Scope vs. Frequency in Defining a Minimum Viable Capability Roadmap: Part 2 of 3

As Soon as Possible
In the first post in this series, I introduced the concept of the Minimum Viable Capability (MVC). While the intent of the Minimum Viable Product (MVP) strategy is to focus on rapidly developing and validating only essential product features, MVC adapts this strategy to systems that are too large, too complex, or too critical for MVP.
MVC is a scalable approach to validating a system of capabilities, each at the earliest possible time. Capability scope is limited (minimum) so that it may be produced as soon as possible. For MVP, as soon as possible is often a just a few weeks. But what does as soon as possible mean for an MVC? This post explores how technical dependencies and testability determine that, and what this implies for a system roadmap. Let's start with the pattern of MVC activities to produce a major release.
The MVC Release Pattern
Cyber-physical systems can comprise hundreds or thousands of distinct capabilities. Typically a capability is achieved by integrating software items (SI), hardware items (HI), and other capabilities. Each capability depends on the presence of these components or at least a proxy sufficient for testing. Eventually, MVCs will become full capabilities (FCs). Taking all this into consideration, laying out a feasible and effective CPS roadmap is an enduring puzzle. The following steps sketch how the MVC strategy can solve this puzzle. MVC relies on Agile practices, so the overall plan is fluid, but sprint backlogs are not. The following order is typical, but should be adapted as needed:
- Just enough system architecture. Establish and articulate a just enough system architecture to support near-term planning, development, and testing. Make educated guesses if necessary. The architecture model should be a living representation with updates included in the sprint definition of done.
- Know your dependencies. Analyze the architecture to identify technical dependencies, then produce a technical dependency graph, which can be done with many project management tools or using a topological sort, such as tsort, if you prefer command-line apps. Keep the dependency and architecture models current.The figure below shows technical dependencies for a notional system. SIs are yellow, HIs are blue, and MVCs are green. Test items are orange and falsework is light blue (more about falsework later.) An incoming arrow shows that an item depends on the source of that arrow. For example, both SI1 and TI1 must be done before MVC1 can be released for evaluation.
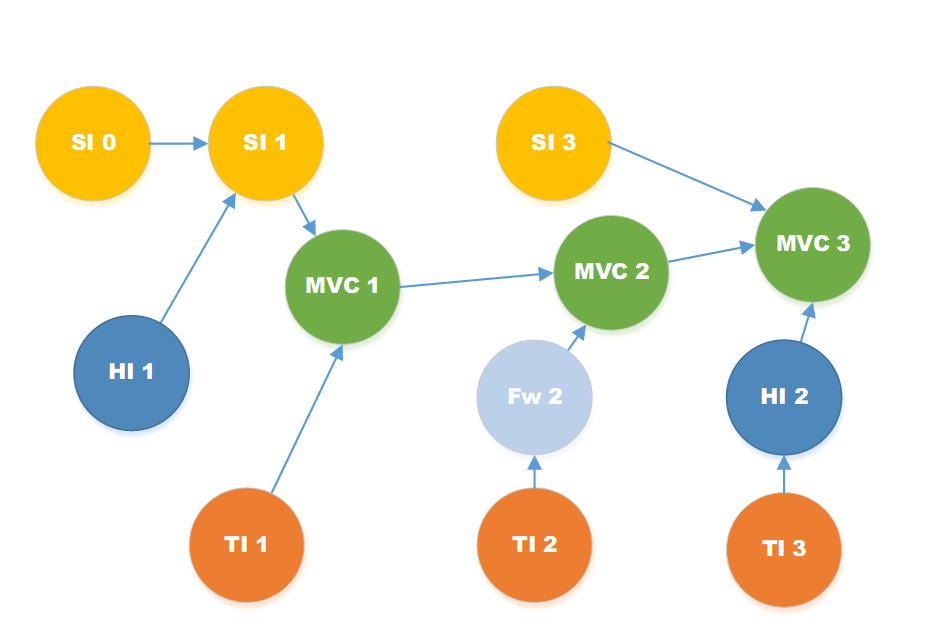
3. Define the point releases. Identify MVC sets that support coherent use of the system, such as all or part of a mission thread, interoperation with a key external system, or risk reduction. Use this information as a working release roadmap.
4. Define sprints around dependencies. Allocate Layout groups of two- to four-week sprints as a point release plan. Allocate SI, HI, TI, and MVCs to each sprint's backlog following the precedence order. Adjust either the point release goals or backlog as needed.
5. Develop tests that evaluate each MVC. While MVP apps often use the default architecture of their cloud providers and glean customer validation feedback for free, cyber-physical system sponsors typically must invest heavily to establish architecture and validation technology. An MVC backlog must include tasks to define test assets that validate the new MVCs, maintain a growing regression testing suite, run its test suites, and correct any revealed bugs.
6. Resolve dependency conflicts with Falsework. Falsework is a term borrowed from the construction industry where it refers to scaffolding and temporary support necessary to build bridges. Automated software testing falsework includes all kinds of temporary stand-ins for system under test software items, including nulls, mocks, stubs, fakes, service virtualization, simulation, emulation, and hard-real time emulation (hardware in the loop). Dependency conflicts arise when an MVC depends on an item that cannot be available a soon as you need it. Use a piece of falsework as a stand-in until the other item can be integrated.
7. Define major releases. The capabilities of a major release are defined by requirements, contracts, and operational considerations. A major release (sometimes a "block") may require user re-training or upgrades to existing equipment. The release plan should include TIs and falsework that provide sufficient evidence that all MVCs and FCs in the release meet or exceed threshold requirements.
8. Keep the cadence. Sprint regularity and backlog management is key enabler of effective planning and coordination among a team of teams. Sprints should be either two or four weeks and always the same duration. Bearing in mind that "Your mileage may vary." Here are some guidelines for other significant activities.
- Four- to-six weeks is often sufficient for a just-enough architecture.
- With component dependencies in hand, allow another two- to-four weeks to develop the roadmap for the next major release.
- A point release should be produced every two- to-four months.
- A major release should be produced in 12- to-18 months.
MVC, Architecture, and Testability
Point releases of MVCs may not be acceptable for full production use or field trials, in contrast to MVPs that are released as soon as possible to get rapid feedback. Realistic, automated, and sufficient testing of MVCs and system point releases is essential to provide rapid feedback.
Sufficient testing requires testable MVCs. While capabilities are typically defined with quantitative and behavioral requirements, they must also be controllable and observable, i.e., testable. Control and observation are typically achieved by a separate testing system. The effectiveness of the testing system is limited to the testability of the system under test. To be controllable, capabilities must be independently invokable, have working interfaces that support automated testing, and allow configuration to evaluate their full behavioral range. To be observable, a capability's behavior and/or output level must be practically and reliably recordable for evaluation.
As a result, testability is a driver for architecture and MVC definition. System architecture cannot therefore simply be an inventory of hardware items, software items, and their physical interfaces. It must define which of these elements is needed to support a capability and which capabilities depend on others. Sequence diagrams are one simple representation that can often provide this.
Why This Works
MVC addresses critical questions for cyber-physical systems with a large installed base or where customer acceptance is only one of many required measures of effectiveness. To see why that is, let's consider the full spectrum of release frequency and scope. The figure below shows how risk and efficiency change as a function of release frequency and scope. More red equals more risk or waste, yellow possibly acceptable risks, and green indicates a feasible trade of scope and frequency.
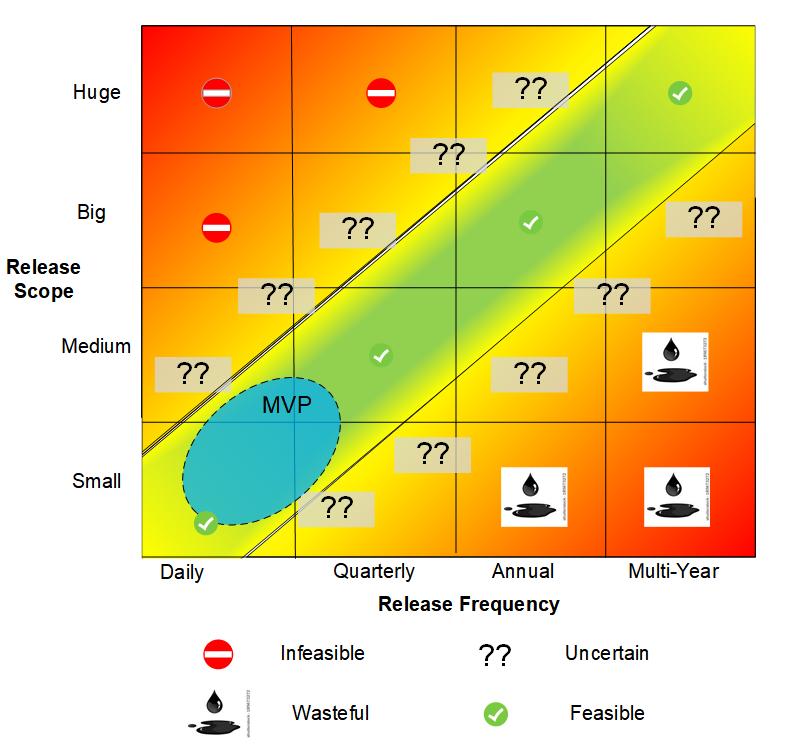
- Scope (vertical axis): the net change in system function points, including collateral and deployment support.
- Frequency (horizontal axis): the average time between releases.
- The northwest corner is infeasible--Rome was not built in a day.
- The southwest corner indicates waste--small systems should not take years.
- The boundary of feasibility is not fixed--it may be worthwhile to trade scope and frequency on the margin.
This notional chart illustrates the MVC concept and does not represent any particular system. It is worth repeating that scope is the net change, not the absolute size of a system.
The infeasible region (northwest corner) represents combinations of large scope and high frequency that are substantially more risky. The wasteful region (southeast corner) represents combinations of smaller scope and low frequency resulting in slack time between releases that probably could be put to better use, perhaps by increasing frequency.
In contrast, MVP focuses on high frequency cycles for small scope products or feature set increments, indicated with the blue oval.
Scope versus Frequency: Long-term Planning Versus Rapid Delivery
For most large systems, a release roadmap does not focus on a single scope or release frequency. Their roadmaps often include multiple releases of different scope, each consisting of carefully selected capability sets matched to a feasible frequency. Microsoft Windows is one example of this. The Windows operating system is a truly a huge system, but is released on several frequencies and scopes.
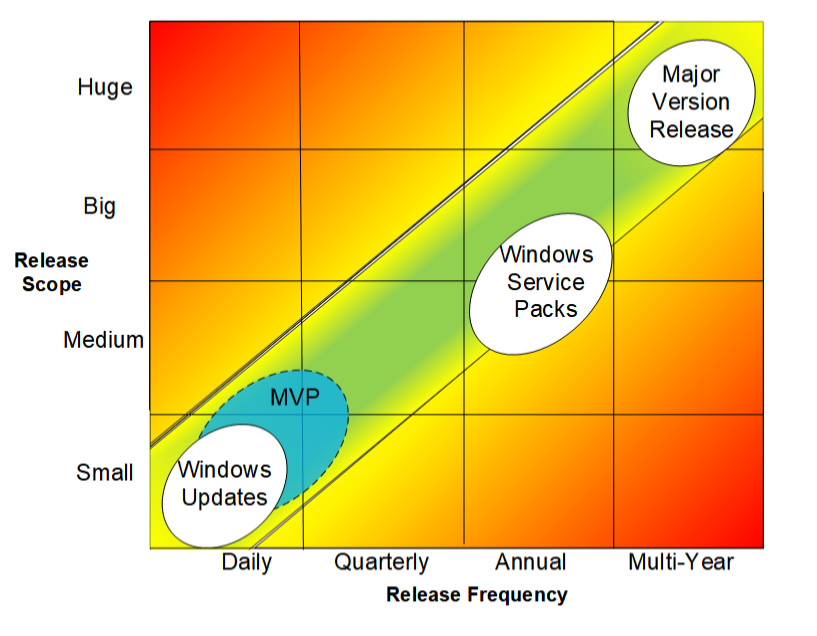
- First, a stream of weekly and sometimes daily updates is broadcast to all Windows users for a self-service update. The capability scope of these updates tends to be small, often to correct a single vulnerability.
- Second, for Windows and other Office products, a service pack update provides a cumulative update, bug fixes, and new features that typically improve interoperation without changing behaviors or a look and feel that has become familiar to users.
- Third, about every three- to five-years, a new major version is released, most recently Windows 10. Mapping these well-known patterns onto the frequency-scope matrix shows that Microsoft's releases can be characterized as a staged MVC approach with capability size and frequency that falls within the feasible region. See the figure above.
The Windows case is an extreme example since it is a very large and complex collection of software products. As noted above, a major release cadence of 12- to-18 months is preferable and feasible for many applications. Note that the pre-release development effort of a capability, even at the southwest corner of the chart, can be considerably longer than the span between releases.
Wrapping Up and Looking Ahead
The third and final post in this series, How to deliver a Minimum Viable Capability Roadmap, will argue that the MVC strategy relies on a well-formed and testable architecture with early validation, just as for MVP. As result, a capability-driven architecture model can guide a just-enough implementation and support realistic evaluation of point and major releases.
Additional Resources
View my keynote, Testability: Factors and Strategy, which was presented at the 2010 Google Test Automation Conference.
Read the article Impact of Budget and Schedule Pressure on Software Development Cycle Time and Effort by Ning Nan and Donald E. Harter, which was published in the Sept.-Oct. 2009 IEEE Transactions on Software Engineering.
Read the article Wavefront: a goal-driven requirements process model by Mary Frances Theofanosa and Shari Lawrence Pfleeger, which was published in Information and Software Technology Volume 38, Issue 8, 1996.
Written By

Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed