Application of Large Language Models (LLMs) in Software Engineering: Overblown Hype or Disruptive Change?


Has the day finally arrived when large language models (LLMs) turn us all into better software engineers? Or are LLMs creating more hype than functionality for software development, and, at the same time, plunging everyone into a world where it is hard to distinguish the perfectly formed, yet sometimes fake and incorrect, code generated by artificial intelligence (AI) programs from verified and well-tested systems?
LLMs and Their Potential Impact on the Future of Software Engineering
This blog post, which builds on ideas introduced in the IEEE paper Application of Large Language Models to Software Engineering Tasks: Opportunities, Risks, and Implications by Ipek Ozkaya, focuses on opportunities and cautions for LLMs in software development, the implications of incorporating LLMs into software-reliant systems, and the areas where more research and innovations are needed to advance their use in software engineering. The reaction of the software engineering community to the accelerated advances that LLMs have demonstrated since the final quarter of 2022 has ranged from snake oil to no help for programmers to the end of programming and computer science education as we know it to revolutionizing the software development process. As is often the case, the truth lies somewhere in the middle, including new opportunities and risks for developers using LLMs.
Research agendas have anticipated that the future of software engineering would include an AI-augmented software development lifecycle (SDLC), where both software engineers and AI-enabled tools share roles, such as copilot, student, expert, and supervisor. For example, our November 2021 book Architecting the Future of Software Engineering: A National Agenda for Software Engineering Research and Development describes a research path toward humans and AI-enabled tools working as trusted collaborators. However, at that time (a year before ChatGPT was released to the public), we didn’t expect these opportunities for collaboration to emerge so rapidly. The figure below, therefore, expands upon the vision presented in our 2021 book to codify the degree to which AI augmentation can be applied in both system operations and the software development lifecycle (Figure 1), ranging from conventional methods to fully AI-augmented methods.
- Conventional systems built using conventional SDLC techniques—This quadrant represents a low degree of AI augmentation for both system operations and the SDLC, which is the baseline of most software-reliant projects today. An example is an inventory management system that uses traditional database queries for operations and is developed using conventional SDLC processes without any AI-based tools or methods.
- Conventional systems built using AI-augmented techniques—This quadrant represents an emerging area of R&D in the software engineering community, where system operations have a low degree of AI augmentation, but AI-augmented tools and methods are used in the SDLC. An example is a website hosting service where the content is not AI augmented, but the development process employs AI-based code generators (such as GitHub Copilot), AI-based code review tools (such as Codiga), and/or AI-based testing tools (such as DiffBlue Cover)
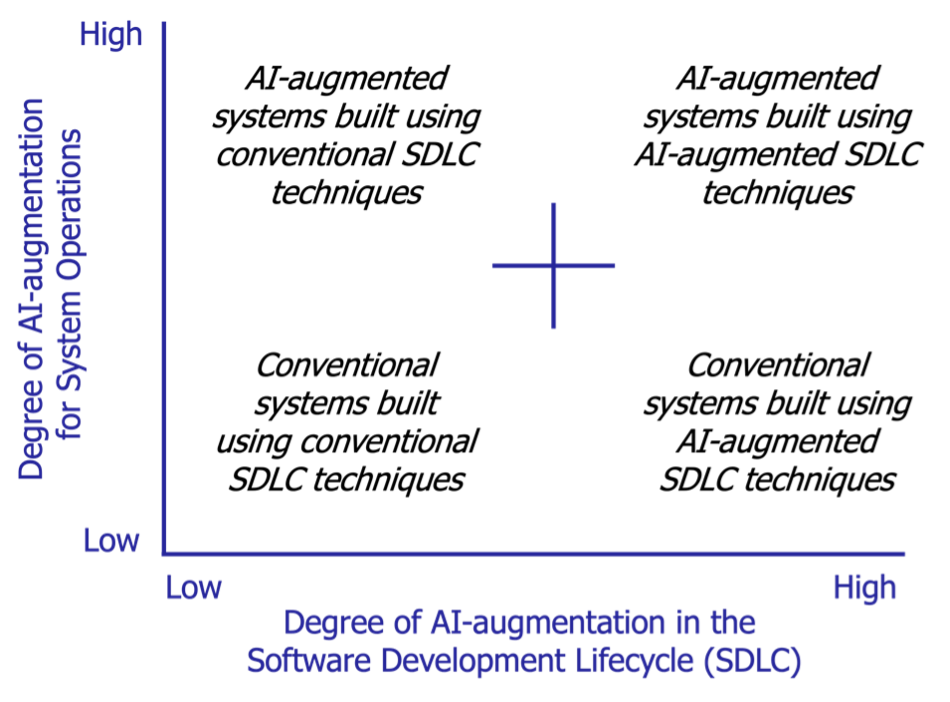
- AI-augmented systems built using conventional SDLC techniques—This quadrant represents a high degree of AI augmentation in systems, especially in operations, but uses conventional methods in the SDLC. An example is a recommendation engine in an e-commerce platform that employs machine learning (ML) algorithms to personalize recommendations, but the software itself is developed, tested, and deployed using conventional Agile methods.
- AI-augmented systems built using AI-augmented techniques—This quadrant represents the pinnacle of AI augmentation, with a high degree of AI-augmentation for both systems operations and the SDLC. An example is a self-driving car system that uses ML algorithms for navigation and decision making, while also using AI-driven code generators, code review and repair tools, unit test generation, and DevOps tools for software development, testing, and deployment.
This blog post focuses on implications of LLMs primarily in the lower-right quadrant (i.e., conventional systems built using AI-augmented SDLC techniques). Future blog posts will address the other AI-augmented quadrants.
Using LLMs to Perform Specific Software Development Lifecycle Activities
The initial hype around using LLMs for software development has already started to cool down, and expectations are now more realistic. The conversation has shifted from expecting LLMs to replace software developers (i.e., artificial intelligence) to considering LLMs as partners and focusing on where to best apply them (i.e., augmented intelligence). The study of prompts is an early example of how LLMs are already impacting software engineering. Prompts are instructions given to an LLM to enforce rules, automate processes, and ensure specific qualities (and quantities) of generated output. Prompts are also a form of programming that can customize the outputs and interactions with an LLM.
Prompt engineering is an emerging discipline that studies interactions with—and programming of—emerging LLM computational systems to solve complex problems via natural language interfaces. An essential component of this discipline is prompt patterns, which are like software patterns but focus on capturing reusable solutions to problems faced when interacting with LLMs. Such patterns elevate the study of LLM interactions from individual ad hoc examples to a more reliable and repeatable engineering discipline that formalizes and codifies fundamental prompt structures, their capabilities, and their ramifications.
Many software engineering tasks can benefit from using more sophisticated tools, including LLMs, with the help of relevant prompt engineering strategies and more sophisticated models. Indulge us for a moment and assume that we have solved thorny issues (such as trust, ethics, and copyright ownership) as we enumerate potential use cases where LLMs can create advances in productivity for software engineering tasks, with manageable risks:
- analyze software lifecycle data—Software engineers must review and analyze many types of data in large project repositories, including requirements documents, software architecture and design documents, test plans and data, compliance documents, defect lists, and so on, and with many versions over the software lifecycle. LLMs can help software engineers rapidly analyze these large volumes of information to identify inconsistencies and gaps that are otherwise hard for humans to find with the same degree of scalability, accuracy, and effort.
- analyze code—Software engineers using LLMs and prompt engineering patterns can interact with code in new ways to look for gaps or inconsistencies. With infrastructure-as-code (IaC) and code-as-data approaches, such as CodeQL, LLMs can help software engineers explore code in new ways that consider multiple sources (ranging from requirement specifications to documentation to code to test cases to infrastructure) and help find inconsistencies between these various sources.
- just-in-time developer feedback—Applications of LLMs in software development have been received with skepticism, some deserved and some undeserved. While the code generated by current AI assistants, such as Copilot, may incur more security issues, in time this will improve as LLMs are trained on more thoroughly vetted data sets. Giving developers syntactic corrections as they write code also helps reduce time spent in code conformance checking.
- improved testing—Developers often shortcut the task of generating unit tests. The ability to easily generate meaningful test cases via AI-enabled tools can increase overall test effectiveness and coverage and consequently help improve system quality.
- software architecture development and analysis—Early adopters are already using design vocabulary-driven prompts to guide code generation using LLMs. Using multi-model inputs to communicate, analyze, or suggest snippets of software designs via images or diagrams with supporting text is an area of future research and can help augment the knowledge and impact of software architects.
- documentation—There are many applications of LLMs to document artifacts in the software development process, ranging from contracting language to regulatory requirements and inline comments of tricky code. When LLMs are given specific data, such as code, they can create cogent comments or documentation. The reverse is also true in that when LLMs are given multiple documents, people can query LLMs using prompt engineering to generate summaries or even answers to specific questions rapidly. For example, if a software engineer must follow an unfamiliar software standard or software acquisition policy, they can provide the software standard or policy document to an LLM and use prompt engineering to summarize, document, ask specific questions, and even ask for examples. LLMs accelerate the learning of engineers who must use this knowledge to develop and sustain software-reliant systems.
- programming language translation—Legacy software and brownfield development is the norm for many systems developed and sustained today. Organizations often explore language translation efforts when they need to modernize their systems. While some good tools exist to support language translation, this process can be expensive and error prone. Portions of code can be translated to other programming languages using LLMs. Performing such translations at speed with increased accuracy provides developers with more time to fill other software development gaps, such as focusing on rearchitecting and generating missing tests.
Advancing Software Engineering Using LLMs
Does generative AI really represent a highly productive future for software development? The slew of products entering the field in software development automation, including (but certainly not limited to) AI coding assistant tools, such as Copilot, CodiumAI, Tabnine, SinCode, and CodeWhisperer, position their products with this promise. The opportunity (and challenge) for the software engineering community is to discover whether the fast-paced improvements in LLM-based AI assistants fundamentally change how developers engage with and perform software development activities.
For example, an AI-augmented SDLC will likely have different task flows, efficiencies, and roadblocks than the current development lifecycles of Agile and iterative development workflows. In particular, rather than thinking about steps of development as requirements, design, implementation, test, and deploy, LLMs can bundle these tasks together, particularly when combined with recent LLM-based tools and plug-ins, such as LangChain and ChatGPT Advanced Data Analysis. This integration may influence the number of hand-offs and where they happen, shifting task dependencies within the SDLC.
While the excitement around LLMs continues, the jury is still out on whether AI-augmented software development powered by generative AI tools and other automated methods and tools will achieve the following ambitious objectives:
- 10x or more reduction in resource needs and error rates
- support for developers in managing ripple effects of changes in complex systems
- reduction in the need for extensive testing and analysis
- modernization of the DoD codebases from memory unsafe languages to memory safe ones with a fraction of effort required
- support for certification and assurance considerations knowing that there is unpredictable emergent behavior challenges
- enabling analysis of increasing software size and complexity through increased automation
Even if a fraction of the above is accomplished, it will influence the flow of activities in the SDLC, likely enabling and accelerating the shift-left actions in software engineering. The software engineering community has an opportunity to shape the future research on developing and applying LLMs by gaining first-hand knowledge of how LLMs work and by asking key questions about how to use them effectively and ethically.
Cautions to Consider When Applying LLMs in Software Engineering
It is important to also acknowledge the drawbacks of applying LLMs to software engineering. The probabilistic and randomized selection of the next word in constructing the outputs in LLMs can give the end user the impression of correctness, yet the content often contains mistakes, which are referred to as “hallucinations.” Hallucinations are a great concern for anyone who blindly applies the output generated by LLMs without taking the time and effort to verify the results. While significant improvements in models have been made recently, several areas of caution surround their generation and use, including
- data quality and bias—LLMs require enormous amounts of training data to learn language patterns, and their outputs are highly dependent on the data that they are trained on. Any issues that exist in the training data, such as biases and mistakes, will be amplified by LLMs. For example, ChatGPT-4 was originally trained on data through September 2021, which meant the model’s recommendations were unaware of data from the past two years until recently. However, the quality and representativeness of the training data has a significant impact on the model’s performance and generalizability, so mistakes propagate easily.
- privacy and security—Privacy and security are key concerns in using LLMs, especially in environments, such as the DoD and intelligence communities, where information is often controlled or classified. The popular press is full of examples of leaking proprietary or sensitive information. For example, Samsung workers recently admitted that they unwittingly disclosed confidential data and code to ChatGPT. Applying these open models in sensitive settings not only risks yielding faulty results, but also risks unknowingly releasing confidential information and propagating it to others.
- content ownership—LLMs are generated using content developed by others, which may contain proprietary information and content creators’ intellectual property. Training on such data using patterns in recommended output creates plagiarism concerns. Some content is boilerplate, and the ability to generate output in correct and understandable ways creates opportunities for improved efficiency. However, other content, including code, is not trivial to differentiate whether it is human or machine generated, especially where individual contributions or concerns such as certification matter. In the long run, the increasing popularity of LLMs will likely create boundaries around data sharing and open-source software and open science. In a recent example, Japan’s government determined that copyrights are not enforceable with data used in AI training. Techniques to indicate ownership or even prevent certain data from being used to train these models will likely emerge, though such techniques and attributes to complement LLMs are not yet widespread.
- carbon footprint—Vast amounts of computing power is required to train deep learning models, which is raising concerns about the impact on carbon footprint. Research in different training techniques, algorithmic efficiencies, and varying allocation of computing resources will likely increase. In addition, improved data collection and storage techniques are anticipated to eventually reduce the impact of LLMs on the environment, but development of such techniques is still in its early phase.
- explainability and unintended consequence—Explainability of deep learning and ML models is a general concern in AI, including (but not limited to) LLMs. Users seek to understand the reasoning behind the recommendations, especially if such models will be used in safety-, mission-, or business-critical settings. Dependence on the quality of the data and the inability to trace the recommendations to the source increase trust concerns. In addition, since LLM training sequences are generated using a randomized probabilistic approach, explainability of correctness of the recommendations creates added challenges.
Areas of Research and Innovation in LLMs
The cautions and risks related to LLMs described in this post motivate the need for new research and innovations. We are already starting to see an increased research focus in foundation models. Other areas of research are also emerging, such as creating integrated development environments with the latest LLM capabilities and reliable data collection and use techniques that are targeted for software engineering. Here are some research areas related to software engineering where we expect to see significant focus and progress in the near future:
- accelerating upstream software engineering activities—LLMs’ potential to assist in documentation-related activities extends to software acquisition pre-award documentation preparation and post-award reporting and milestone activities. For example, LLMs can be applied as a problem-solving tool to help teams tasked with assessing the quality or performance of software-reliant acquisition programs by assisting acquirers and developers to analyze large repositories of documents related to source selection, milestone reviews, and test activities.
- generalizability of models—LLMs currently work by pretraining on a large corpus of content followed by fine-tuning on specific tasks. Although the architecture of an LLM is task independent, its application for specific tasks requires further fine-tuning with a substantially large number of examples. Researchers are already focusing on generalizing these models to applications where data are sparse (known as few-shot learning).
- new intelligent integrated development environments (IDEs)—If we are convinced by preliminary evidence that some programming tasks can be accelerated and improved in correctness by LLM-based AI assistants, then conventional integrated development environments (IDEs) will need to incorporate these assistants. This process has already begun with the integration of LLMs into popular IDEs, such as Android Studio, IntelliJ, and Visual Studio. When intelligent assistants are integrated in IDEs, the software development process becomes more interactive with the tool infrastructure while requiring more expertise from developers to assist in vetting the outcomes.
- creation of domain-specific LLMs—Given the limitations in training data and potential privacy and security concerns, the ability to train LLMs that are specific to certain domains and tasks provides an opportunity to manage the risks in security, privacy, and proprietary information, while reaping the benefits of generative AI capabilities. Creating domain-specific LLMs is a new frontier with opportunities to leverage LLMs while reducing the risk of hallucinations, which is particularly important in the healthcare and financial domains. FinGPT is one example of a domain-specific LLM.
- data as a unit of computation—The most critical input that drives the next generation of AI innovations is not only the algorithms, but also data. A significant portion of computer science and software engineering talent will thus shift to data science and data engineer careers. Moreover, we need more tool-supported innovations in data collection, data quality assessment, and data ownership rights management. This research area has significant gaps that require skill sets spanning computer science, policy, and engineering, as well as deep knowledge in security, privacy, and ethics.
The Way Forward in LLM Innovation for Software Engineering
After the two winters of AI in the late 1970s and early 1990s, we have entered not only a period of AI blossoms, but also exponential growth in funding, use, and alarm about AI. Advances in LLMs without a doubt are huge contributors to this growth of all three. Whether the next phase of innovations in AI-enabled software engineering includes capabilities beyond our imagination or it becomes yet another AI winter largely depends on our ability to (1) continue technical innovations and (2) practice software engineering and computer science with the highest level of ethical standards and responsible conduct. We must be bold in experimenting with the potential of LLMs to improve software development, yet also be cautious and not forget the fundamental principles and practices of engineering ethics, rigor, and empirical validation.
As described above, there are many opportunities for research in innovation for applying LLMs in software engineering. At the SEI we have ongoing initiatives that include identifying DoD-relevant scenarios and experimenting with the application of LLMs, as well pushing the boundaries of applying generative AI technologies to software engineering tasks. We will report our progress in the coming months. The best opportunities for applying LLMs in the software engineering lifecycle may be in the activities that play to the strengths of LLMs, which is a topic we’ll explore in detail in upcoming blogs.
Additional Resources
Read Architecting the Future of Software Engineering: A National Agenda for Software Engineering Research & Development by Anita Carleton, Mark H. Klein, John E. Robert, Erin Harper, Robert K. Cunningham, Dionisio de Niz, John T. Foreman, John B. Goodenough, James D. Herbsleb, Ipek Ozkaya, Douglas Schmidt (Vanderbilt University), and Forrest Shull.
Read the IEEE paper Application of Large Language Models to Software Engineering Tasks: Opportunities, Risks, and Implications by Ipek Ozkaya.
Written By




More By The Authors
More In Software Engineering Research and Development
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Engineering Research and Development
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed