Modeling Malware with Suffix Trees

PUBLISHED IN
Reverse Engineering for Malware AnalysisThrough our work in cyber security, we have amassed millions of pieces of malicious software in a large malware database called the CERT Artifact Catalog. Analyzing this code manually for potential similarities and to identify malware provenance is a painstaking process. This blog post follows up our earlier post to explore how to create effective and efficient tools that analysis can use to identify malware.
At the heart of our approach are longest common substring (LCS) measures, which describe the amount of shared code in malware. In this post we explain how to create measures for similarity studies on malware via a suffix tree, which is a data structure that encodes an entire map of shared substrings in a malware corpus, such as the CERT Artifact Catalog. We characterize the performance characteristics of suffix trees and quantify their dependence on memory and input size. We also demonstrate the efficient construction of suffix trees for large malware data sets involving thousands of files. In addition, we compare LCS measures to the laborious and time intensive process of manually creating signatures (which are regular expressions applied to the binary thought to be both specific and indicative for malware.
Building the Suffix Tree
By building a suffix tree data structure for the CERT Artifact Catalog we can form a better representation of the malware corpus for studies of malware involving string query, shared string usage, and string similarity. Having uncharacterized data is like being in unexplored, unmapped territory. A suffix tree allows analysts to explore and map the malware landscape. Shared code becomes the topographical features of the mapped landscape. As travelers use a map and the landscape features to reason about where they are and where they want to go, so do malware analysts study the large shared substrings of the suffix tree to reason about what areas to focus on. For example, multiple malware pieces from the Zeus malware family have code in common and provide a means to explore and analyze the entire family of malware.
A suffix tree can be built in time linear to the size of the input, allowing us to identify any long common substrings in linear time. We augmented the conventional suffix tree data structure and algorithm to include queries based on subsets of files and measures of information (such as Shannon-entropy) on shared strings. To scale our suffix tree data structure to large data sets we also developed external algorithms that operate efficiently beyond the capacity of main memory in a single computer.
Using the Suffix Tree to Create an LCS Measure for Similarity Studies on Malware
After constructing the suffix tree, we used it to analyze different families of malware, including the Poison Ivy malware family that installs a remote access tool onto an exploited machine. Poison Ivy files were collected by CERT from 2005 to 2008. Although this family of malware is no longer thought to be in active development, analysts have examined it extensively. We used Poison Ivy files as a test set to validate findings from our data structures. For example, we applied clustering based on LCS and compared it to a "ground truth" of known subgroups within the Poison Ivy family.
Our suffix tree data structure enabled us to identify several LCSs that were common to many files in the Poison Ivy family. By quickly filtering out strings of low entropy, we were left with meaningful coding sequences from which we can determine sequences that are characteristic of the malicious software family.
Validating the Measure
After analyzing the code using the suffix trees, we compared our results against signatures that were developed over the course of several years of extensive examination by analysts. We used suffix trees to identify several critical substrings that matched identically across multiple files, exceeded a certain length, and had satisfactory information content. These landmark substrings were then used to create a feature-vector for each file; these feature-vectors were used to cluster the files into subgroups. We then created dendrograms that suggested relationships among the files based on co-location of long common substrings, as shown in the following diagram.
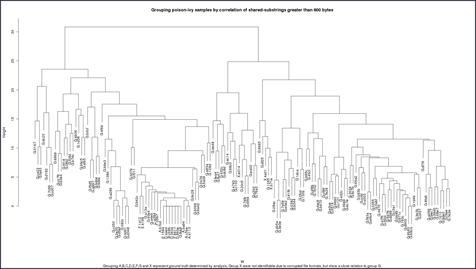
To validate the clusters, we revisited the Poison Ivy files and used the signatures that had been developed by analysts to identify versions in the software. Our evaluation showed that the LCS clustering produced groupings consistent with signatures that were developed by analysts, in many cases exposing additional sub-groups that we were unaware of. Moreover, the LCS clustering can group corrupted files and identify potential incorrect attributions.
Results of our Research
We used suffix trees to analyze approximately 200 to 1,000 files in about four hours and identify additional details on the structure of the family that analysts could not access via manual inspection alone. Unfortunately, people often view automated methods as a means to replace human analysis. The goal of our research, however, is to use suffix trees to create a more effective use of computing to bear against the problems of identifying malware from clean-ware. For example, malware may have components that resemble more than one family. Our new tool may allow us to identify those components of malware, as well those that set off a command-control interface or an element that may install a remote access tool.
Future Work
In the past year, our research has focused on creating the suffix tree data structures and ensuring that they can provide us with useful information about malware families. Our next steps are to scale the data structures to larger data sets and optimize them to allow for even larger input size. We are currently able to generate approximately 8,000 files into a data structure. Ideally, we would like to optimize the data structures and algorithms (exploiting parallelism) to include between 80,000 to 100,000 files, the size of which can exceed the main memory of a single computer.
Additional Resources
For further reading about CERT Program work in malware or malicious code research, click on the SEI Blog links below:
A New Approach to Modeling Malware Using Sparse Representation
Using Machine Learning to Detect Malware Similarity
Fuzzy Hashing Techniques in Applied Malware Analysis
Learning a Portfolio-Based Checker for Provenance-Similarity of Binaries
More information about CERT research and development is available in the 2010 CERT Research Report, which may be viewed online at
www.cert.org/research/2010research-report.pdf
Written By

More By The Author
More In Reverse Engineering for Malware Analysis
PUBLISHED IN
Reverse Engineering for Malware AnalysisGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Reverse Engineering for Malware Analysis
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed