Using ChatGPT to Analyze Your Code? Not So Fast

The average code sample contains 6,000 defects per million lines of code, and the SEI’s research has found that 5 percent of these defects become vulnerabilities. This translates to roughly 3 vulnerabilities per 10,000 lines of code. Can ChatGPT help improve this ratio? There has been much speculation about how tools built on top of large language models (LLMs) might impact software development, more specifically, how they will change the way developers write code and evaluate it.
In March 2023 a team of CERT Secure Coding researchers—the team included Robert Schiela, David Svoboda, and myself—used ChatGPT 3.5 to examine the noncompliant software code examples in our CERT Secure Coding standard, specifically the SEI CERT C Coding Standard. In this post, I present our experiment and findings, which show that while ChatGPT 3.5 has promise, there are clear limitations.
Foundations of Our Work in Secure Coding and AI
The CERT Coding Standards wiki, where the C standard lives, has more than 1,500 registered contributors, and coding standards have been completed for C, Java, and C++. Each coding standard includes examples of noncompliant programs that pertain to each rule in a standard. The rules in the CERT C Secure Coding standard are organized into 15 chapters broken down by subject area.
Each rule in the coding standard contains one or more examples of noncompliant code. These examples are drawn from our experience in evaluating program source code and represent very common programming errors that can lead to weaknesses and vulnerabilities in programs, unlike artificially generated test suites, such as Juliet. Each example error is followed by one or more compliant solutions, that illustrate how to bring the code into compliance. The C Secure Coding Standard has hundreds of examples of noncompliant code, which provided us a ready-made database of coding errors to run through ChatGPT 3.5, as well as fixes that could be used to evaluate ChatGPT 3.5’s response.
Given that we could easily access a sizable database of coding errors, we decided to investigate ChatGPT 3.5’s effectiveness in analyzing code. We were motivated, in part, by the rush of many in software to embrace ChatGPT 3.5 for writing code and fixing bugs in the months following its November 2022 release by Open AI.
Running Noncompliant Software Through ChatGPT 3.5
We recently took each of those noncompliant C programs and ran it through ChatGPT 3.5 with the prompt
What is wrong with this program?
As part of our experiment, we ran each coding sample through ChatGPT 3.5 individually, and we submitted each coding error into the tool as a new conversation (i.e., none of the trials were repeated). Given that ChatGPT is generative AI technology and not compiler technology, we wanted to assess its evaluation of the code and not its ability to learn from the coding errors and fixes outlined in our database.
Compilers are deterministic and algorithmic, whereas technologies underlying ChatGPT are statistical and evolving. A compiler’s algorithm is fixed and independent of software that has been processed. ChatGPT’s response is influenced by the patterns processed during training.
At the time of our experiment, March 2023, Open AI had trained ChatGPT 3.5 on Internet content up to a cutoff point of September 2021. (In September 2023, however, Open AI announced that ChatGPT could browse the web in real-time and now has access to current data). Given that our C Secure Coding Standard has been publicly accessible since 2008, we assume that our examples were part of the training data used to build ChatGPT 3.5. Consequently, in theory, ChatGPT 3.5 might have been able to identify all noncompliant coding errors contained within our database. Moreover, the coding errors included in our C Secure Coding Standard were all errors that are commonly found in the wild. Hence, there have been a significant number of articles posted online regarding these errors that should have been part of ChatGPT 3.5’s training data.
ChatGPT 3.5 Responses: Simple Examples
The following samples show noncompliant code taken from the CERT Secure Coding wiki, as well as our team’s experiments with ChatGPT 3.5 responses in response to our experimental submissions of coding errors.
As the Figure 1 below illustrates, ChatGPT 3.5 performed well with an example we submitted of a common coding error: a noncompliant code example where two parameters had been switched.

ChatGPT 3.5, in its response, correctly identified and remedied the noncompliant code and offered the correct solution to the problem:

Interestingly, when we submitted an example of the noncompliant code that led to the Heartbleed vulnerability, ChatGPT 3.5 did not identify that the code contained a buffer over-read, the coding error that led to the vulnerability. Instead, it noted that the code was a portion of Heartbleed. This was a reminder that ChatGPT 3.5 does not use compiler-like technology but rather generative AI technology.

ChatGPT 3.5 Responses that Needed Adjudicating
With some responses, we needed to draw on our deep subject matter expertise to adjudicate a response. The following noncompliant code sample and compliant recommendation is from the rule EXP 42-C. Do not compare padding data:

When we submitted the code to ChatGPT 3.5, however, we received the following response.

We reasoned that ChatGPT should be given credit for the response because it identified the key issue, which was the need to check each field individually, not the entire memory used by the data structure. Also, the suggested fix was consistent with one interpretation of the data structure. The confusion seemed to stem from the fact that, in C, there is ambiguity about what a data structure means. Here, buffer can be an array of characters, or it can be a string. If it is a string, ChatGPT 3.5’s response was a better answer, but it is still not the correct answer. If buffer is only an array of characters, then the response is incorrect because a string comparison stops when a value of “0” is found whereas array elements after that point could differ. At face value, one might conclude that ChatGPT 3.5 made an arbitrary choice that diverged from our own.
One could have taken a deeper analysis of this example to try to answer the question of whether ChatGPT 3.5 should have been able to distinguish what “buffer” intended. First, strings are commonly pointers, not fixed arrays. Second, the identifier “buffer” is typically associated with an array of things and not a string. There is a body of literature in reverse engineering that attempts to recreate identifiers in the original source code by matching patterns observed in practice with identifiers. Given that ChatGPT is also examining patterns, we believe that most examples of code it found probably used a name like “string” (or “name,” “address,” etc.) for a string, while buffer would not be associated with a string. Hence, one can make the case that ChatGPT 3.5 did not correctly fix the issue completely. In these instances, we usually gave ChatGPT 3.5 the benefit of the doubt even though a novice just cutting and pasting would wind up introducing other errors.
Cases Where ChatGPT 3.5 Missed Obvious Coding Errors
In other instances, we fed in samples of noncompliant code, and ChatGPT 3.5 missed obvious errors.

In yet other instances, ChatGPT 3.5 focused on a trivial issue but missed the true issue, as outlined in the example below. (As an aside: also note that the suggested fix to use snprintf was already in the original code.)

As outlined in the secure coding rule for this error,
Use of the system() function can result in exploitable vulnerabilities, in the worst case allowing execution of arbitrary system commands. Situations in which calls to system() have high risk include the following:
- when passing an unsanitized or improperly sanitized command string originating from a tainted source
- if a command is specified without a path name and the command processor path name resolution mechanism is accessible to an attacker
- if a relative path to an executable is specified and control over the current working directory is accessible to an attacker
- if the specified executable program can be spoofed by an attacker
Do not invoke a command processor via system() or equivalent functions to execute a command.
As shown below, ChatGPT 3.5 instead identified a non-existent problem in the code with this call on the snsprintf() and cautioned again against a buffer overflow with that call.
Overall Performance of ChatGPT 3.5
As the diagram below shows, ChatGPT 3.5 correctly identified the problem 46.2 percent of the time. More than half of the time, 52.1 percent, ChatGPT 3.5 did not identify the coding error at all. Interestingly, 1.7 percent of the time, it flagged a program and noted that there was a problem, but it declared the problem to be an aesthetic one rather than an error.

We could also examine a bit more detail to see if there were particular types of errors that ChatGPT 3.5 was either better or worse at identifying and correcting. The chart below shows performance broken out by the feature involved.
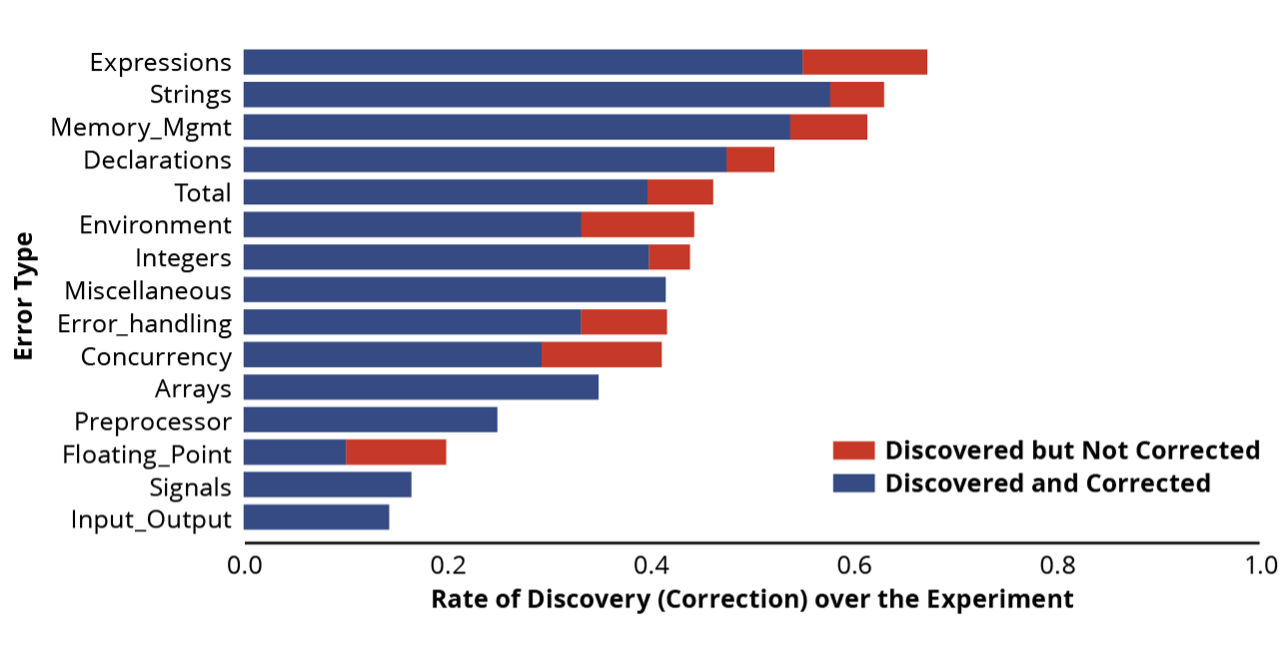
As the bar graph above illustrates, based on our analysis, ChatGPT 3.5 seemed particularly adept at
- finding and fixing integers
- finding and fixing expressions
- finding and fixing memory management
- finding and fixing strings
ChatGPT 3.5 seemed most challenged by coding errors that included
- finding the floating point
- finding the input/output
- finding signals
We surmised that ChatGPT 3.5 was better versed in issues such as finding and fixing integer, memory management, and string errors, because those issues have been well documented throughout the Internet. Conversely, there has not been as much written about floating point errors and signals, which would give ChatGPT 3.5 fewer resources from which to learn.
The ChatGPT Future
These results of our analysis show that ChatGPT 3.5 has promise, but there are clear limitations. The mechanism used by LLMs heavily depends on pattern matching based on training data. It is remarkable that using patterns of completion – “what is the next word” – can perform detailed program analysis when trained with a large enough corpus. The implications are three-fold:
- One might expect that only the most common kinds of patterns would be found and applied. This expectation is reflected in the earlier data, where commonly discussed errors had a better rate of detection than more obscure errors. Compiler-based technology works the same way regardless of an error's prevalence. Its ability to find a type of error is independent of whether the error appears in 1 in 10 programs, a scenario heavily favored by LLM-based techniques, or 1 in 1000.
- One should be cautious of the tyranny of the majority. In this context, LLMs can be fooled into identifying a common pattern to be a correct pattern. For example, it is well known that programmers cut and paste code from StackOverflow, and that StackOverflow code has errors, both functional and vulnerable. Large numbers of programmers who propagate erroneous code could provide the recurring patterns that an LLM-based system would use to identify a common (i.e., good) pattern.
- One could imagine an adversary using the same tactic to introduce vulnerability that would be generated by the LLM-based system. Having been trained on the vulnerable code as common (and therefore “correct” or “preferred”), the system would generate the vulnerable code when asked to provide the specified function.
LLM-based code analysis should not be disregarded entirely. In general, there are strategies (such as prompt engineering and prompt patterns) to mitigate the challenges listed and extract reliable value. Research in this area is active and on-going. For examples, updates included in ChaptGPT 4 and CoPilot already show improvement when applied to the types of secure coding vulnerabilities presented in this blog posting. We are looking at these versions and will update our results when completed. Until those results are available, knowledgeable users must review the output to determine if it can be trusted and used.
Our team’s experience in teaching secure coding classes has taught us that developers are often not proficient at reviewing and identifying bugs in the code of other developers. Based on experiences with repositories like StackOverflow and GitHub, we are concerned about scenarios where ChatGPT 3.5 produces a code analysis and an attempted fix, and users are more likely to cut and paste it than to determine if it might be incorrect. In the short term, therefore, a practical tactic is to manage the culture that uncritically accepts the outputs of systems like ChatGPT 3.5.
Additional Resources
Read the SEI blog post Application of Large Language Models (LLMs) in Software Engineering: Overblown Hype or Disruptive Change? by my colleagues Ipek Ozkaya, Anita Carleton, John Robert, and Douglas C. Schmidt.
Read the SEI blog post Harnessing the Power of Large Language Models for Economic and Social Good: 4 Case Studies by my colleagues Matthew Walsh, Dominic Ross, Clarence Worrell, and Alejandro Gomez.
Listen to the podcast The Messy Middle of Large Language Models by Jay Palat and Rachel Dzombak.
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed