Detecting and Grouping Malware Using Section Hashes


PUBLISHED IN
Reverse Engineering for Malware AnalysisAnthony Perry and Addison Whitney coauthored this report.
As technology continues to develop at a rapid pace, nation states and unaffiliated individuals alike are swiftly developing new malicious computer viruses to find vulnerabilities in computer systems and achieve their political and personal objectives. To protect against these attacks, cybersecurity companies use a variety of methods to detect malware (malicious code) from entering their systems. Current malware detection systems evaluate elements in a file or evaluate the file as a whole. New research shows that other avenues for malware detection exist, specifically, by breaking up the file into sections and then comparing the resulting parts. This blog post explains how our team developed an approach that can take a collection of known malware files and use their section hashes to identify and analyze other candidate files in a malware repository.
Before describing this research, we would like to define some key terms:
- A hash is a function that converts an input to a unique output of a fixed length. This process is repeatable and will produce the same output when given the same. In addition, these functions are “one way,” meaning that it is very hard to find the input value given a hash function’s output. We primarily focused on hashing two types of information for this analysis: file hashes and section hashes.
- A file hash is the output of a hash function when given the entirety of a file. For our purposes, any two files that have the same file hash are identical.
- A section hash is the output of a hash function, where the input is a given section of a portable executable (PE), which is a standardized file format used to deliver executable files (such as .exe and .dll) for programs based on the Microsoft operating system. These files contain sections, where each section is a basic unit of code or data. For example, some common sections found within a PE file are
- .text used to store code
- .data used to store data
- .rsrc for resource
While each section is important for the program to execute properly, we are primarily interested in the relationship between files that contain identical sections, which may indicate code reuse.
Past Research in Section Hash Analysis
In 2019, Ian Shiel and Stephen O'Shaughnessy researched the potential of using section hashes as a means to identify malware. They noted that most malware is not unique, but simply a variant of an overarching malware family. In changing just a few characters in the malware source code, the file hash would be totally different, even when 99.8 percent of the remaining code matched the original version. In coordination with a commercial malware repository, Shiel and O’Shaughnessy created a pipeline that hashed and matched malware families by their section hashes. When analyzing 96 GB worth of malware, and using the best-performing results of each method, the section-level method results in 92 percent more true positives for non-obfuscated malware and 88 percent more for obfuscated malware.
We decided to test their approach with our own data by evaluating this methodology with a specific candidate piece of malware to determine if we could use the section hashes to find other candidate files. We chose HermeticWiper as the test because it was an active piece of malware with reporting from multiple sources.
Dependencies for Section Hash Analysis of Candidate Files
To help identify code reuse with HermeticWiper, we used several tools:
- Pharos, an open-source tool developed by SEI, was used to obtain file hashes.
- A malware repository provided by SEI that gave us access to malware information (however, section hash analysis is not limited to this specific system).
- Python, which we used to
- interact with the malware repository database
- create histograms that can be graphed in programs like Excel
- create graphical output
- We also used publicly available hashes of HermeticWiper and other malware targeted at Ukraine.
A Methodology For Section Hash Analysis
After the initial malware hashes have been identified, the code will pull the relevant file information from the repository, including each file’s MD5 hash, section hashes, type, and size. Other attributes of the file are not needed for the current analysis.
Each file’s information is saved after it has been loaded. Each file’s section hashes are queried at the database to collect new file hashes that share the initial section hashes. This step is incredibly important, because it eliminates all gaps in our initial collection. It also helps show relationships between malware families. Our script improves past research since the file’s hashes are downloaded only from the repository, which is much safer because no malware is downloaded onto the user’s computer.
Having run the entire query, we then graphed the relationship between hash sections and their files. Without much effort during the analysis period, we can provide a visual diagram of these relationships. Figure 1 highlights the section hash relationships of HermeticWiper. The Original Files are rectangles that are light green, these files are connected to the section hashes which are represented as ovals. The blue ovals are DATA sections, the magenta ovals are TEXT sections, the yellow ovals are empty section hashes, and the orange ovals are overlay sections with crypto information in them. Figure 1 shows two clusters of candidates that have two tied to one Text section and the other three sharing a separate TEXT section.
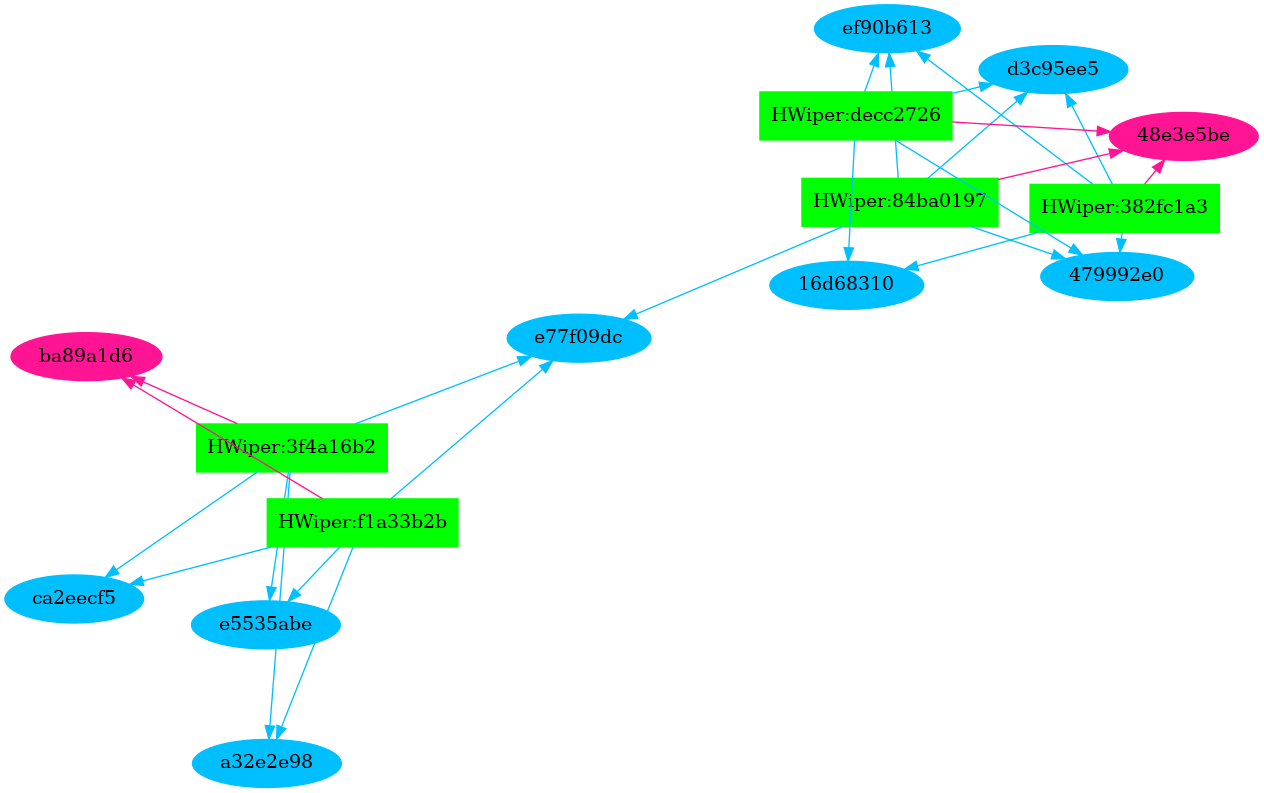
Using Section Hashes to Identify Related Malware Candidates
The resulting piece of software leverages section hashes to identify other pieces of malware. This software has shown us files that may not have been identified previously as part of the family. In the resulting image, Figure 2 below, the new files are shown as dark olive-green rectangles and all newly identified files in the HermeticWiper cluster were indeed malicious. The software also does not need elevated permissions to work or access to the malware itself. All the storage and processing can be done by the server, leaving analysts more time to focus on the higher level analysis. Overall, for our HermeticWiper file, processing took only a matter of minutes.
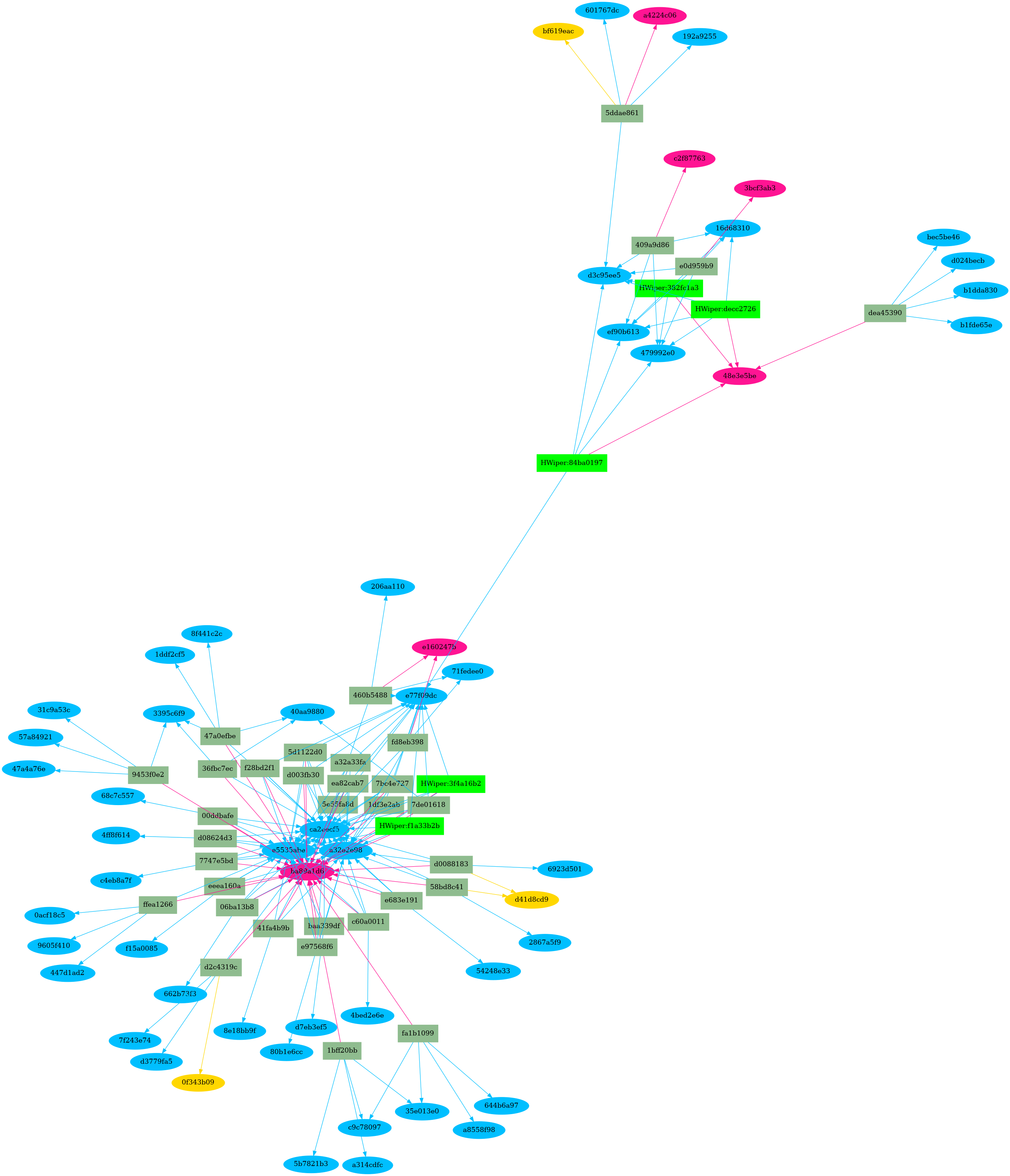
Future Work in Past Section Hashes of Malware Candidates
We are seeing that many functions are also shared between pieces of malware. The next step is to use a similar process for function hashes, which provides additional means of identifying code similarities between candidate software samples. This process can act as a validation and refinement of the section hash similarity analysis. In our HermeticWiper case study, Figure 2 shows we have two clusters of files: 30 files sharing the same TEXT section and four files sharing a different TEXT. The two clusters share 95 percent of their codebase, which indicates that they are related and potentially reflect two different versions of the same application.
We have observed significant clustering around our malware samples, indicating the possibility of auto-classifying malware. Based on the section or function characteristics, if a majority of the section hashes match with a malicious family, it can be defended against without any in-depth analysis. This form of analysis will force attackers to invest significantly in the development process. Each function and section must be unique, which requires expending more resources for each iteration, rather than making incremental improvements over time.
We also need to deal with unpacking and other forms of obfuscation, which will always present a problem when combating malware developers. Adding capabilities into the tool to auto-detect and remediate obfuscation would allow our process to meet higher levels of success, by comparing content and not encrypted blobs.
Automated file-section hash analysis can significantly speed up analysis, because we have proved with a collection of hashes that we can identify executables through shared features without a significant investment of effort. This tool also highlights some interesting uses for the malware repository that have not been explored previously. While the work we did provided a proof of concept to the SEI Malware Family Analysis (MFA) team, we are interested in expanding its capabilities for faster analysis that does not require downloading malware samples. While our tool is rudimentary at present, it has the potential to become a much larger and sophisticated software suite.
Additional Resources
Improving file-level fuzzy hashes for malware variant classification by Ian Shiel, Stephen O'Shaughnessy
HermeticWiper: A detailed analysis of the destructive malware that targeted Ukraine by Hasherezade, Ankur Saini and Roberto Santos
Threat Advisory: HermeticWiper Source: Cisco Talos
Written By


More By The Authors
More In Reverse Engineering for Malware Analysis
PUBLISHED IN
Reverse Engineering for Malware AnalysisGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Reverse Engineering for Malware Analysis
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed