MXNet: A Growing Deep Learning Framework

Deep learning refers to the component of machine learning (ML) that attempts to mimic the mechanisms deployed by the human brain. It consists of forming deep neural networks (DNNs), which have several (hidden) layers. Applications include virtual assistants (such as Alexa and Siri), detecting fraud, predicting election results, medical imaging for detecting and diagnosing diseases, driverless vehicles, and deepfake creation and detection. You may have heard of TensorFlow or PyTorch, which are widely used deep learning frameworks. As this post details, MXNet (pronounced mix-net) is Apache’s open-source spin on a deep-learning framework that supports building and training models in multiple languages, including Python, R, Scala, Julia, Java, Perl, and C++.
An Overview of MXNet
Along with the aforementioned languages, trained MXNet models can be used for prediction in MATLAB and JavaScript. Regardless of the model-building language, MXNet calls optimized C++ as the back-end engine. Moreover, it is scalable and runs on systems ranging from mobile devices to distributed graphics processing unit (GPU) clusters. Not only does the MXNet framework enable fast model training, it scales automatically to the number of available GPUs across multiple hosts and multiple machines. MXNet also supports data synchronization over multiple devices with multiple users. MXNet research has been conducted at several universities, including Carnegie Mellon University, and Amazon uses it as its deep-learning framework due to its GPU capabilities and cloud computing integration.
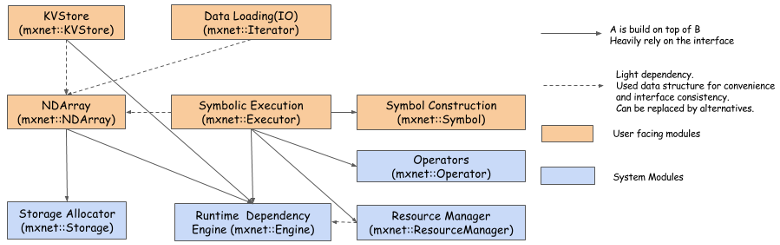
Figure 1 describes MXNet’s capabilities. The MXNet engine allows for good resource utilization, parallelization, and reproducibility. Its KVStore is a distributed key-value store for data communication and synchronization over multiple devices. A user can push a key-value pair from a device to the store and pull the value on a key from the store.
Imperative programming is a programming paradigm where the programmer explicitly instructs the machine on how to complete a task. It tends to follow a procedural rather than declarative style, which mimics the way the processor executes machine code. In other words, imperative programming does not focus on the logic of a computation or what the program will accomplish. Instead, it focuses on how to compute it as a series of tasks. Within MXNet, imperative programming specifies how to perform a computation (e.g., tensor operations). Examples of languages that incorporate imperative programming include C, C++, Python, and JavaScript. MXNet incorporates imperative programming using NDArray, which is useful for storing and transforming data, much like NumPy’s ndarray. Data is represented as multi-dimensional arrays that can run on GPUs to accelerate computing. Moreover MXNet contains data iterators that allow users to load images with their labels directly from directories. After retrieving the data, the data can be preprocessed and used to create batches of images and iterate through these batches before feeding them into a neural network.
Lastly, MXNet provides the ability to blend symbolic and imperative programming. Symbolic programming specifies what computations to perform (e.g., declaration of a computation graph). Gluon, a hybrid programming interface, combines both imperative and symbolic interfaces, while keeping the capabilities and advantages of both. Importantly, Gluon is key to building and training neural networks, largely for image classification, deepfake detection, etc. There is a version of Gluon specifically designed for natural language processing (nlp), as well.
Why MXNet Is Better for GPUs
CPUs are composed of just a few cores with lots of cache memory that can handle a few software threads at a time. In contrast, a GPU is composed of hundreds of cores that can handle thousands of threads simultaneously. The parallel nature of neural networks (created from large numbers of identical neurons) maps naturally to GPUs, providing a significant computation speed-up over CPU-only training. Currently, GPUs are the platform of choice for training large, complex neural network-based systems. Overall, more GPUs on an MXNet training algorithm lead to significantly faster completion time due to the “embarrassingly parallel” nature of these computations.
By default, MXNet relies on CPUs, but users can specify GPUs. For a CPU, MXNet will allocate data on the main memory and try to use as many CPU cores as possible, even if there is more than one CPU socket. If there are multiple GPUs, MXNet needs to specify which GPUs the NDArray will be allocated to. MXNet also requires users to move data between devices explicitly. The only requirement for performing an operation on a particular GPU is for users to guarantee that the inputs of the operation are already on that GPU. The output will be allocated on the same GPU, as well.
Before delving into why MXNet is of interest to researchers, let’s compare available deep learning software. In Table 1 below, I outline some of the key similarities and differences between MXNet, TensorFlow, and PyTorch.
|
MXNet |
TensorFlow |
PyTorch |
|
|
Year Released |
2015 |
2015 |
2016 |
|
Creator |
Apache |
Google Brain |
Facebook members |
|
Deep Learning Priority |
Yes |
Yes |
Yes |
|
Open-source |
|||
|
CUDA support |
Yes |
Yes |
Yes |
|
Simple Interactive Debugging |
Yes |
No |
Yes |
|
Multi-GPU training |
Yes |
Yes |
Yes |
|
Frequent community updates |
Lesser |
Higher |
Lesser |
|
Easy Learning |
Yes |
No (interface changes after every update) |
Yes (Typically if Python User) |
|
Interface for Monitoring |
Table 1: A Comparison of MXNet, TensorFlow, PyTorch
Some other features that are hard to put into the chart include
- TensorFlow, which generally does better on CPU than MXNet, but MXNet generally does better (speed and performance wise) than PyTorch and TensorFlow on GPUs.
- MXNet, which has good ease of learning, resource utilization, and computation speed specifically on GPUs.
Why MXNet Looks Promising
With the rise of disinformation campaigns, such as deepfakes, coupled with new remote work environments brought about by the onslaught of COVID, deep learning is increasingly important in the realm of cybersecurity. Deep learning consists of forming algorithms made up of deep neural networks (DNNs) that have multiple layers, several of which are hidden. These deep learning algorithms are used to create and detect deepfakes. As DarkReading noted in a January 2022 article, malicious actors are deploying increasingly sophisticated impersonation attempts and organizations must prepare for the increasingly sophisticated threat of deepfakes. “What was a cleverly written phishing email from a C-level email account in 2021 could become a well-crafted video or voice recording attempting to solicit the same sensitive information and resources in 2022 and beyond.”
The rise in deepfakes has also brought about a rise in the number of available deep learning frameworks. MXNet appears able to compete with two of the top industry frameworks, and could be a suitable piece for further research or to use in one’s research projects, including deepfake detection, self-driving cars, fraud detection, and even natural language processing applications. Deepfake detection is already being researched here at the SEI by my colleagues Catherine Bernaciak, Shannon Gallagher, Thomas Scanlon, Dominic Ross, and myself.
MXNet has limitations, including having a relatively small community of members that update it, which limits their ability to fix bugs, improve content, and add new features. MXNet is not as popular as TensorFlow and PyTorch, even though it is actively used by businesses like Amazon. Despite these limitations, MXNet is a computationally efficient, scalable, portable, fast framework that provides a user-friendly experience to users who rely on several varying programming languages. Its GPU capabilities and high performance make it a deep-learning framework that should be more widely used and known.
In a future post, I will provide details on an interactive notebook that CERT researchers have developed to give users hands-on experience with MXNet.
Additional Resources
Several employees of the CERT Division presented at the SEI Deepfakes Day 2022 on August 30, 2022. Deepfakes Day is a workshop hosted by the SEI that addresses the origins of deepfake media content, its technical underpinnings, and the available methods to detect and mitigate against deepfakes. Dr. William Corvey, Program Manager for DARPA’s SemaFor program, delivered the keynote.
Official MXNET GitHub site:
https://github.com/apache/incubator-mxnet
View the SEI Blog Post How Easy Is it to Make and Detect a Deepfake?
More info on GANs and other types of networks is available at the following link: https://d2l.ai/chapter_generative-adversarial-networks/gan.html
This link offers example tutorials that use MXNet.
Also check out the following articles and papers:
MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systemsh
The Top 5 Deep Learning Frameworks to Watch in 2021 and Why TensorFlow
Top 10 Deep Learning Frameworks in 2022 You Can’t Ignore
The Ultimate Guide to Machine Learning Frameworks
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed