Explainability in Cybersecurity Data Science


Cybersecurity is data-rich and therefore a natural setting for machine learning (ML). However, many challenges hamper ML deployment into cybersecurity systems and organizations. One major challenge is that the human-machine relationship is rooted in a lack of explainability. Generally, there are two directions of explainability in cybersecurity data science:
- Model-to-Human: predictive models inform the human cyber experts
- Human-to-Model: human cyber experts inform the predictive models
When we build systems that combine both directions, we encourage a bidirectional, continuous relationship between the human and machine. We consider the absence of this two-way relationship a barrier to adopting ML systems at the cybersecurity-operations level. On a very basic level, explainable cybersecurity ML can be achieved now, but there are opportunities for significant improvement.
In this blog, we first provide an overview of explainability in ML. Next, we illustrate (1) model-to-human explainability with the ML model form of cybersecurity decision trees. We then illustrate (2) human-to-model explainability with the feature engineering step of a cybersecurity ML pipeline. Finally, motivated by the progress made toward physics-informed ML, we recommend research needed to advance cybersecurity ML to achieve the level of two-way explainability necessary to encourage use of ML-based systems at the cybersecurity operations level.
The Demand for Explainability
As ML-based systems increasingly integrate into the fabric of daily life, the public is demanding increased transparency. The European Union encoded into law the individual’s right to an explanation when decisions made by automated systems significantly affect the individual (refer to the General Data Protection Regulation Article 22 and Recital 71). While this far-reaching regulation illustrates the importance of explainability, generating such explanations for complex ML models remains a significant challenge.
In the United States, the SEI is home to the National Artificial Intelligence (AI) Engineering Initiative aimed at establishing and growing the discipline of AI engineering. Human-centered AI is the first pillar of AI engineering, and one of its key principles is that the users' willingness to adopt an AI system depends on their perception that the system is being accountable and transparent. Yet transparency remains a significant challenge for complex ML models.
A widely cited article in Nature Machine Intelligence implores readers to use interpretable ML models, especially for high stakes decisions. The author draws a distinction in which explainable methods are techniques for interrogating complex ML models to help understand why a given prediction was made, whereas interpretable models admit the explicit rules followed for each prediction.
In cybersecurity, there is a significant body of academic research, including recent surveys into ML-based methods. The literature includes ML-based supplementation of many cybersecurity tasks, including malware detection and analysis, intrusion detection, and advanced persistent threat detection. The methods developed by much of this research, however, suffer from lack of explainability. This weakness is acute for the most complex (and often most effective) models, such as neural networks, as well as ensemble methods that aggregate the predictions of many sub-models. Such models are called black box because they are extremely hard to interpret directly. It is nearly impossible for an end user to understand why a given black box model makes a given prediction. The user is burdened with choosing whether to accept the model prediction, and without any supporting information, it is reasonable to simply not trust the model.
Model-to-Human Explainability: An Example
The decision tree was one of the earliest ML model forms to be developed, and it is still useful today. They admit human readable rules in the form of if-then statements, such as
if user ID is within {employee 1, employee 2,...},
and if timestamp is between 8:00 AM and 5:00 PM,
and if DNS query is within {amazonaws.com, cisa.gov,...},
then suspicious = FALSE.
In terms of model-to-human explainability, the decision tree is completely transparent and interpretable. This transparency is especially true when there are a reasonable number of predictor variables, or at least a reasonable number of strong predictor variables.
After a decision tree is trained, its rules can be implemented directly into software solutions without having to use the ML model object. These rules can be presented visually in the form of a tree image (see Figure 1 for example), easing communication to non-technical stakeholders. The rules can be reviewed for sensibility by end users and subject matter experts. The model can even be customized to modify or eliminate non-sensible decision sequences, producing a model objectively trained with data and then fine-tuned with human expertise, aligned with both model-to-human and human-to-model explainability.
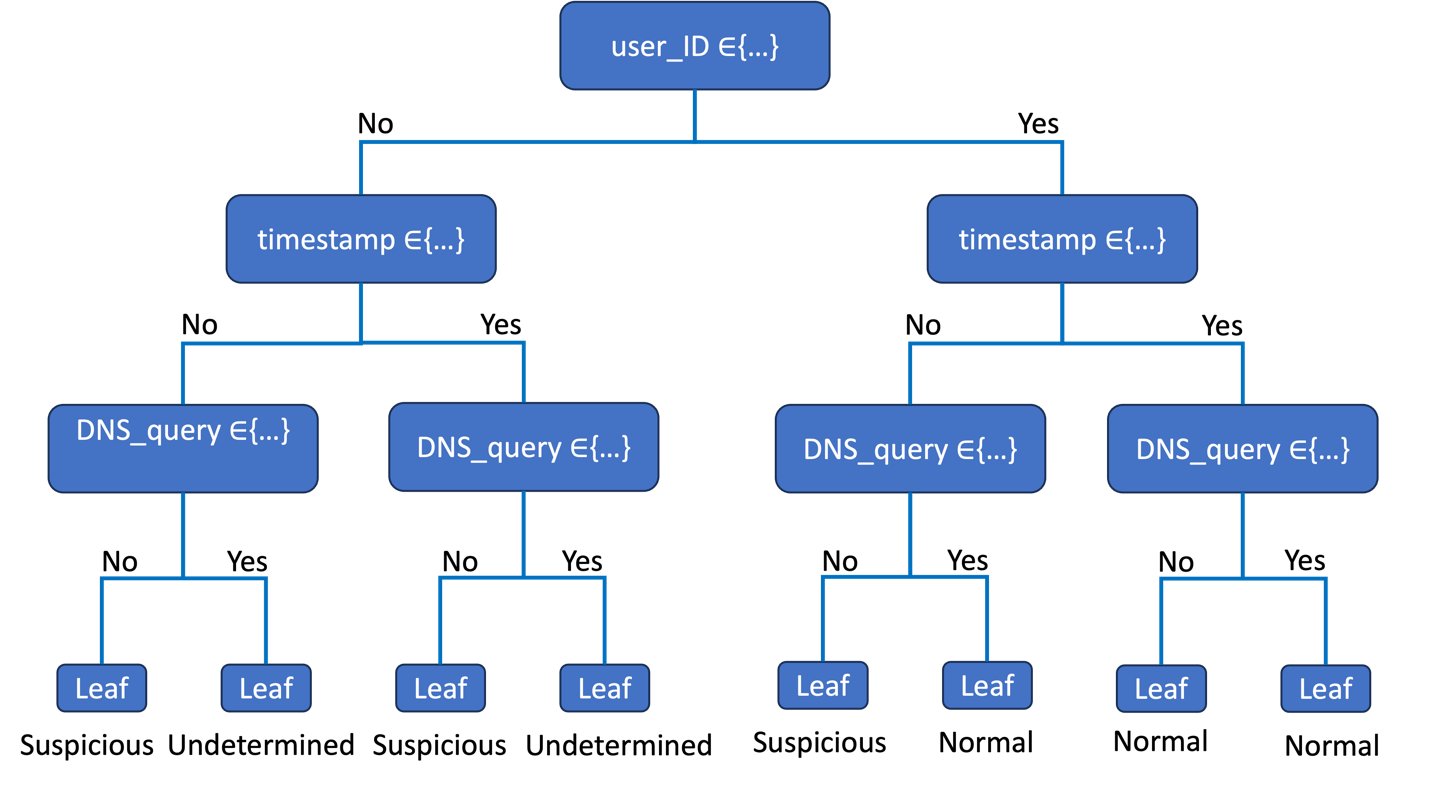
In addition, visually inspecting the model provides quick and intuitive insights into what features the training algorithm estimated to be most predictive of the response. The predictor variable associated with the root node can be interpreted as most important to, or most predictive of, the response variable. The predictor variables associated with the second tree level can be interpreted as the next most predictive of the response, and so on. This aspect of decision trees builds trust within the human-machine team by improving communication and enabling sensibility checking by stakeholders.
Although there is a common perception that complex models are more accurate than simpler models, this perception is not necessarily true. For example, a survey by Xin et al. compares the performance of various model forms, developed by many researchers, on benchmark cybersecurity datasets. This survey shows that a relatively simple ML model form, like that of a decision tree, often performs similarly to more opaque ML model forms, like neural networks and support vector machines.
There are also research opportunities to improve decision tree model performance. Determining an optimal decision tree structure (i.e., the root node, decision nodes, splitting criteria, and leaf nodes) can be intractable for even moderately sized data sets. Therefore, tree construction often uses greedy approximation algorithms.
CART, ID3, and C4.5 are three classic greedy tree construction algorithms. They use a top-down greedy approach in which the training data are recursively partitioned into smaller and smaller subsets until some stopping criterion is met, at which point a label is assigned to each subset corresponding to a leaf node. At each candidate decision node, a predictor variable and splitting rule are determined greedily by either minimizing or maximizing various measures, such as Gini impurity, information gain, and entropy. Finally, the resulting tree is pruned in attempt to avoid overfitting by balancing the complexity introduced by each decision node against the predictive accuracy enabled by the node. Recently, advances have been made in determining optimal decision tree structures using mixed integer linear programming techniques.
Aside from explainability, there are of course other advantages and disadvantages of decision trees. Advantages include that they can model non-linear data; they are nonparametric, meaning that they make no assumptions about the underlying data, as is required for certain statistical models; and decision trees can require less data pre-preprocessing than other ML model forms (e.g., they do not require centering and scaling). Disadvantages of decision trees include that they can be prone to overfitting; tree structure can be sensitive to small changes in the input data; and interpretability degrades as the tree size grows (i.e., there is a tradeoff between model complexity and interpretability).
Human-to-Model Explainability: An Example
The pervasiveness of categorical data in cybersecurity necessitates feature engineering as an early step in the ML pipeline. A variable is categorical (as opposed to numerical) when its range of possible values is a set of categories. In cybersecurity, these categorical variables are usually non-ordinal, meaning there is no natural sense of sequence and scale.
Examples of non-ordinal categorical variables in cybersecurity include IP addresses, port numbers, protocols, process names, event names, and usernames. Compared to ordinal numeric data, these non-ordinal categorical variables contain less information to be used for learning. Moreover, ML requires that categorical data first be encoded numerically. There are many methods for doing so including
- Integer encoding assigns an integer to each unique category.
- One-hot encoding introduces a new binary variable for each unique category. For example, one-hot encoding a variable that can take one of three values (red, blue, green) would introduce three new binary variables: red=[1,0,0], blue=[0,1,0], and green=[0,0,1].
- Target encoding replaces each category with some measure (usually the mean value) of the target variable for all training points belonging to that respective category.
Cyber data poses several challenges to these encoding strategies. With integer encoding, care must be taken not to inadvertently impute some notion of ordinality that does not exist in underlying data. With one-hot encoding, care must be taken not to significantly increase problem dimensionality by introducing tens or even hundreds of new binary variables. With target encoding, the cyber response variable itself is often categorical (e.g., benign or malicious), requiring some special treatment prior to applying target encoding.
Cyber-specific encoding can mitigate these challenges, while also allowing the human cyber expert to impart their domain expertise into the predictive model. This approach helps focus the model on what is already known to be important by the human experts. It can reduce dimensionality by compressing high dimensional categorical variables into a smaller number of categories that are known to be important.
For example, consider user ID data consisting of 50 unique categories. Perhaps what is important for a particular application is not the user ID itself, but whether it is associated with the operating system or a human user. In this case the cyber-specific encoding might compress a categorical variable of 50 levels down to a binary variable with only two levels. Highnam et al. provide a good example of cyber-specific encoding (see Appendix A of their paper) on a real cybersecurity dataset they harvested for anomaly detection research.
Broader Adoption of Data Science in Cybersecurity Through Explainability: Conclusions and Future Research
Significantly strengthening the human-machine team through explainable cybersecurity ML is one of the biggest steps we can take to encourage broader adoption of data science into cybersecurity organizations and systems. The SEI is working to define and mature the field of AI engineering, including its central tenet of human-centered AI. AI engineering principles can be extended into the cybersecurity domain in several ways, including improving explainability of black box models that perform well on cybersecurity tasks; improving the performance of interpretable models such as decision trees to be competitive with black box models; and most importantly by developing methods in which humans can impart their cybersecurity expertise into predictive models.
Additional Resources
The Carnegie Mellon University Software Engineering Institute, AI Engineering: A National Initiative. https://www.sei.cmu.edu/our-work/projects/display.cfm?customel_datapageid_4050=311883. Accessed: 2023-08-29.
A. Alshamrani, S. Myneni, A. Chowdhary, and D. Huang, A survey on advanced persistent threats: Techniques, solutions, challenges, and research opportunities, IEEE Communications Surveys & Tutorials, 21 (2019), pp. 1851–1877.
H. Barmer, R. Dzombak, M. Gaston, J. Palat, F. Redner, C. Smith, and T. Smith, Human-Centered AI. https://resources.sei.cmu.edu/asset_files/WhitePaper/2021_019_001_735364.pdf. Accessed: 2023-08-29.
D. Bertsimas and J. Dunn, Optimal classification trees, Machine Learning, 106 (2017), pp. 1039–1082.
A. L. Buczak and E. Guven, A survey of data mining and machine learning methods for cyber security intrusion detection, IEEE Communications Surveys & Tutorials, 18 (2015), pp. 1153–1176.
D. Dasgupta, Z. Akhtar, and S. Sen, Machine learning in cybersecurity: a comprehensive survey, The Journal of Defense Modeling and Simulation, 19 (2022), pp. 57–106.
European Parliament and Council of the European Union, Regulation (EU) 2016/679 of the European Parliament and of the Council.
D. Gibert, C. Mateu, and J. Planes, The rise of machine learning for detection and classification of malware: Research developments, trends and challenges, Journal of Network and Computer Applications, 153 (2020), p. 102526.
B. Goodman and S. Flaxman, EU regulations on algorithmic decision-making and a “right to explanation”, in ICML Workshop on Human Interpretability in Machine Learning (WHI 2016), New York, NY. http://arxiv.org/abs/1606.08813v1, 2016.
Z. Hao, S. Liu, Y. Zhang, C. Ying, Y. Feng, H. Su, and J. Zhu, Physics-informed machine learning: A survey on problems, methods and applications, arXiv preprint, arXiv:2211.08064, (2022).
K. Highnam, K. Arulkumaran, Z. Hanif, and N. R. Jennings, BETH dataset: Real cybersecurity data for anomaly detection research, Training, 763 (2021), p. 8.
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, Physics-informed machine learning, Nature Reviews Physics, 3 (2021), pp. 422–440.
C. Rudin, Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead, Nature Machine Intelligence, 1 (2019), pp. 206–215.
K. Shaukat, S. Luo, V. Varadharajan, I. A. Hameed, and M. Xu, A survey on machine learning techniques for cyber security in the last decade, IEEE Access, 8 (2020), pp. 222310–222354.
D. Ucci, L. Aniello, and R. Baldoni, Survey of machine learning techniques for malware analysis, Computers & Security, 81 (2019), pp. 123–147.
Y. Xin, L. Kong, Z. Liu, Y. Chen, Y. Li, H. Zhu, M. Gao, H. Hou, and C. Wang, Machine learning and deep learning methods for cybersecurity, IEEE Access, 6 (2018), pp. 35365–35381.
Written By


More By The Authors
More In Cybersecurity Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cybersecurity Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed