Reaction. Use back-off algorithms that gradually increase the retry rate to avoid network congestion by service-requestor retry messages. Jitter can be added to prevent clusters of retry messages. [Singh 2016]
- Built-in-Test(BIT)—Detection. Incorporate start-up BIT, periodic BIT, or continuous BIT to check for fault and failures.
- Checkpointing—Recovery. A failed application is restarted from an earlier checkpoint (i.e., a recovery) state. Varieties include user-triggered checkpointing, uncoordinated checkpointing, coordinated checkpointing, and message-logging-based checkpointing. Types of checkpointing include user-initiated checkpointing, uncoordinated checkpointing (i.e., processes independently revert to checkpoints), coordinated checkpointing.
- Checksums—Detection. To detect errors in messages, use the checksum of a message, a modular arithmetic sum of message code words.
- Circuit Breaker Pattern—Reaction /Recovery. Use a circuit breaker object, which sits between a service consumer and a remote service provider, to monitor the success of the message between the two. If the number of consecutive failed attempts exceeds a set threshold, the circuit breaker trips, immediately blocking all further attempts, and sets a timer. After the timeout is over, the circuit breaker permits a few service requests to pass through, and if their number reaches the success threshold, the circuit breaker resets. An example is Netflix Hystrix. [Fowler 2014]
- Clock Synchronization—Reaction. When developing a fault-tolerant real-time system, use a fault-tolerant synchronization algorithm to synchronize replicate processors prior to voting to determine the correct inputs or outputs.
- Concurrency Techniques—Detection. The software of most systems is distributed (e.g., across containers, virtual machines, cores, processors, and computers). This distribution leads to concurrent behavior, a lack of determinism, and concurrency defects. To the extent practicable, use the software design to check for the effects of such defects (e.g., decreased performance, messages out of order) and appropriately handle the associated adverse conditions (e.g., starvation, deadlock, livelock, priority inversion, race conditions) and resulting adverse events.
- Containerization—Reaction /Recovery. Use containers to limit failure propagation and to make recovery from failure easier and faster. Combine with redundancy, implementation diversification, and voting to limit the ability of a cyberattack taking out all replicates. [Benameur 2013]
- Content Caching—Reaction. In cases where stale data is acceptable, cache content to ensure service continuity in the event of database-related disruptions. Assign cached data a time-to-live, so that expired content can be replaced. Pick an appropriate cache size to avoid eviction of the cached data. [Johnson 2017]
- Cyclic Redundancy Checks—Detection. A cyclic redundancy check is an error-detecting code that is attached to a block of data and used to detect data accidental or malicious data corruption.
- Data Type Checking—Detection. Use strong data typing and verify whether the type of input data is correct. Input range checking and reasonableness checking are special cases.
- Degraded Mode Operations—Reaction. To avoid complete failure, gracefully switch from normal operations to a well-defined appropriate, degraded mode of operations. The system's delivery of services can be degraded and restored in multiple ways:
- Decreased performance or capacity
- Use of a service variant with higher performance at the cost of lower quality
- Priority-based service loss (i.e., complete or partial loss of less important system capabilities)
- Priority-based service restoration (i.e., restore the most important services first)
- Denial of Service Monitoring—Detection. Monitor the amount of inbound network traffic for signs of a denial of service attack so that the target of the attack can be isolated and the sources of the attack can be identified. [Marsh 2017]
- Digital Signatures—Detection. Use a digital signature to detect violation of data authenticity, confidentiality, and integrity.
- Disagreement Detector—Detection. Use software that checks the consistency of outputs of executing redundant components to detect (but not locate) faulty output.
- Error Correcting Code—Detection/ Reaction. Add redundant data to messages that enable errors to be detected and the message to be reconstituted. [Butler 2012]
- Elastic Load Balancing—Detection/Reaction. Use load balancers to prevent overload during periods of excessive demand.
- Electromagnetic (EM) Shielding—Resistance. Shield electronics and electrical components from electromagnetic fields, electrostatic fields, and radio frequency electromagnetic radiation from natural and adversarial sources.
- Exception Handling—Reaction. Use the programming language's exception handling mechanism to notify client software units of faults and failures (e.g., violations of preconditions or postconditions). Where practical, handle thrown exceptions as close as practical to the unit that threw the exception because the proper handling mechanism becomes less obvious the farther away the handling unit is from the throwing unit.
- Failover—Reaction. In case of failure, incorporate automatic failover to redundant hardware or software (e.g., virtual machine or container). To maximize resilience by minimizing down time, hot failover is preferable to warm failover, which is preferable to cold failover.
- Fault Detection and Isolation (FDI)—Detection. Use software that checks the correctness of the output of a single executing component that is used to both detect and locate a faulty component.
- Fault/Failure Notification Messages—Reaction. Combine the use of fault/failure notification messages with a database linking notification messages with their appropriate fault/failure reactions.
- Fire Detection and Suppression System (FDSS)—Detection/Reaction. Add a subsystem that detects and suppresses fires.
- Hash Functions—Detection. Use a cryptographic hash function to produce a secure checksum that can be used to verify the integrity and authenticity of data (i.e., to detect accidental or malicious data corruption).
- Health Checkers—Detection. Use a health checker (e.g., as part of a load balancer) to send health check messages to resource providers at a given rate. The health check can be shallow (Is the resource provider operational?) or deep (Are the resources on which the provider depends operational?). Other types of health checkers can identify faults (e.g., in hard drives).
- Heartbeat—Detection. Use a heartbeat, a periodic signal sent by hardware or software component, to indicate that the component is still operational. Failure to receive heartbeats (typically a few in a row) indicates component failure.
- Idempotent Operations—Detection. Implement services using idempotent operations (i.e., operations that can be repeated and always produce the same result without causing faults or failures). For example, use unique traceable request identifiers so that request status can be verified, and duplicate requests can be properly handled (e.g., ignored).
- Immutable Server Pattern—Recovery. Instead of updating/fixing a server by applying configuration changes, destroy the server and rebuild it from a known, well-tested base image that resets the server's elements to a known state. [Fowler 2013]
- Implementation Diversity (a.k.a., heterogeneous redundancy)—Detection/ Reaction. Implement replicated components using different programming languages or different compilers, different libraries providing the same functionality, operating systems or versions of an OS, computer hardware, sensor types, and vendors. Implementation diversity combined with monitoring/voting can detect faults, failures, and cybersecurity attacks. It can also help ensure that no common cause failures take down all redundant component instances. [Benameur 2013]
- Infrastructure as Code—Recovery. Automate the building of the software infrastructure (operating systems and middleware) using configuration scripts for rapid recovery.
- Interlock—Detection/Reaction. Use a mechanical, electrical, or trapped key interlock to detect the hazard and prevent the associated accident.
- Intrusion Detection/Prevention System (IDS/IPS)—Detection/ Reaction. Incorporate a commercial off-the-shelf system that detects and prevents intrusions. [Fuchsberger 2005]
- Line Replaceable Units (LRUs)—Recovery. To enable modular recovery, include pieces of hardware that can be exchanged for a replacement part in a relatively short time by only opening and closing fasteners and connectors (i.e., LRUs) in the system architecture. Lockstepping--Detection. Execute multiple redundant components in lockstep and compare the outputs for consistency prior to being committed.
- Logging—Reaction/Recovery. Log all adverse conditions, adverse events, faults, and failures to support fault isolation and manual recovery.
- Parity Bits—Detection. Prior to transmission, use a parity bit generator to add a bit to a group of source bits, so that the number of bits set to 1 is even (or odd). After receipt of the source bits, a parity bit checker confirms that the number of set bits is still even (or odd). This technique detects flipped bits when an odd number of bits have been flipped.
- Physical Separation—Resistance. Physically distribute assets (e.g., data, hardware, and software) either locally or geographically, so that an adverse event (e.g., attack, fire, or power blackout) does not disrupt all copies of any single asset. Examples include not running redundant network wiring together so that shrapnel or fire does not damage both wires. [Lindskog et al. 2005]
- Prognostics and Health Monitoring (PHM)—Detection. Incorporate a prognostics and health monitoring subsystem to
- Provide projections concerning hardware components approaching end-of-life, so that they may be replaced before a fault or failure occurs (Prevention--not resilience)
- Monitor the health of other subsystems and react appropriately to adverse conditions and adverse events (Detection) [Atamuradov et al. 2017]
- Radiation Hardening—Resistance. Provide shielding to protect integrated circuits and hard drives from flipped bits due to ionizing radiation.
- Reconfiguration—Recovery. Reconfigure the system to either (1) ignore components such as processors and sensors that have failed or (2) replace a failed component with a spare (i.e., back-up) component. [Butler 2012]
- Redundancy—Response. Incorporate redundancy of various components of the system to support failover or reconfiguration.
- Repetition Codes—Detection/ Reaction. Repeat each block of data transmitted a specified number of times and use the value of the most common block as the correct value.
- Reserve Capacity—Resistance. Provide excess reserve processing and memory capacity to handle excessive load conditions and load spike events.
- Robustness Watchdog—Detection/ Reaction. Incorporate a robustness watchdog to monitor for (and react to) faults and failures (e.g., by killing faulty applications in virtual machines/containers and spawning their replacements).
- Safety/Security Sentinel—Detection. Incorporate a safety sentinel to monitor system safety (e.g., identifying hazards, responding to accidents) and a security sentinel to monitor system security (e.g., violations of security policy and integrity of sensitive data).
- Safe-Life Design—Resistance. Incorporate hardware that has an excessively long useful life to increase longevity and thereby resist excessive lifespans.
- Sensor Verification—Detection/ Reaction. Check the reasonableness of sensor outputs and compare the outputs of redundant sensors to detect sensor failure and determine which sensors are providing reasonable information. Sensors can become dirty and/or physically fail and provide inadequate information under certain environmental conditions (e.g., visible-light cameras during dense fog and lidar during heavy rain or snow). [Javed and Wolf 2012]
- Stateless Software Applications—Reaction /Recovery. To simplify response and recovery, use stateless software applications that are only dependent on input parameters as opposed to some kind of stored data. [Mergen 2015]
- Surge Protector—Detection/Reaction. Use a surge protector to protect electrical equipment from damaging power surges.
- Timeouts—Detection/ Reaction. When service requests (e.g., database queries) take excessive time to complete, so that requesting threads might rapidly exceed the number of available connections, use timeouts so that connections are made available for other requestors.
- Voting—Reaction. Use voting to determine which redundant component failed and to determine which output to use.
- Virtualization—Reaction /Recovery. Use virtual machines and hypervisors to limit failure propagation and to make recovery from failure easier and faster. Combine with redundancy, implementation diversification, and voting to limit the ability of a cyberattack to take out all replicates. [Benameur 2013]
- Vulnerability Removal—Resistance. Remove safety and security vulnerabilities so that hazards and threats do not lead to accidents and successful attacks.
- Watchdog Timer(WDT)—Detection/Recovery. Use a watchdog timer to automatically restart a failed computer. A watchdog timer resets a computer (primarily embedded computers) if the computer does not regularly reset the watchdog's timer (i.e., if the watchdog times out).
Redundancy-Based Resilience Techniques
Redundancy is very important to resilience. It is therefore worth examining the types (and associated subtypes) of redundancy. The following UML class diagram illustrates many of the most commonly used redundancy techniques that support resilience:
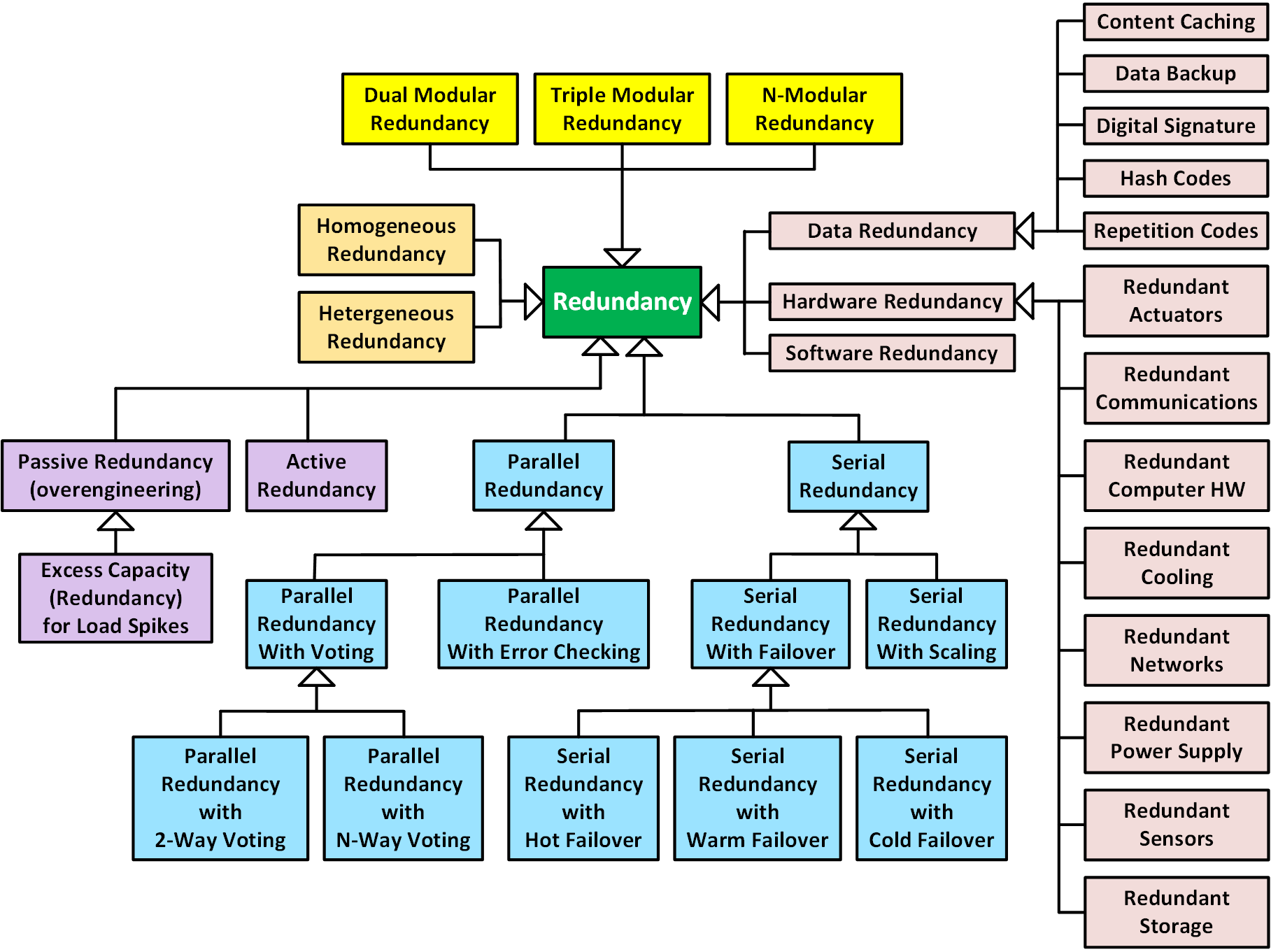
- Yellow subclasses. Redundancy can be classified in terms of the number of copies or variants used to provide the redundancy.
- Orange subclasses. Redundancy can be either homogeneous (i.e., duplication producing identical copies of hardware, operating system, of software) or heterogeneous (i.e., creation of non-identical variants, such as different hardware, operating system, or programming language).
- Purple subclasses. Redundancy can be passive (e.g., by overengineering an excess number of redundant components to meet excessive loads or address component failure) or active redundancy (i.e., proper use of redundancy requires the detection of, reaction to, and recovery from adversity).
- Blue subclasses. Redundancy can be parallel (if the redundant components execute in concurrently) or serial (if the components execute sequentially). Parallel redundancy can further be decomposed based on whether identification of correct processing is determined by voting or by using error checking software. Parallel redundancy with voting is further classified by the number of redundant components, the outputs of which are being compared. Conversely, serial redundancy (a.k.a., temporal redundancy) is typically implemented using hot, warm, or cold failover from a malfunctioning component into a redundant component. To meet adversely high loads, scaling (e.g., in cloud computing data centers) can be achieved by spinning up redundant servers, software containers, or software virtual machines as needed.
- Pink subclasses. Redundancy can include some combination of redundant data, redundant hardware, and redundant software (e.g., via containers and virtual machines).
The four main classifications of redundancy above are orthogonal and any specific implementation typically involves instantiating each of these classification hierarchies. For example, parallel redundancy with voting is a form of active redundancy that typically involves both redundant hardware and software, each of which can be either homogeneous or heterogeneous.
Wrapping Up and Looking Ahead
There are clearly many techniques that can be used to implement system resilience requirements. These techniques can be categorized in multiple ways, the two most important of which are by resilience function and by implementation. This abundance of techniques and types of techniques provides system architects and specialty engineers with a great deal of flexibility when it comes to ensuring a sufficient resilience, especially when a multi-layer defense-in-depth approach is used. On the other hand, incorporating resilience techniques increases system complexity and can therefore, paradoxically, make the system less resilient. Selecting the right number, type, and balance of resilience techniques is anything but trivial.
The next post in the series will address the testing and evaluation of a system's resilience.
Additional Resources and References
Read previous posts in this series:
[Atamuradov et al. 2017] Vepa Atamuradov, Kamal Medjaher, Pierre Dersin, Benjamin Lamoureux, and Noureddine Zerhouni, "Prognostics and Health Management for Maintenance Practitioners - Review, Implementation and Tools Evaluation," International Journal of Prognostics and Health Management, 2017 [https://www.phmsociety.org/node/2246]
[Benameur 2013] Azzedine Benameur, Nathan S. Evans, and Matthew C. Elder, "Cloud Resiliency and Security via Diversified Replica Execution and Monitoring," 6th International Symposium on Resilient Control Systems (ISRCS), July 2013 [https://ieeexplore.ieee.org/document/6623768]
[Butler 2012] Ricky Butler, "Fault-tolerant Clock Synchronization Techniques for Avionics Systems," 17 August 2012 [https://doi.org/10.2514/6.1988-4408]
[De Lucia et al. 2019] Michael J. De Lucia, Dr. Allison Newcomb, and Dr. Alexander Kott, "Features and Operation of an Autonomous Agent for Cyber Defense," Journal of Cyber Security and Information Systems, Vol. 7, No. 1, 29 April 2019.
[Fowler 2013] Martin Fowler, "ImmutableServer," martinFowler.com, 13 June 2013 [https://martinfowler.com/bliki/ImmutableServer.html]
[Fowler 2014] Martin Fowler, "Circuit Breaker," martinFowler.com, 6 March 2014 [https://martinfowler.com/bliki/CircuitBreaker.html]
[Fuchsberger 2005] Andreas Fuchsberger, "Intrusion Detection Systems and Intrusion Prevention Systems," Information Security Technical Report, Vol. 10, Issue 3, pp 134-139, 2005. [https://www.sciencedirect.com/science/article/pii/S1363412705000415]
[Javed and Wolf 2012] Nauman Javed and Tilman Wolf, "Automated Sensor Verification using Outlier Detection in the Internet of Things," 32nd International Conference on Distributed Computing Systems Workshops, IEEE Computer Society, 2012
[Lindskog et al. 2005] Stefan Lindskog, Karl-Johan Grinnemo, and Anna Brunstrom, "Data Protection Based on Physical Separation: Concepts and Application Scenarios," International Conference on Computational Science and Its Applications (ICCSA) 2005: Computational Science and Its Applications, pp 1331-1340, 9-12 May 2005. https://doi.org/10.1007/11424925_138
[Johnson 2017] Justin Johnson, "What is Content Caching?" Stackpath, 24 May 2017. [https://blog.stackpath.com/glossary-content-caching/]
[Marsh 2017] Jennifer Marsh, "DDoS Monitoring: How to Know When You're Under Attack," Solarwinds Loggly, 25 January 2017. [https://www.loggly.com/blog/ddos-monitoring-how-to-know-youre-under-attack/]
[Mergen 2015] Leon Mergen, "On Stateless Software Design," 3 December 2015 [https://leonmergen.com/on-stateless-software-design-what-is-state-72b45b023ba2]
[Singh 2016] Rahul Rajat Singh, "Understanding Retry Pattern with Exponential Back-Off and Circuit Breaker Pattern," Rahul Rajat Singh's Blog, 7 October 2016, [http://rahulrajatsingh.com/2016/10/understanding-retry-pattern-with-exponential-back-off-and-circuit-breaker-pattern/]
Written By

More By The Author
More In Cybersecurity Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cybersecurity Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed