A Hitchhiker’s Guide to ML Training Infrastructure

PUBLISHED IN
Artificial Intelligence EngineeringHardware has made a huge impact on the field of machine learning (ML). Many of the ideas we use today were published decades ago, but the cost to run them and the data necessary were too expensive, making them impractical. Recent advances, including the introduction of graphics processing units (GPUs), are making some of those ideas a reality. In this post we’ll look at some of the hardware factors that impact training artificial intelligence (AI) systems, and we’ll walk through an example ML workflow.
Why is Hardware Important for Machine Learning?
Hardware is a key enabler for machine learning. Sara Hooker, in her 2020 paper “The Hardware Lottery” details the emergence of deep learning from the introduction of GPUs. Hooker’s paper tells the story of the historical separation of hardware and software communities and the costs of advancing each field in isolation: that many software ideas (especially ML) have been abandoned because of hardware limitations. GPUs enable researchers to overcome many of those limitations because of their effectiveness for ML model training.
What Makes a GPU Better than a CPU for Model Training?
GPUs have two important traits that make them effective for ML training
high memory bandwidth—Machine learning operates by creating an initial model and training it. A model describes a set of transformations that happen to the input to generate a result. The transformations are often multiplying the input by a number of matrixes. The architecture of the model will determine the number, order, and shape of the matrices. Those matrices are often huge, so successful machine learning requires the high-memory bandwidth provided by GPUs. Models can start at megabytes of memory and can go up to gigabytes or even terabytes. While a CPU can calculate math operations faster than a GPU, the bandwidth between the GPU and memory is much wider. A CPU bandwidth is 90 GBps versus a GPU bandwidth of 2000 GBps, which means loading the model and the data into the GPU for calculation will be much faster than into the CPU.
large registers and L1 memory—GPUs are designed with registers near the execution unit, which keeps data close to the calculations to minimize the time the execution unit is waiting for load. GPUs keep larger registers close to the execution units compared to CPUs, which allows keeping more data close to the execution units and for more processing per clock cycle. While a single math operation will run faster on a CPU than on a GPU, a large number of operations will run faster on a GPU. Metaphorically speaking, a CPU is a Formula 1 racer, and a GPU is a school bus. On a single run moving a person from A to B, the CPU is better, but if the goal is to move 30 people, the GPU can do it in one run while the CPU must take multiple trips.
Memory
In most ML tutorials, the datasets are small and the models are simple. Building an object detector, such as a cat identifier, can be done with small data sets and simple architectures, but for some problems require bigger models and more data. For instance, there is a certain level of data preparation necessary to work with satellite imagery to get an image into memory.
To optimize performance the GPU must be fed with more data to process, which requires the data pipeline to move data from storage (often disk) to system memory, so that it can be moved to the GPU memory. This move involves transferring large, contiguous segments of memory from RAM to the GPU, so the speed of the RAM is often not a bottleneck of work. Having less RAM than the GPU means the operating system will be paging out to disk frequently. For efficient processing, the amount of RAM for the system should be greater than the amount of memory on the GPU, enough to load the operating system, the applications and enough data that a copy to the GPU will fill GPU memory. For multi-GPU systems, therefore, the system RAM should equal or exceed the total amount of device memory for all GPUs combined. If you have a system with 1 GPU with 16 GB of RAM you need at least 16 GB + enough memory to run your operating system and application. If you have a machine with 2 GPUs with 40 GB of RAM each, you will want a system with over 80 GB of RAM to make sure you have enough to run your OS and application.
Moving to Multiple GPUs
While multiple GPUs on a system can be used to train separate models in parallel for larger models or faster processing, it may be necessary to use multiple GPUs to train a single model. There are several methods for creating and distributing batches of data to multiple GPUs on the same system. For most computers (such as laptop, desktops, and server) the fastest way to move data is on the PCIe bus. However, the most efficient method available today is NVLink to move data between NVIDIA GPUs. NVLink (1.0/2.0/3.0) allows transfers of 20/25/50 GBps per sublink, moving up to 600 GBps across all links. A link contains two sublinks (one in each direction). This architecture provides enormous speed-ups over PCIe Gen 4, which has a theoretical maximum of 32 GBps, the recent release of PCIe Gen5 with a maximum of 63 GB/s, or the newly announced PCIe Gen 5 with a max of 121 GB/s. The market is changing and competition is growing, for instance Apple’s new M1 Max architecture uses a shared memory system on a chip that allows up to 408 GB/s to the GPU.
Moving to Multiple Machines
For some models, one computer may not have sufficient capacity. To support distributed training, a number of toolkits including Distributed TensorFlow, Torch.Distributed, and Horovod can be used to distribute work among several machines, but for optimal performance, the network must be considered. The data fabric between these machines must be wider than traditional server networking.
Often systems used for large-scale model training use Infiniband to move data between nodes. NVIDIA cards can take advantage of GPU remote memory direct access (RDMA) to move data directly over the PCIe to an Infiniband NIC to move data without copying to CPU memory. These interfaces are usually exclusive to the training cluster and are separate from the management or network interfaces.These interfaces are usually exclusive to the training cluster and are separate from the management or network interfaces.
What Does This Mean in Practice?
Let’s look at a workflow for an ML application, starting from data exploration to production. In the figure below, from Google’s ML Ops article, an ML system has a few associated pipelines, including one for experimentation and discovery and one for production.
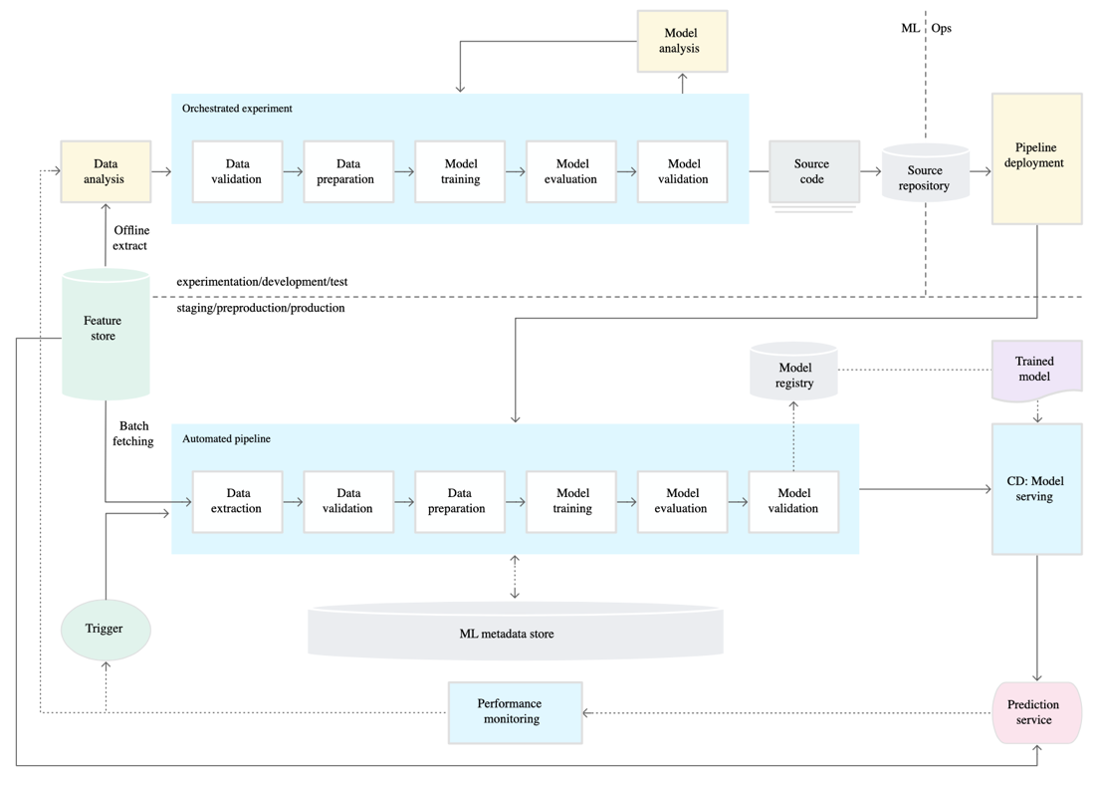
There are some components shared between the two pipelines, but the intent and resource needs can be very different.
Experiment/Development/Test
Our application starts with data analysis. Before we begin we must determine if the problem is one that ML can solve. After identifying the problem, it is necessary to see if there is sufficient data to solve the problem. During data analysis, a data scientist could be using a Jupyter notebook, Python, or R to understand the characteristics of the data. These tools can be run on a laptop, desktop, or from a web-based platform. For much of the initial data analysis, the system will be CPU/memory or storage bound, so a GPU is often not as important for this step. As the models are trained and analyzed for performance, however, a GPU may be needed to replicate production training sequences.
In the experimental phase, our goal is to see if there is a viable method for solving our problem. To do this exploration data scientists often use a workflow similar to the one below. First, we must validate the data make sure it is clean and suited to the task. Next is data preparation or feature engineering, transforming the data so that we can start training a model. After training we’ll want to evaluate the model. The first step should establish a baseline that we can compare to as we iterate on new models or architectures. In the early steps accuracy might be the most important attribute we evaluate, but depending on our use case other attributes can be as important if not more important. After validation we do model analysis and continue to iterate on developing our model.
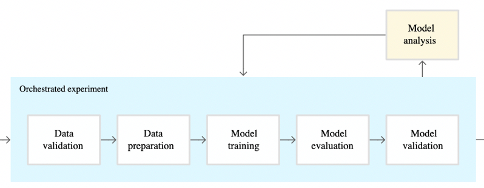
The work done in this part is usually a mix of data engineering and data science. Data engineering is used for data validation, which is a process to ensure that data is consistent and understood. Data validation could include data validation for checking the data is in a valid or expected range. This work does not usually require matrix operations and is generally just a CPU or input-output(IO) bound.
Data preparation can include a number of different activities. Data preparation can be labelling of the data set, or it can be transforming/formatting the data into a format that will be more easily consumed by the training process (e.g., changing a color image to black and white). It may be transforming the data so that features are readily accessible for training. Much of the operations in the data preparation are again CPU bound. Feature engineering may include calculating or synthesizing a new value based on existing features, but again this is usually CPU bound.
Model training is where things start to get interesting for infrastructure. Some small-scale experiments can be handled with a CPU, but for many models and data sets, the CPU calculations are not efficient. Machine learning depends on matrix multiplication as a key component. While the ML revolution came about thanks to the proliferation of graphics cards, which used large amounts of matrix multiplication in parallel for graphic computation, modern systems have dedicated units for managing ML specific operations.
In the simplest description, for a particular training data set D, an experiment will run a number of training cycles or epochs. For each epoch a batch of data will be moved from disk to host memory and from host memory to device memory, a process will run on the device, the results will move back from device to system memory, and the process repeats again until all the epochs are complete.
Model evaluation is the process of understanding the fit of our model to our task. Accuracy is often the first measure evaluated, but other metrics can be more important for your business case. From a hardware perspective one of the important things to evaluate is how well the trained model performs on your target platform. The target platform may be very different than the platform you use for training the models. For instance, in building mobile ML applications for use on the edge you need to ensure your model is capable of running on the specialized hardware of smart phones. Today with ML applications being at the forefront of their businesses, both Apple and Google have pushed for dedicated AI processors to accelerate these applications. For applications hosted in the cloud it maybe more cost effective to train models on GPUs, but run inference on CPUs. Evaluation should validate that the performance on your target platform is acceptable.
Automating the Production Workflow
After evaluation is completed and the model meets the criteria required for the business, it is important to set up a pipeline for the automated construction of new models for production. ML applications are more sensitive to changing conditions than typical software applications. Production systems should be monitored and results evaluated to detect model or data drift. As drift occurs, new data should be gathered to retrain your model. Retraining frequency varies between models, applications, and use cases, but having a good infrastructure ready to support retraining is critical to success. Your production pipeline may require more speed or memory than your experimental pipeline. To scale to the data and keep training time effective, you may need to leverage multiple GPUs on multiple machines.
Testing your Hardware
AI systems have some different properties than traditional software systems. From an infrastructure perspective, however, there is still a great deal of commonality on how to manage them. When building for capacity, it pays to test and measure the actual performance of your system. Performance testing is critical to build and scale any software system.
Ideally you can work with the models you are already building to test and measure performance to learn where your bottlenecks are and where you can make improvements. If you are establishing your first system or your workloads vary greatly, it may make sense to use existing benchmarks to test your system.
MLPerf (a part of the MLCommons) is an open-source, public benchmark for a variety of ML training and inference tasks. Current performance benchmarks are available for training and inference on a number of different tasks including image classification, object detection (light-weight), object detection (heavy-weight), translation (recurrent), translation (non-recurrent), Natural Language Processing, recommendation and reinforcement learning. Picking an MLPerf benchmark that is close to your chosen workload provides a way to see what kind of hardware or system would most benefit your infrastructures.
The Path Ahead
The growth of hardware for ML is just starting to explode. The large tech companies have started building their own hardware that is improving at a rate faster than Moore’s Law would dictate. Google’s Tensor Processing Units, Amazon’s Tranium, or Apple’s A-series and M-series each provide their own tradeoffs and capabilities. At the same time new models and architectures are requiring more speed and memory from hardware. It is estimated that the Open AI GPT model cost $12 million for a single training run. Mission needs will continue to push new requirements on AI systems, but as the field matures and engineering practices are established teams will be able to make smarter decisions on how to meet these new needs.
Advancing these engineering practices and maturing the field are important parts of our mission within the SEI’s AI Division: to do AI as well as AI can be done. We’re looking at turning the art and craft of building AI and ML systems into an engineering discipline to let us push the bounds. We work on extracting the lessons learned from building ML and codifying what we find to make it easier for others. As we extract those lessons learned—including lessons from the hardware that enables ML—we are looking for collaborators and advocates. Join us via the National AI Engineering Initiative and our newly formed advanced computing lab.
Additional Resources
- https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/#How_do_GPUs_work
- https://www.quora.com/Why-are-GPUs-well-suited-to-deep-learning/answer/Tim-Dettmers-1
- Lambda Labs – Introduction to Multi GPU and Multi Node Distributed Training
- https://en.wikipedia.org/wiki/NVLink
- https://frankdenneman.nl/2020/01/30/machine-learning-workload-and-gpgpu-numa-node-locality/
- https://spectrum.ieee.org/ai-training-mlperf
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed