Mothra: Network Situational Awareness at Scale

In the last two decades, network traffic has increased more than 100-fold. Consequently, detecting today’s most concerning cyber attacks, such as phishing, drive-by downloads, and ransomware, from that enormous stream of traffic has become much harder. In essence, network situational awareness and security have become big-data problems, especially on large networks.
For years, security analysis on large networks has relied on the use of network traffic flow data, such as Cisco’s NetFlow. Netflow was designed to sample and retain the most important attributes of network conversations between TCP/IP endpoints on large networks without having to collect, store, and analyze all network data. The SEI released its tool for analyzing network flow records, SiLK (System for Internet-Level Knowledge), 18 years ago. However, the rising volume of network traffic, and hence the volume of related flow data, has outgrown SiLK’s capacity. To close this gap, the SEI released Mothra earlier this year.
This SEI Blog post will introduce you to Mothra and summarize our recent research on improvements to Mothra designed to handle large-scale environments. This post also describes research aimed at demonstrating Mothra’s effectiveness at “cloud scale” in the Amazon Web Services (AWS) GovCloud environment.
Managing the Flood of Network Flow Data
As overall network traffic has grown, network flow records, such as Cisco NetFlow, have also grown. Detecting the most serious network attacks requires deep packet inspection (DPI) on these network flows. The DPI process inspects the data traversing a computer network and can alert, block, re-route, or log this data as required. However, while DPI extracts more information on a flow’s security-critical components, it also generates a record at least five times bigger than a non-DPI flow record.
The SEI tool Yet Another Flowmeter (YAF) can perform DPI, among other capabilities. YAF is the data collection component of the SEI’s CERT NetSA Security Suite. It transforms packets into network flows and exports the flows to Internet Protocol Flow Information Export (IPFIX) collecting processes or an IPFIX-based file format for processing by downstream tools, in particular the SEI’s SiLK tool. SiLK, however, was not designed to analyze DPI data nor process the volume of flow data generated by organizations at the scale of Internet service providers.
We sensed we had a big-data problem on our hands, and in 2017 a government sponsor asked the SEI to make YAF work with a big-data analysis tool. In response, we created the Mothra analysis platform to enable scalable analytical workflows that extend beyond the limitations of conventional flow records and the ability of our existing tools to process them. Mothra is a collection of open-source libraries for working with network flow data (such as Cisco’s Netflow) in the Apache Spark large-scale data analytics engine.
Mothra bridges the previously stand-alone tools of the CERT Network Situational Awareness (NetSA) Security Suite and Spark. Other security solutions, such as antivirus applications or intrusion detection and prevention systems, can also export data to Spark. Mothra enables analysts to access network flow data alongside these other sources, all within a common big-data analysis environment. With all these data sources available for analysis, organizations with very large networks can achieve more comprehensive network situational awareness.
Like the SEI’s pre-existing analysis tool, SiLK Mothra was designed to analyze network flow records, specifically those produced by the SEI’s YAF (Yet Another Flowmeter) tool. Mothra transforms YAF output into a format readable by Apache Spark, and the Mothra platform and also
- facilitates bulk storage and analysis of cybersecurity data with high levels of flexibility, performance, and interoperability
- reduces the engineering effort involved in developing, transitioning, and operationalizing new analytics
- serves all major constituencies within the network security community, including data scientists, first-tier incident responders, system administrators, and hobbyists
Mothra directly processes the binary IPFIX format, a standard of the Internet Engineering Task Force (IETF). Analysts can efficiently pull out just the pieces they want, and they can then use the Spark analysis engine on the IPFIX data. Mothra lets you simply drop the data right in without having think ahead about how to transform it. These transformations change the collected data as little as possible, preserving it for future analysis.
Analysts can use Mothra to bring the programming power of Spark to bear on network flow data from the NetSA Security Suite. SiLK’s filters allow limited queries on pure flow datasets. Mothra and Spark enable much deeper, flexible queries over DPI-enriched flow to find much more data of interest. For example, analysts can now pull any kind of data they can express as a program and can perform iterative pulls in which the data pulled changes across the iterations. They can also pull data that consists of packets bigger than the average number of packets within the matching set of criteria. Something that would take you a lot of scripting in SiLK can now be condensed down to a half page of code.
Analysis of all that flow data requires plenty of storage and programming expertise. Mothra enables organizations with the infrastructure and personnel to support Apache Spark, use their expertise, and apply DPI analytics to network flow data. This insight can help them evaluate their current defenses and discover security gaps, especially on infrastructure-level enterprise networks.
Prototyping Mothra at Cloud Scale
Having developed Mothra and shown it to be useful in on-premises network environments, we next set our sights on answering the following questions:
- Can Mothra be deployed in a cloud environment?
- Can a cloud-based deployment work as effectively as Mothra does in an on-premises environment?
- How can cloud deployment be best accomplished to optimize Mothra’s performance?
To answer these questions, we researched methods for deploying Mothra and its related system components in the AWS GovCloud environment. Our project involved multiple teams that collaborated to address code development, system engineering, and testing. We built prototypes of increasing capability that progressed toward target system performance. These prototypes ingested billions of flow records per day with appropriate content distributed through the data and made that data available for analysis in an acceptable amount of time.
Figure 1 depicts one of the prototypes we developed, which deployed Mothra to Amazon Elastic Map Reduce (EMR) running Spark and backed by the EMR File System (EMRFS) with storage in Amazon S3. EMRFS is an implementation of the Hadoop Distributed File System (HDFS) that all Amazon EMR clusters use for reading and writing regular files from EMR directly to S3. EMRFS provides the convenience of storing persistent data in S3 for use with Hadoop while also providing features like consistent viewing, data encryption, and elasticity.
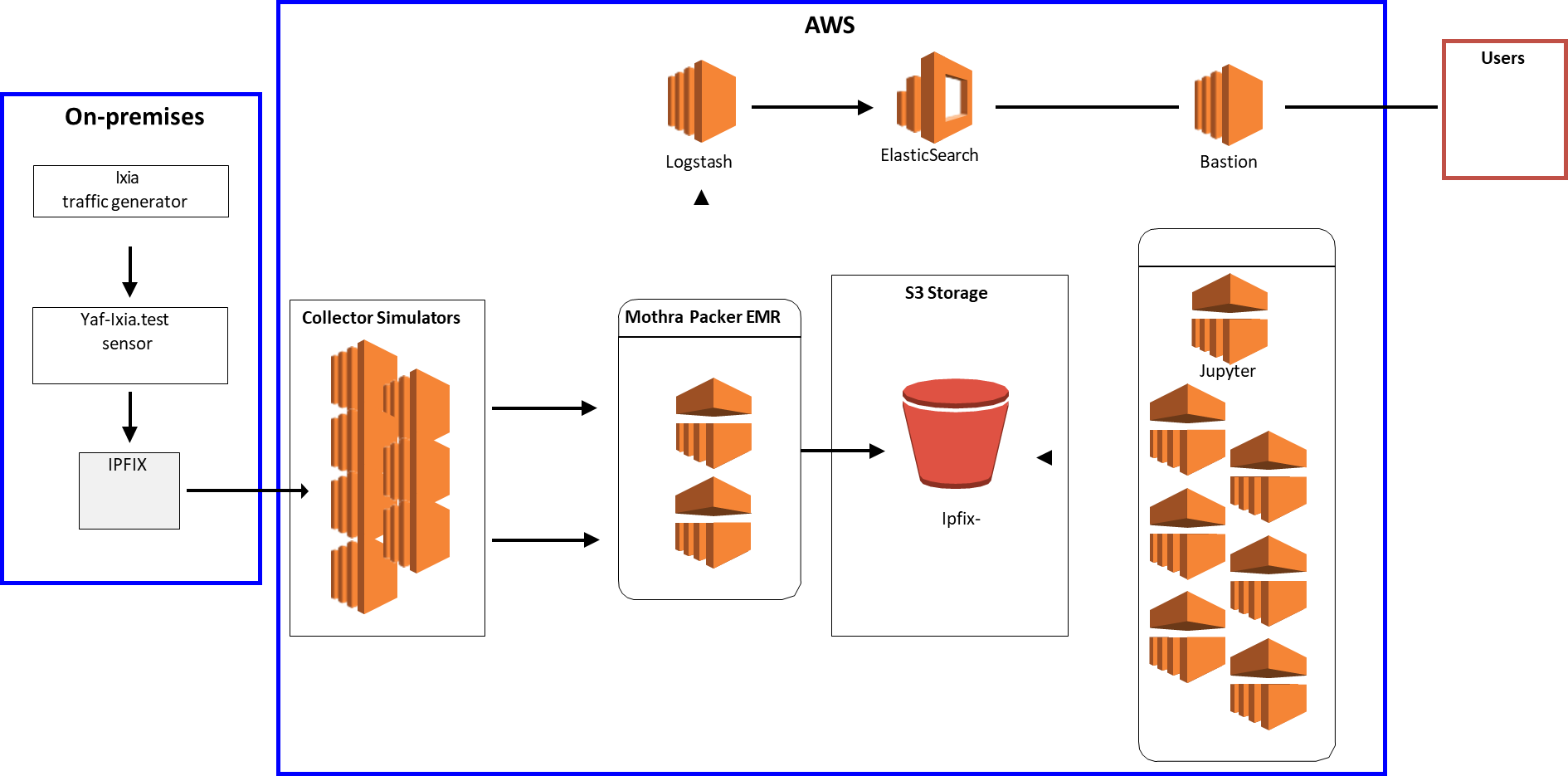
In conducting our research, we quickly determined that Mothra could be easily installed and operated at speeds that clearly met user needs when deployed in the cloud. Query performance in the cloud environment, however, was suboptimal. To tackle that problem, we undertook the following work:
- implemented multiple system designs in the SEI’s hybrid prototyping environment (in particular, we used our Ixia traffic generator to create a synthetic data stream that resulted in a sizable data repository within AWS)
- modified configurations as test results are examined to address observed problems
- developed simulators to produce flow volumes that match those observed on production systems
- executed test plans to evaluate the data ingest process and representative query operations
- developed new code to optimize data read operations
- tuned system services (e.g., Spark)
Our work confirmed that Mothra could successfully integrate with AWS GovCloud and led us to produce a set of levers that can be used for tuning system services to specific data characteristics. Those levers include file-read parameters and desired file size, which are stored in a system repository. To determine the optimal settings for operating in the AWS GovCloud environment systematically, we generated multiple Mothra repositories with different file scenarios and executed a series of tests using a range of parameter settings.
Additional Resources
To learn more about our research on employing Mothra in large-scale cloud environments, we encourage you to read our technical report Experiences with Deploying Mothra in Amazon Web Services (AWS). The report provides greater detail on the work summarized in this post and also provides a complete description of the system tested, our testing process, our results, and example analyst scenarios.
We also invite you to try Mothra, which is free for download from the SEI Network Situational Security Suite site. The site also provides directions for downloading and integrating Mothra from the Maven public repository site.
Finally, if you’ve used Mothra, we’d love to hear about your experiences installing, deploying, and using it. Contact us at netsa-help@cert.org.
Written By

More By The Author
More In Cloud Computing
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cloud Computing
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed