Cost-Effective AI Infrastructure: 5 Lessons Learned


PUBLISHED IN
Artificial Intelligence EngineeringAs organizations across sectors grapple with the opportunities and challenges presented by using large language models (LLMs), the infrastructure needed to build, train, test, and deploy LLMs presents its own unique challenges. As part of the SEI’s recent investigation into use cases for LLMs within the Intelligence Community (IC), we needed to deploy compliant, cost-effective infrastructure for research and development. In this post, we describe current challenges and state of the art of cost-effective AI infrastructure, and we share five lessons learned from our own experiences standing up an LLM for a specialized use case.
The Challenge of Architecting MLOps Pipelines
Architecting machine learning operations (MLOps) pipelines is a difficult process with many moving parts, including data sets, workspace, logging, compute resources, and networking—and all these parts must be considered during the design phase. Compliant, on-premises infrastructure requires advanced planning, which is often a luxury in rapidly advancing disciplines such as AI. By splitting duties between an infrastructure team and a development team who work closely together, project requirements for accomplishing ML training and deploying the resources to make the ML system succeed can be addressed in parallel. Splitting the duties also encourages collaboration for the project and reduces project strain like time constraints.
Approaches to Scaling an Infrastructure
The current state of the art is a multi-user, horizontally scalable environment located on an organization’s premises or in a cloud ecosystem. Experiments are containerized or stored in a way so they are easy to replicate or migrate across environments. Data is stored in individual components and migrated or integrated when necessary. As ML models become more complex and as the volume of data they use grows, AI teams may need to increase their infrastructure’s capabilities to maintain performance and reliability. Specific approaches to scaling can dramatically affect infrastructure costs.
When deciding how to scale an environment, an engineer must consider factors of cost, speed of a given backbone, whether a given project can leverage certain deployment schemes, and overall integration objectives. Horizontal scaling is the use of multiple machines in tandem to distribute workloads across all infrastructure available. Vertical scaling provides additional storage, memory, graphics processing units (GPUs), etc. to improve system productivity while lowering cost. This type of scaling has specific application to environments that have already scaled horizontally or see a lack of workload volume but require better performance.
Generally, both vertical and horizontal scaling can be cost effective, with a horizontally scaled system having a more granular level of control. In either case it is possible—and highly recommended—to identify a trigger function for activation and deactivation of costly computing resources and implement a system under that function to create and destroy computing resources as needed to minimize the overall time of operation. This strategy helps to reduce costs by avoiding overburn and idle resources, which you are otherwise still paying for, or allocating those resources to other jobs. Adapting strong orchestration and horizontal scaling mechanisms such as containers, provides granular control, which allows for clean resource utilization while lowering operating costs, particularly in a cloud environment.
Lessons Learned from Project Mayflower
From May-September 2023, the SEI conducted the Mayflower Project to explore how the Intelligence Community might set up an LLM, customize LLMs for specific use cases, and evaluate the trustworthiness of LLMs across use cases. You can read more about Mayflower in our report, A Retrospective in Engineering Large Language Models for National Security. Our team found that the ability to rapidly deploy compute environments based on the project needs, data protection, and ensuring system availability contributed directly to the success of our project. We share the following lessons learned to help others build AI infrastructures that meet their needs for cost, speed, and quality.
1. Account for your assets and estimate your needs up front.
Consider each piece of the environment an asset: data, compute resources for training, and evaluation tools are just a few examples of the assets that require consideration when planning. When these components are identified and properly orchestrated, they can work together efficiently as a system to deliver results and capabilities to end users. Identifying your assets starts with evaluating the data and framework the teams will be working with. The process of identifying each component of your environment requires expertise from—and ideally, cross training and collaboration between—both ML engineers and infrastructure engineers to accomplish efficiently.

2. Build in time for evaluating toolkits.
Some toolkits will work better than others, and evaluating them can be a lengthy process that needs to be accounted for early on. If your organization has become used to tools developed internally, then external tools may not align with what your team members are familiar with. Platform as a service (PaaS) providers for ML development offer a viable path to get started, but they may not integrate well with tools your organization has developed in-house. During planning, account for the time to evaluate or adapt either tool set, and compare these tools against one another when deciding which platform to leverage. Cost and usability are the primary factors you should consider in this comparison; the importance of these factors will vary depending on your organization’s resources and priorities.
3. Design for flexibility.
Implement segmented storage resources for flexibility when attaching storage components to a compute resource. Design your pipeline such that your data, results, and models can be passed from one place to another easily. This approach allows resources to be placed on a common backbone, ensuring fast transfer and the ability to attach and detach or mount modularly. A common backbone provides a place to store and call on large data sets and results of experiments while maintaining good data hygiene.
A practice that can support flexibility is providing a standard “springboard” for experiments: flexible pieces of hardware that are independently powerful enough to run experiments. The springboard is similar to a sandbox and supports rapid prototyping, and you can reconfigure the hardware for each experiment.
For the Mayflower Project, we implemented separate container workflows in isolated development environments and integrated those using compose scripts. This method allows multiple GPUs to be called during the run of a job based on available advertised resources of joined machines. The cluster provides multi-node training capabilities within a job submission format for better end-user productivity.
4. Isolate your data and protect your gold standards.
Properly isolating data can solve a variety of problems. When working collaboratively, it is easy to exhaust storage with redundant data sets. By communicating clearly with your team and defining a standard, common, data set source, you can avoid this pitfall. This means that a primary data set must be highly accessible and provisioned with the level of use—that is, the amount of data and the speed and frequency at which team members need access—your team expects at the time the system is designed. The source should be able to support the expected reads from however many team members may need to use this data at any given time to perform their duties. Any output or transformed data must not be injected back into the same area in which the source data is stored but should instead be moved into another working directory or designated output location. This approach maintains the integrity of a source data set while minimizing unnecessary storage use and enables replication of an environment more easily than if the data set and working environment were not isolated.
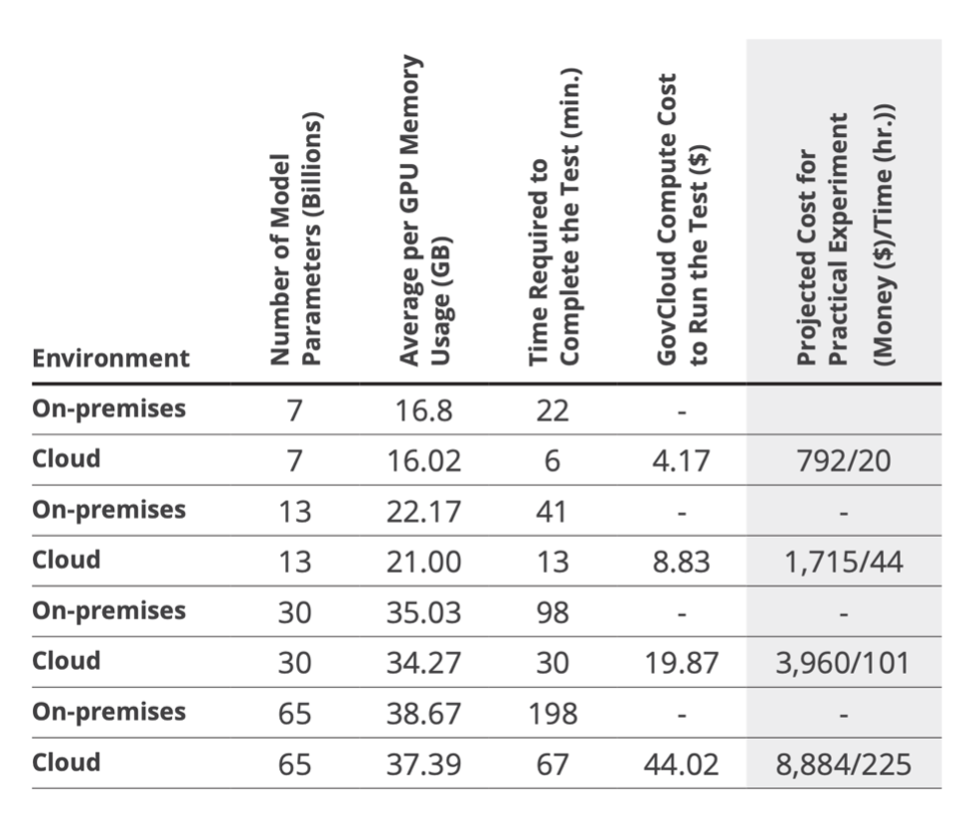
5. Save costs when working with cloud resources.
Government cloud resources have different availability than commercial resources, which often require additional compensations or compromises. Using an existing on-premises resource can help reduce costs of cloud operations. Specifically, consider using local resources in preparation for scaling up as a springboard. This practice limits overall compute time on expensive resources that, based on your use case, may be far more powerful than required to perform initial testing and evaluation.
Looking Ahead
Infrastructure is a major consideration as organizations look to build, deploy, and use LLMs—and other AI tools. More work is needed, especially to meet challenges in unconventional environments, such as those at the edge.
As the SEI works to advance the discipline of AI engineering, a strong infrastructure base can support the scalability and robustness of AI systems. In particular, designing for flexibility allows developers to scale an AI solution up or down depending on system and use case needs. By protecting data and gold standards, teams can ensure the integrity and support the replicability of experiment results.
As the Department of Defense increasingly incorporates AI into mission solutions, the infrastructure practices outlined in this post can provide cost savings and a shorter runway to fielding AI capabilities. Specific practices like establishing a springboard platform can save time and costs in the long run.
Additional Resources
A Retrospective in Engineering Large Language Models for National Security - https://insights.sei.cmu.edu/library/a-retrospective-in-engineering-large-language-models-for-national-security/
Creating a Large Language Model Application Using Gradio - https://insights.sei.cmu.edu/blog/creating-a-large-language-model-application-using-gradio/
11 Leading Practices When Implementing a Container Strategy - https://insights.sei.cmu.edu/blog/11-leading-practices-when-implementing-a-container-strategy/


More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed