How Can Causal Learning Help to Control Costs?

The inaccuracy and excessive optimism of cost estimates are often cited as dominant factors in DoD cost overruns. Causal learning can be used to identify specific causal factors that are most responsible for escalating costs. To contain costs, it is essential to understand the factors that drive costs and which ones can be controlled. Although we may understand the relationships between certain factors, we do not yet separate the causal influences from non-causal statistical correlations.
Causal models should be superior to traditional statistical models for cost estimation: By identifying true causal factors as opposed to statistical correlations, cost models should be more applicable in new contexts where the correlations might no longer hold. More importantly, proactive control of project and task outcomes can be achieved by directly intervening on the causes of these outcomes. Until the development of computationally efficient causal-discovery algorithms, we did not have a way to obtain or validate causal models from primarily observational data—randomized control trials in systems and software engineering research are so impractical that they are nearly impossible.
In this blog post, I describe the SEI Software Cost Prediction and Control (abbreviated as SCOPE) project, where we apply causal-modeling algorithms and tools to a large volume of project data to identify, measure, and test causality. The post builds on research undertaken with Bill Nichols and Anandi Hira at the SEI, and my former colleagues David Zubrow, Robert Stoddard, and Sarah Sheard. We sought to identify some causes of project outcomes, such as cost and schedule overruns, so that the cost of acquiring and operating software-reliant systems and their growing capability is predictable and controllable.
We are developing causal models, including structural equation models (SEMs), that provide a basis for
- calculating the effort, schedule, and quality results of software projects under different scenarios (e.g., Waterfall versus Agile)
- estimating the results of interventions applied to a project in response to a change in requirements (e.g., a change in mission) or to help bring the project back on track toward achieving cost, schedule, and technical requirements.
An immediate benefit of our work is the identification of causal factors that provide a basis for controlling program costs. A longer term benefit is the ability to use causal models to negotiate software contracts, design policy, and incentives, and inform could-/should-cost and affordability efforts.
Why Causal Learning?
To systematically reduce costs, we generally must identify and consider the multiple causes of an outcome and carefully relate them to each other. A strong correlation between a factor X and cost may stem largely from a common cause of both X and cost. If we fail to observe and adjust for that common cause, we may incorrectly attribute X as a significant cause of cost and expend energy (and costs), fruitlessly intervening on X expecting cost to improve.
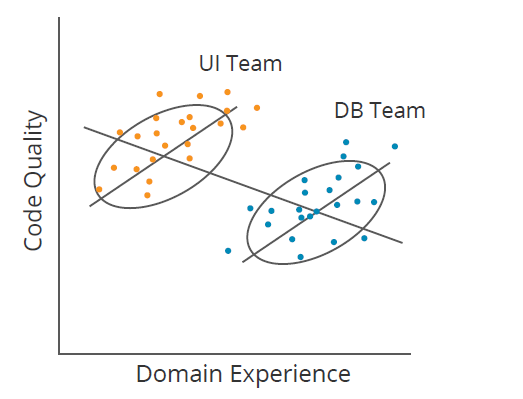
Another challenge to correlations is illustrated by Simpson’s Paradox. For example, in Figure 1 below, if a program manager did not segment data by team (User Interface [UI] and Database [DB]), they might conclude that increasing domain experience reduces code quality (downward line); however, within each team, the opposite is true (two upward lines). Causal learning identifies when factors like team membership explain away (or mediate) correlations. It works for much more complicated datasets too.
Causal learning is a form of machine learning that focuses on causal inference. Machine learning produces a model that can be used for prediction from a dataset. Causal learning differs from machine learning in its focus on modeling the data-generation process. It answers questions such as
- How did the data come to be the way it is?
- What data is driving which outcomes?
Of particular interest in causal learning is the distinction between conditional dependence and conditional independence. For example, if I know what the temperature is outside, I can find that the number of shark attacks and ice cream sales are independent of each other (conditional independence). If I know that a car won’t start, I can find that the condition of the gas tank and battery are dependent on each other (conditional dependence) because if I know one of these is fine, the other is not likely to be fine.
Systems and software engineering researchers and practitioners who seek to optimize practice often espouse theories about how best to conduct system and software development and sustainment. Causal learning can help test the validity of such theories. Our work seeks to assess the empirical foundation for heuristics and rules of thumb used in managing programs, planning programs, and estimating costs.
Much prior work has focused on using regression analysis and other techniques. However, regression does not distinguish between causality and correlation, so acting on the results of a regression analysis could fail to influence outcomes in the desired way. By deriving usable knowledge from observational data, we generate actionable information and apply it to provide a higher level of confidence that interventions or corrective actions will achieve desired outcomes.
The following examples from our research highlight the importance and challenge of identifying genuine causal factors to explain phenomena.
Contrary and Surprising Results


Figure 2 shows a dataset developed by Sarah Sheard that comprised approximately 40 measures of complexity (factors), seeking to identify what types of complexity drive success versus failure in DoD programs (only those factors found to be causally ancestral to program success are shown). Although many different types of complexity affect program success, the only consistent driver of success or failure that we repeatedly found is cognitive fog, which involves the loss of intellectual functions, such as thinking, remembering, and reasoning, with sufficient severity to interfere with daily functioning.
Cognitive fog is a state that teams frequently experience when having to persistently deal with conflicting data or complicated situations. Stakeholder relationships, the nature of stakeholder involvement, and stakeholder conflict all affect cognitive fog: The relationship is one of direct causality (relative to the factors included in the dataset), represented in Figure 2 by edges with arrowheads. This relationship means that if all other factors are fixed—and we change only the amount of stakeholder involvement or conflict—the amount of cognitive fog changes (and not the other way around).
Sheard’s work identified what types of program complexity drive or impede program success. The eight factors in the top horizontal segment of Figure 2 are factors available at the beginning of the program. The bottom seven are factors of program success. The middle eight are factors available during program execution. Sheard found three factors in the upper or middle bands that had promise for intervention to improve program success. We applied causal discovery to the same dataset and discovered that one of Sheard’s factors, number of hard requirements, seemed to have no causal effect on program success (and thus does not appear in the figure). Cognitive fog, however, is a dominating factor. While stakeholder relationships also play a role, all those arrows go through cognitive fog. Clearly, the recommendation for a program manager based on this dataset is that sustaining healthy stakeholder relationships can ensure that programs do not descend into a state of cognitive fog.
Direct Causes of Software Cost and Schedule
Readers familiar with the Constructive Cost Model (COCOMO) or Constructive Systems Engineering Cost Model (COSYSMO) may wonder what those models would have looked like had causal learning been used in their development, while sticking with the same familiar equation structure used by these models. We recently worked with some of the researchers responsible for creating and maintaining these models [formerly, members of the late Barry Boehm's group at the University of Southern California (USC)]. We coached these researchers on how to apply causal discovery to their proprietary datasets to gain insights into what drives software costs.
From among the more than 40 factors that COCOMO and COSYSMO describe, these are the ones that we found to be direct drivers of cost and schedule:
COCOMO II effort drivers:
- size (software lines of code, SLOC)
- team cohesion
- platform volatility
- reliability
- storage constraints
- time constraints
- product complexity
- process maturity
- risk and architecture resolution
COCOMO II schedule drivers
- size (SLOC)
- platform experience
- schedule constraint
- effort
COSYSMO 3.0 effort drivers
- size
- level-of-service requirements
In an effort to recreate cost models in the style of COCOMO and COSYSMO, but based on causal relationships, we used a tool called Tetrad to derive graphs from the datasets and then instantiate a few simple mini-cost-estimation models. Tetrad is a suite of tools used by researchers to discover, parameterize, estimate, visualize, test, and predict from causal structure. We performed the following six steps to generate the mini-models, which produce plausible cost estimates in our testing:
- Disallow cost drivers to have direct causal relationships with one another. (Such independence of cost drivers is a central design principle for COCOMO and COSYSMO.)
- Instead of including each scale factor as a variable (as we do in effort
multipliers), replace them with a new variable: scale factor times LogSize. - Apply causal discovery to the revised dataset to obtain a causal graph.
- Use Tetrad model estimation to obtain parent-child edge coefficients.
- Lift the equations from the resulting graph to form the mini-model, reapplying estimation to properly determine the intercept.
- Evaluate the fit of the resulting model and its predictability.
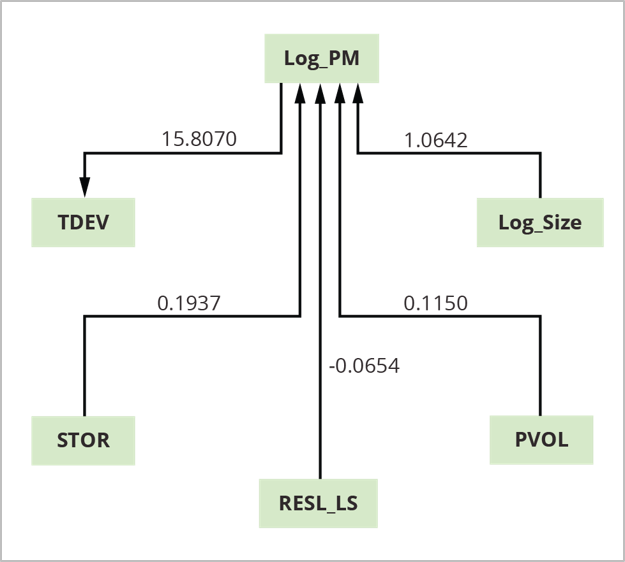
The advantage of the mini-model is that it identifies which factors, among many, are more likely to drive cost and schedule. According to this analysis using COCOMO II calibration data, four factors—log size (Log_Size), platform volatility (PVOL), risks from incomplete architecture times log size (RESL_LS), and memory storage (STOR)—are direct causes (drivers) of project effort (Log_PM). Log_PM is a driver of the time to develop (TDEV).
We performed a similar analysis of systems-engineering effort to derive a similar mini-model expressing the log of effort as a function of log size and level of service.
In summary, these results indicate that to reduce project effort, we should change one of its discovered direct causes. If we were to intervene on any other variable, the effect on effort is likely to be more modest, and could impact other desirable project outcomes (delivered capability or quality). These results are also more generalizable than results from regression, helping to identify the direct causal relationships that may persist beyond the bounds of a particular project population that was sampled.
Consensus Graph for U.S. Army Software Sustainment
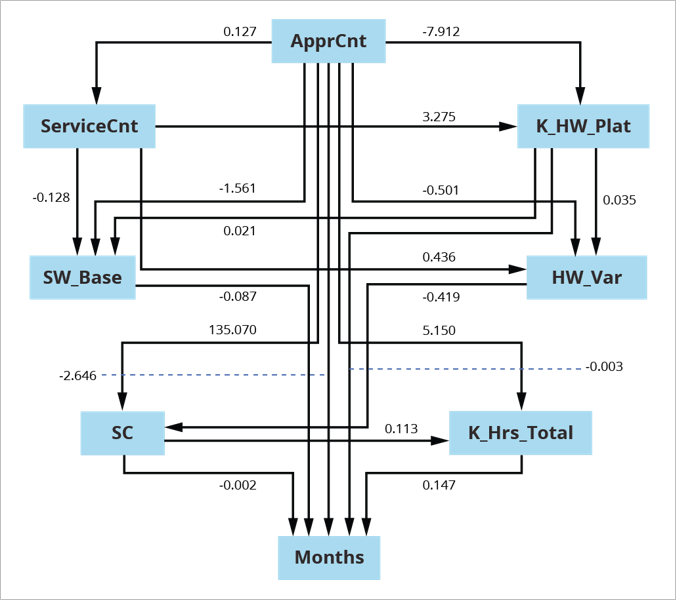
In this example, we segmented a U.S. Army sustainment dataset into [superdomain, acquisition category (ACAT) level] pairs, resulting in five sets of data to search and estimate. Segmenting in this way addressed high fan-out for common causes, which can lead to structures typical of Simpson’s Paradox. Without segmenting by [superdomain, ACAT-level] pairs, graphs are different than when we segment the data. We built the consensus graph shown in Figure 4 above from the resulting five searched and fitted models.
For consensus estimation, we pooled the data from individual searches with data that was previously excluded because of missing values. We used the resulting 337 releases to estimate the consensus graph using Mplus with Bootstrap in estimation.
This model is a direct out-of-the-box estimation, achieving good model fit on the first try.
Our Solution for Applying Causal Learning to Software Development
We are applying causal learning of the kind shown in the examples above to our datasets and those of our collaborators to establish key cause–effect relationships among project factors and outcomes. We are applying causal-discovery algorithms and data analysis to these cost-related datasets. Our approach to causal inference is principled (i.e., no cherry picking) and robust (to outliers). This approach is surprisingly useful for small samples, when the number of cases is fewer than five to ten times the number of variables.
If the datasets are proprietary, the SEI trains collaborators to perform causal searches on their own as we did with USC. The SEI then needs information only about what dataset and search parameters were used as well as the resulting causal graph.
Our overall technical approach therefore consists of four threads:
- learning about the algorithms and their different settings
- encouraging the creators of these algorithms (Carnegie Mellon Department of Philosophy) to create new algorithms for analyzing the noisy and small datasets more typical of software engineering, especially within the DoD
- continuing to work with our collaborators at the University of Southern California to gain further insights into the driving factors that affect software costs
- presenting initial results and thereby soliciting cost datasets from cost estimators all over and from the DoD in particular
Accelerating Progress in Software Engineering with Causal Learning
Knowing which factors drive specific program outcomes is essential to provide higher quality and secure software in a timely and affordable manner. Causal models offer better insight for program control than models based on correlation. They avoid the danger of measuring the wrong things and acting on the wrong signals.
Progress in software engineering can be accelerated by using causal learning; identifying deliberate courses of action, such as programmatic decisions and policy formulation; and focusing measurement on factors identified as causally related to outcomes of interest.
In coming years, we will
- investigate determinants and dimensions of quality
- quantify the strength of causal relationships (called causal estimation)
- seek replication with other datasets and continue to refine our methodology
- integrate the results into a unified set of decision-making principles
- use causal learning and other statistical analyses to produce additional artifacts to make Quantifying Uncertainty in Early Lifecycle Cost Estimation (QUELCE) workshops more effective
We are convinced that causal learning will accelerate and offer promise in software engineering research across many topics. By confirming causality or debunking conventional wisdom based on correlation, we hope to inform when stakeholders should act. We believe that often the wrong things are being measured and actions are being taken on wrong signals (i.e., mainly on the basis of perceived or actual correlation).
There is significant promise in continuing to look at quality and security outcomes. We also will add causal estimation into our mix of analytical approaches and use additional machinery to quantify these causal inferences. For this we need your help, access to data, and collaborators who will provide this data, learn this methodology, and conduct it on their own data. If you want to help, please contact us.
Additional Resources
Read the SEI blog post, How to Identify Key Causal Factors That Influence Software Costs: A Case Study, by Bill Nichols.
Read the SEI blog post, Why Does Software Cost So Much? by Robert Stoddard.
Read the SEI blog post, Quantifying Uncertainty in Early Lifecycle Cost Estimation (QUELCE): An Update, by David Zubrow
View the presentation from the International Cost Estimating & Analysis Association (ICEAA) 2021 Online Workshop, “Investigating Causal Effects of Software and Systems Engineering Effort,” by Alstad, Hira, Brown, and Konrad.
View the presentation from the Boehm Center for Systems and Software Engineering (BCSSE) COCOMO Forum, 2022 Online Forum, “Revisiting ‘Causal Effects of Software and Systems Engineering Effort’ Using New Causal Search Algorithms,” by Alstad, Hira, Konrad, and Brown.
Read other SEI blog posts about software cost estimates.
Written By

More By The Author
More In Software Engineering Research and Development
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Engineering Research and Development
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed