Six Things You Need to Know About Data Governance

Many organizations want to share data sets across the enterprise, but taking the first steps can be challenging. These challenges range from purely technical issues, such as data formats and APIs, to organizational cultures in which managers resist sharing data they feel they own. Data Governance is a set of practices that enable data to create value within an enterprise. When launching a data governance initiative, many organizations choose to apply best practices, such as those collected in the Data Management Association's Body of Knowledge (DAMA-BOK). While these practices define a desirable end state, our experience is that attempting to apply them broadly across the enterprise as a first step can be disruptive, expensive, and slow to deliver value. In our work with several industry and government organizations, SEI researchers have developed an incremental approach to launching data governance that delivers immediate payback. This post highlights our approach, which is based on six principles.
1. A data set produces benefits only when it is used to make decisions.
If we apply best practices, for example, clean a data set, publish its schema, assign a data steward, and layer on an open API, but nobody ever uses the data set, then we have not produced any direct benefits. Decisions and action produce benefits, and until we use a data set to support decision-making, it is just incurring costs. (We acknowledge that a data set that is "ready to go" has option value, but that should not be your initial data governance focus).
2. Value ≣ ∑benefits - ∑costs
The value of a data set is the sum of the benefits it produces (that is, the benefits of the decisions that the data set supports) minus the sum of the costs to use the data set. Obviously, we want this value to be positive.
3. Data has a value chain
The value chain for a data set has four moving parts, as shown here:
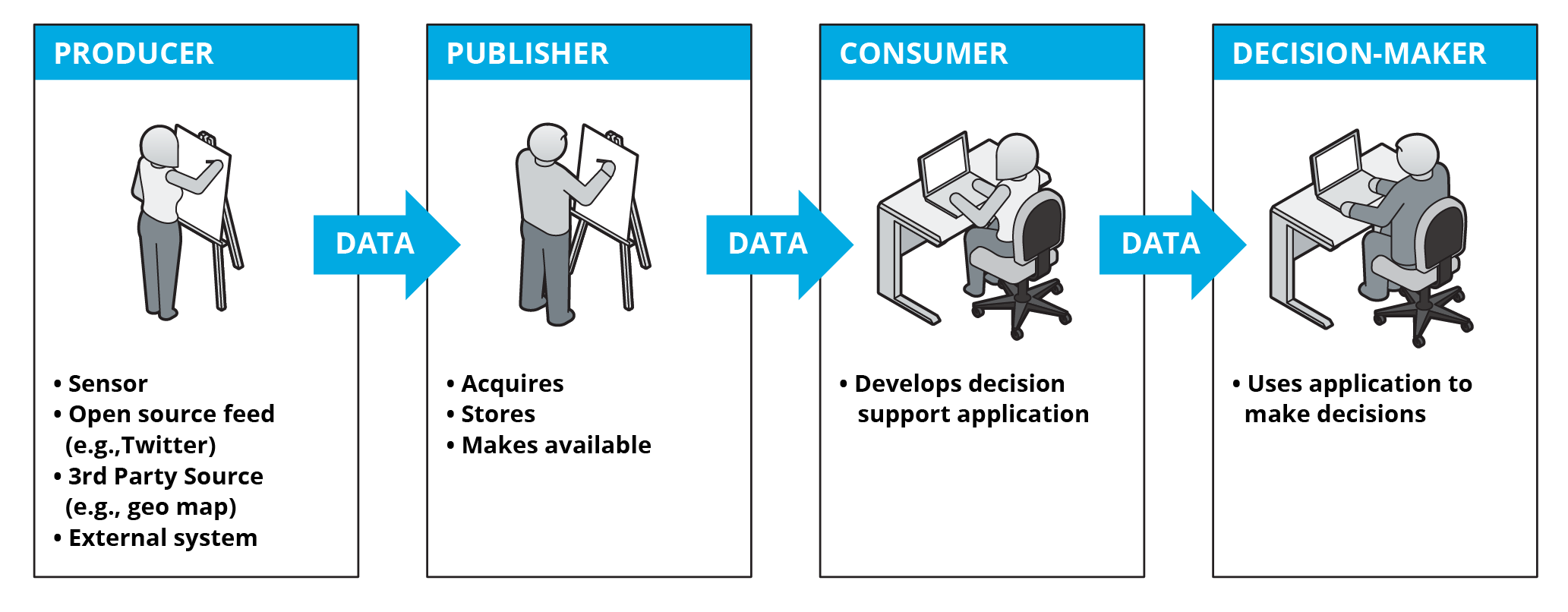
The first part is the data Producer, which could be a sensor, open source feed, or another system. Next, a Publisher acquires the data set, stores it, and makes it accessible within the enterprise. A Consumer develops a decision support application or analytic that uses the data set, and a Decision-Maker uses the application to make decisions. There are variations, where a single entity plays more than one role. For example, the Producer may also publish, or the Consumer may also be the Decision-Maker.
For our scope of data sharing within an enterprise, in almost all cases the first three parts only incur cost and benefits are only produced by the Decision-Maker.
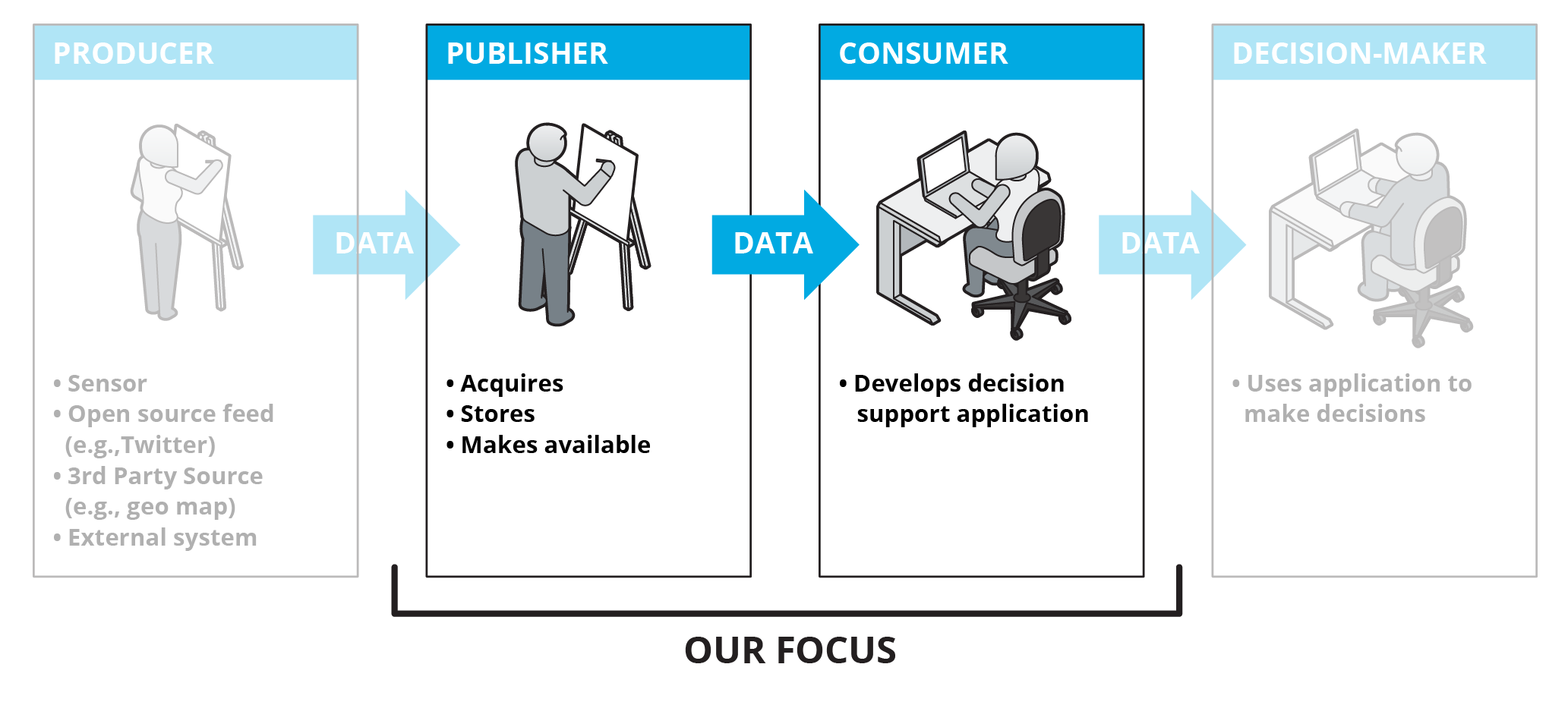
We are going to focus on the Publisher and Consumer. In many cases, the Producer is outside the scope of our authority, and the Decision-Maker is executing a business or mission process that is also outside of our authority. We'll focus on things we can control.
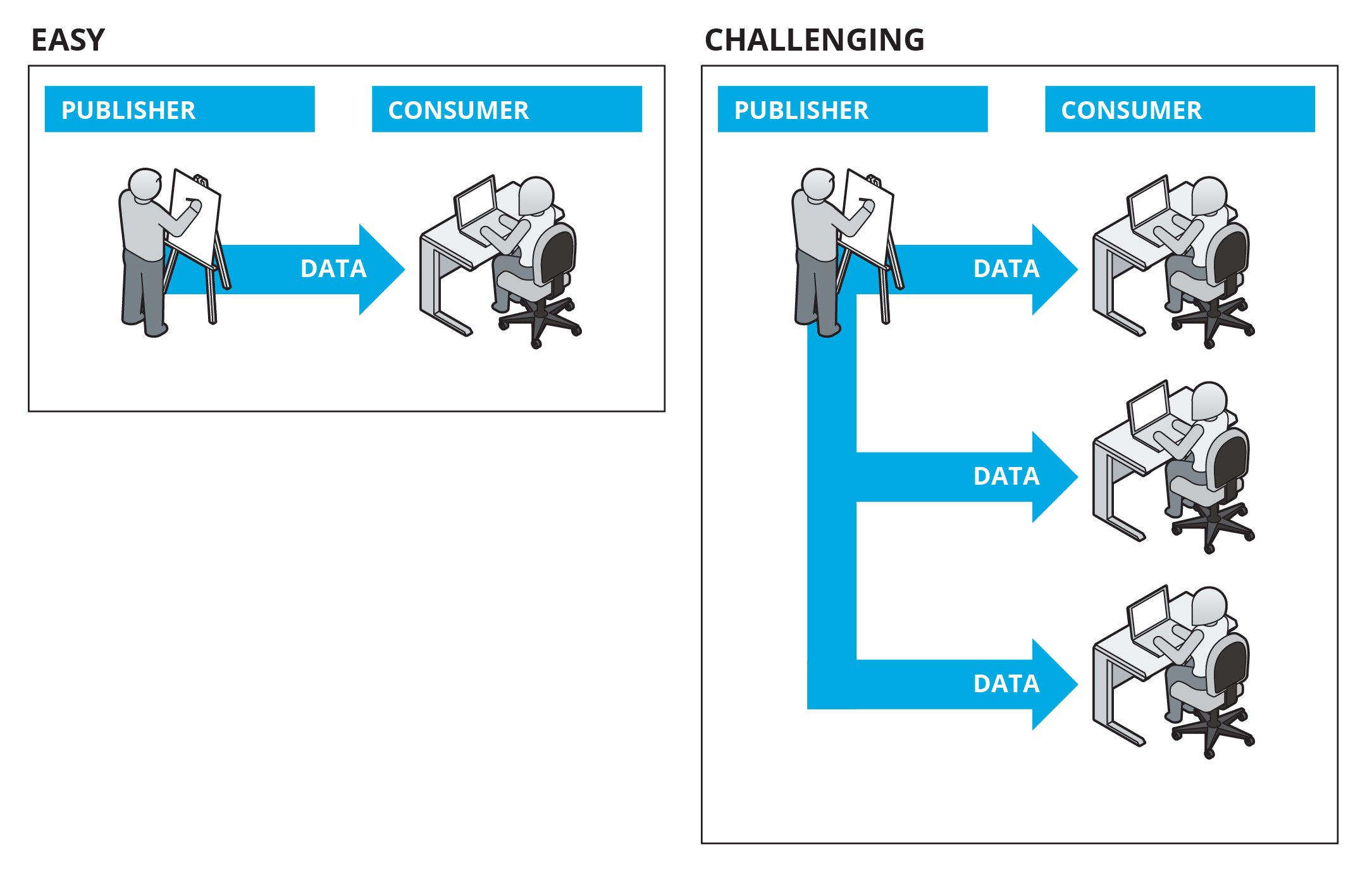
In the case where there is just a single Publisher and a single Consumer, things are easy to manage. There is a single value chain. The data set may need to be re-formatted, cleaned, or enriched, but usually the Publisher and Consumer can agree about how to split the costs associated with using the data set.
On the other hand, when there are multiple Consumers, each with different needs from the data set, the problem becomes more challenging. We have the potential for duplication of effort by Consumers, for example if each Consumer must remove duplicate records in the data set. Alternatively, the Publisher may negotiate separate agreements with each Consumer to deliver a customized version of the data or a different API, which duplicates the work of the Publisher. These costs incurred from duplication of effort will reduce the value we produce from using the data. To minimize these costs, we need to take a broader perspective.
4. Governance constrains the data Publisher to help the data Consumers
Governance assigns responsibilities and limits freedom. In this case, we constrain the Publisher to deliver the data set in a way that is best for all Consumers. We do this by analyzing the value chain through all of the Consumers, and allocate responsibilities (and hence, costs) between the Publisher and Consumers to maximize the total value produced by all uses of the data set.
Governance manifests in an organization's Enterprise Architecture as standards, patterns, and policies, and is reviewed as part of the organization's software engineering process--for example, at phase gate reviews.
Governance needs authority--making rules that nobody follows incurs only costs, with no offsetting benefits, and hence produces negative value.
Constraining the Publisher may reduce the Publisher's costs, for example, by reducing the types of interfaces, restricting backward compatibility requirements for an interface, or restricting technology options. However, the constraints usually increase the Publisher's costs, for example, by requiring a schema transformation, increased data quality, or higher availability. These improvements help Consumers reduce their cost to use the data. The improvements also reduce duplication of work across all Consumers, thereby increasing total value.
5. Apply governance only when it increases value (benefits > costs)
We don't need to govern every data set in the enterprise. In fact, if the enterprise has mostly one-to-one exchanges between a single Publisher and single Consumer, then investing in data governance may not be worthwhile because the costs will outweigh any benefits.
6. Focus your governance on the things that data Consumers want
Governance constrains the Publisher. We should tailor those constraints for each data set. One data set may warrant significant investment in improving data quality, while another data set may simply need to be stored on a Hadoop cluster.
To focus on what data Consumers want, we have created a five-part Data Consumer Concerns framework to categorize their concerns. The framework categories provide a checklist, and for each category, we provide some typical questions that a data Consumer would need to answer to effectively use a data set.
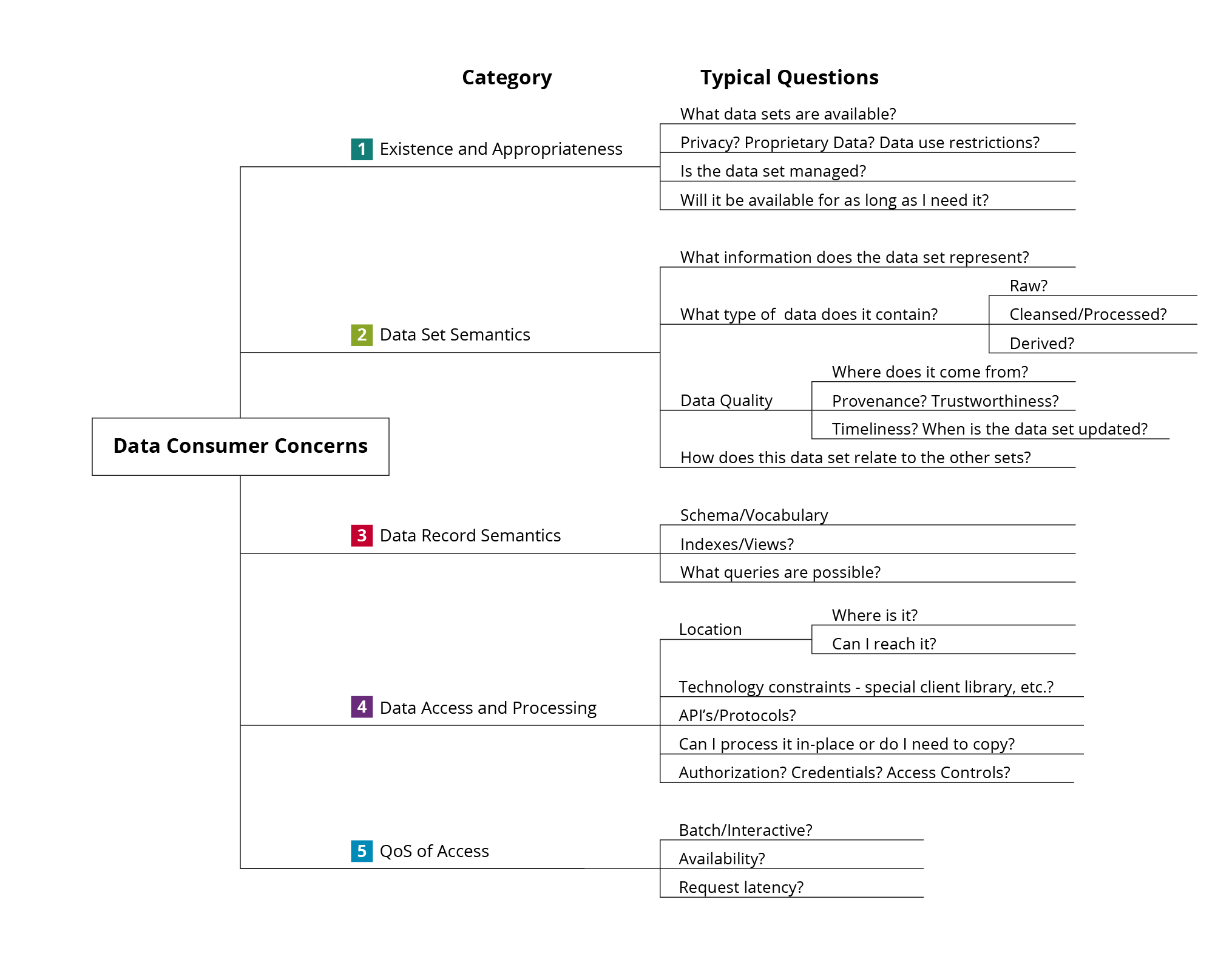
First, Consumers need to know what data are available, and whether that data set is appropriate for their use:
- Are there restrictions on data use?
- Will the data set be available for as long as they need it? The data set needs to pass these tests before moving to the next category.
The second category (Data Set Semantics) addresses concerns about the meaning of the complete data set:
- What information does it represent?
- Where did it come from?
- Does it depend on or complement other data sets.
The third category focuses on the meaning and structure of each record in the data set.
The fourth category covers concerns about accessing the data set, such as is it reachable, what are the interface protocols and APIs, and how is access controlled.
Finally, Consumers are concerned about quality of service. The data sets that they use must be delivered with availability and performance that is consistent with the requirements for the applications that they are building.
An enterprise data catalog is a mechanism to capture and communicate this information about data sets within the enterprise. The data catalog is a repository that contains information about the data sets (i.e., metadata) that are available in the enterprise. There are commercial products that implement metadata catalogs; however the initial version of the catalog could be implemented using any lightweight technology that supports searching or sorting, such as a wiki, SharePoint site, or even a shared spreadsheet. If you start with a lightweight implementation, you can decide what features and scale you need, and migrate to a commercial product if needed.
We recommend that you take an agile approach to building your catalog - think "minimum viable product." Start with Existence and Appropriateness attributes, and add others that may relevant and useful. For each, balance benefit against cost.
A Playbook for Data Governance
We combine the six principles discussed above to create a playbook for lightweight data governance:
Step 1: Identify your high-benefit decisions. These decisions might be infrequent but high impact, high frequency but low impact, or something in between.
Step 2: Identify the data sets that support your highest-benefit decisions.
Step 3: For each of those data sets, identify the producer-consumer relationship. If it is one-to-one relationship, then little or no governance may be needed. If it is one-to-many or many-to-many, then governance may increase value.
Step 4: What constraints should you impose on the Producer? How will data Consumers need to adapt? Use the Data Consumer Concerns framework described above to identify possible governance actions. At each point, balance cost and benefit to keep value positive.
Step 5: Repeat Steps 2, 3, and 4 for each high-benefit decision identified in Step 1.
Step 6: Periodically review your list of high-benefit decisions for changes, and introduce or remove governance constraints using data set value to guide decision making.
Wrapping Up
The incremental, value-driven approach to data governance covered in this blog posting allows organizations to minimize disruption and friction that inhibit attempts to share data sets within an enterprise. Broad adoption of best practices will eventually be beneficial, but the approach discussed here can help you take the first steps.
I welcome your feedback in the comments section below.
Additional Resources
View my presentation 6 Things You Need to Know About Data Governance that was delivered at the 2017 Software Solutions Symposium.
Written By

More By The Author
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed