System Resilience: What Exactly is it?

PUBLISHED IN
Cybersecurity EngineeringOver the past decade, system resilience (a.k.a., system resiliency) has been widely discussed as a critical concern, especially in terms of data centers and cloud computing. It is also vitally important to cyber-physical systems, although the term is less commonly used in that domain. Everyone wants their systems to be resilient, but what does that actually mean? And how does resilience relate to other quality attributes, such as availability, reliability, robustness, safety, security, and survivability? Is resilience a component of some or all of these quality attributes, a superset of them, or something else? If we are to ensure that systems are resilient, we must first know the answer to these questions and understand exactly what system resilience is.
As part of work on the development of resilience requirements for cyber-physical systems, I recently completed a literature study of existing standards and other documents related to resilience. My review revealed that the term resilience is typically used informally as though its meaning were obvious. In those cases where it was defined, it has been given similar, but somewhat inconsistent, meanings.
Another issue I found was that the term resilience is used in two very different senses. The scope of this blog post, the first in a two-part series, focuses on system resilience and not organizational resilience, which has a much larger scope. Organizational resilience is primarily concerned with business continuity and includes the management of people, information, technology, and facilities. For more information on organizational resilience (with an emphasis on process and cybersecurity), see the CERT Resilience Management Model (CERT-RMM).
What Makes a System Resilient?
Basically, a system is resilient if it continues to carry out its mission in the face of adversity (i.e., if it provides required capabilities despite excessive stresses that can cause disruptions). Being resilient is important because no matter how well a system is engineered, reality will sooner or later conspire to disrupt the system. Residual defects in the software or hardware will eventually cause the system to fail to correctly perform a required function or cause it to fail to meet one or more of its quality requirements (e.g., availability, capacity, interoperability, performance, reliability, robustness, safety, security, and usability). The lack or failure of a safeguard will enable an accident to occur. An unknown or uncorrected security vulnerability will enable an attacker to compromise the system. An external environmental condition (e.g., loss of electrical supply or excessive temperature) will disrupt service.
Due to these inevitable disruptions, availability and reliability by themselves are insufficient, and thus a system must also be resilient. It must resist adversity and provide continuity of service, possibly under a degraded mode of operation, despite disturbances due to adverse events and conditions. It must also recover rapidly from any harm that those disruptions might have caused. As in the old Timex commercial, a resilient system "can take a licking and keep on ticking."
However, system resilience is more complex than the preceding explanation implies. System resilience is not a simple Boolean function (i.e., a system is not merely resilient or not resilient). No system is 100 percent resilient to all adverse events or conditions. Resilience is always a matter of degree. System resilience is typically not measurable on a single ordinal scale. In other words, it might not make sense to say that system A is more resilient than system B.
To fully understand resilience, it must be decomposed into its component parts. To exhibit resilience, a system must incorporate controls that detect adverse events and conditions, respond appropriately to these disturbances, and rapidly recover afterward. Because resilience assumes that adverse events and conditions will occur, controls that prevent adversities are outside of the scope of resilience.
Some resilience controls support detection, while other controls support response or recovery. A system may therefore be resilient in some ways, but not in others. System A might be the most resilient in terms of detecting certain adverse events, whereas system B might be the most resilient in terms of responding to other adverse events. Conversely, system C might be the most resilient in terms of recovering from a specific type of harm caused by certain adverse events.
It is important to understand the scope of what it means for a system to resist adversity:
- What critical capabilities/services must the system continue to provide despite disruptions?
- What types of adversities can disrupt the delivery of these critical capabilities (i.e., what adverse events and conditions must the system be able to tolerate)?
- What are the types and levels of harm to what assets that can cause these disruptions?
The preceding points lead to a more detailed and nuanced definition of system resilience:
A system is resilient to the degree to which it rapidly and effectively protects its critical capabilities from disruption caused by adverse events and conditions.
Implicit in the preceding definition is the idea that adverse events and conditions will occur. System resilience is about what the system does when these potentially disruptive events occur and conditions exist. Does the system detect these events and conditions? Does the system properly respond to them once they are detected? Does the system properly recover afterward?
Some organizations [MITRE 2019] include the avoidance of adverse events and conditions within system resilience. However, this is misleading and inappropriate as avoidance falls outside of the definition of system resilience. Avoiding or preventing adversities does not make a system more resilient. Rather, avoidance decreases the need for resilience because systems would not need to be resilient if adversities never occurred.
Figure 1 illustrates the relationships between the key concepts in the preceding definition of system resilience. A resilient system protects its critical capabilities (and associated assets) from harm by using protective resilience techniques to passively resist adverse events and conditions or actively detect these adversities, respond to them, and recover from the harm they cause. As we shall see in the second post in this series, each of these adverse events and conditions is associated with one of the following subordinate quality characteristics: robustness, safety, cybersecurity (including anti-tamper), military survivability, capacity, longevity, and interoperability.
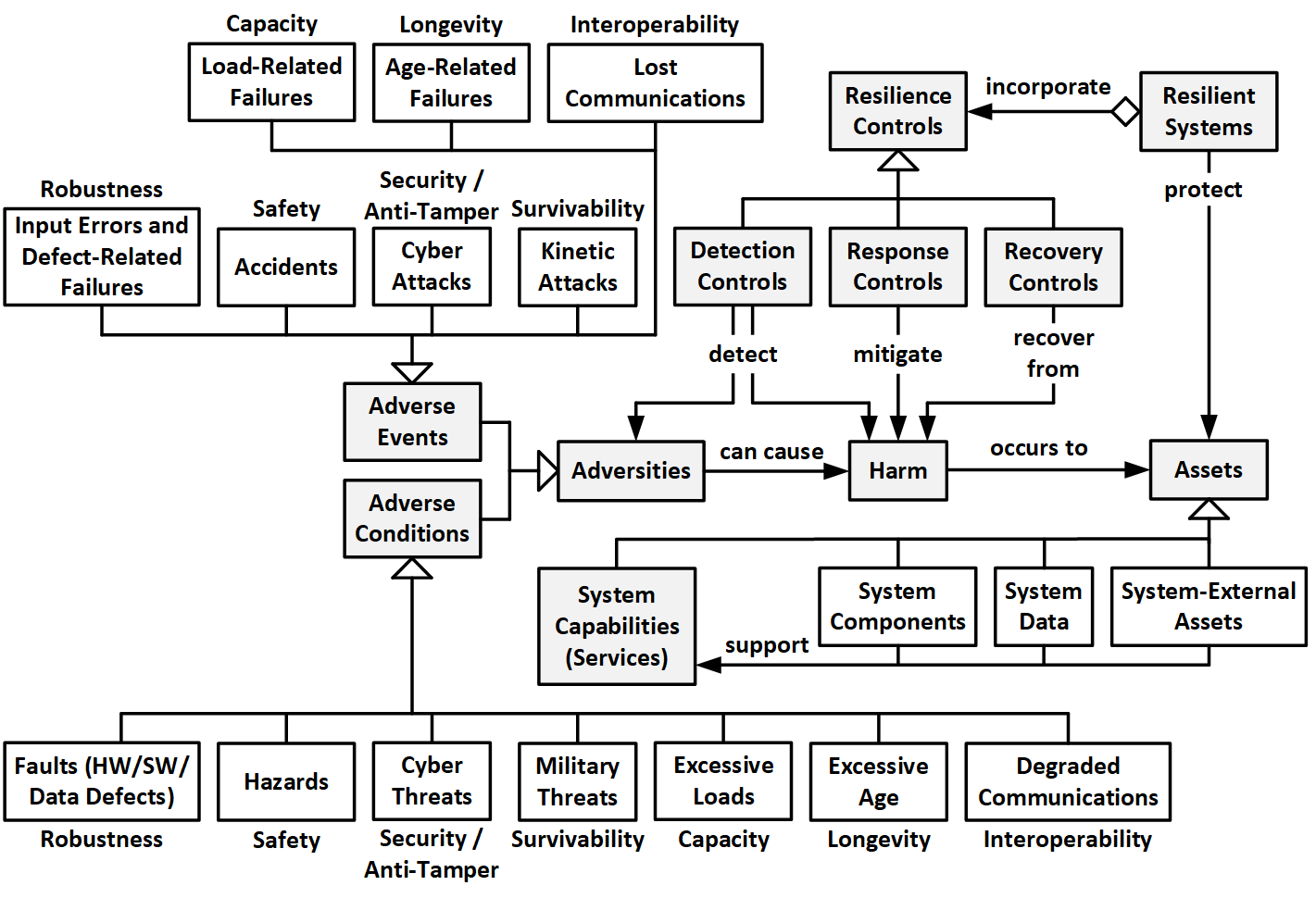
Figure 1: Key Concepts in the Definition of System Resilience
Figure 2 shows a notional timeline of how an adverse event might be managed by the ordered application of resilience controls to return a system to normal operations.
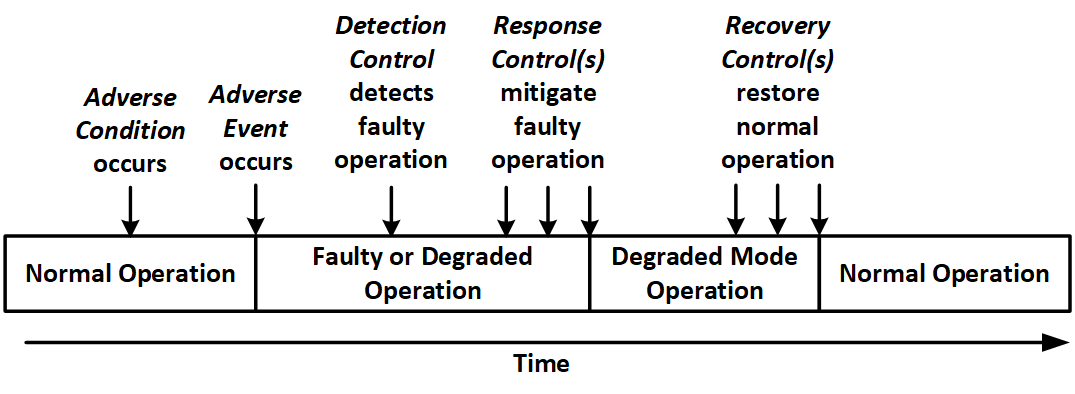
Figure 2: Example Resilience Timeline
To understand the full scope and complexity of system resilience, it is important to understand the meanings of the key words italicized in the preceding definition and how they are related in the preceding figure.
Protection consists of the following four functions:
- Resistance is the system's ability to passively prevent or minimize harm from occurring during the adverse event or condition. Resilience techniques for passive resistance include a modular architecture that prevents failure propagation between modules, a lack of single points of failure, and the shielding of electrical equipment, computers, and networks from electromagnetic pulses (EMP).
- Detection is the system's ability to actively detect (via detection techniques):
- Loss or degradation of critical capabilities
- Harm to assets needed to implement critical capabilities
- Adverse events and conditions that can cause harm critical capabilities or related assets
- Reaction is the system's ability to actively react to the occurrence of an ongoing adverse event or respond to the existence of an adverse condition (whereby the reaction is implemented by reaction techniques). On detecting an adversity, a system might stop or avoid the adverse event, eliminate the adverse condition, and thereby eliminate or minimize further harm. Reaction techniques include employing exception handling, degraded modes of operation, and redundancy with voting and
- Recovery is the system's ability to actively recover from harm after the adverse event is over (whereby recovery is implemented by recovery techniques). Recovery can be complete in the sense that the system is returned to full operational status with all damaged/destroyed assets having been repaired or replaced. Recovery can also be partial (e.g., full service is restored using redundant resources without replacement/repair) or minimal (e.g., degraded mode operations providing only limited services). Recovery might also include the system evolving or adapting (e.g., via reconfiguring itself) to avoid future occurrences of the adverse events or conditions.
System Capabilities are the critical services that the system must continue to provide despite disruptions caused by adversities.
Assets are valuable items that must be protected from harm caused by adverse events and conditions because they implement the system's critical capabilities. It is often impossible to completely prevent harm to all assets under all adverse events and conditions. Assets are therefore typically prioritized so that detection, reaction, and recovery concentrate on protecting the most important assets first. Assets relevant to resilience include the following:
- System Components: the system's component subsystems, hardware, software (e.g., applications, infrastructure, operating systems, and firmware), networks (e.g., devices, radios, and cabling), and facilities
- System Data: the data that the system stores, produces, and manipulates
- System-External Assets: any system-external assets (e.g., people, property, the environment, funds, and reputation) for which the system is responsible for protecting from harm
Harm to these assets include the following:
- Harm to System Capabilities: the complete or partial loss of service and theft of service
- Harm to System Components: the destruction of, damage to, theft of, or unauthorized reverse engineering of hardware or software
- Harm to Data: the loss of access (availability violations), corruption (integrity violations), unauthorized disclosure (confidentiality and anonymity violations), repudiation of transactions (non-repudiation violations), and reverse engineering of critical program information (CPI) (anti-tamper violations)
- Harm to System-External Assets: the loss of funds, loss of reputation, loss of business, and environmental damage or destruction
Adverse events are events that due to their stressful can disrupt critical capabilities by causing harm to associated assets. These adverse events (with their associated quality attributes) include the occurrence of the following:
- Adverse environmental events, such as loss of system-external electrical power as well as natural disasters such as earthquakes or wildfires (Robustness, specifically environmental tolerance)
- Input errors, such as operator or user error (Robustness, specifically error tolerance)
- Externally-visible failures to meet requirements (Robustness, specifically failure tolerance)
- Accidents and near misses (Safety)
- Cybersecurity/tampering attacks (Cybersecurity and Anti-Tamper)
- Physical attacks by terrorists or adversarial military forces (Survivability)
- Load spikes and failures due to excessive loads (Capacity)
- Failures caused by excessive age and wear (Longevity)
- Loss of communications (Interoperability)
Adverse conditions are conditions that due to their stressful nature can disrupt or lead to the disruption of critical capabilities. These adverse conditions include the existence of the following:
- Adverse environmental conditions, such as excessive temperatures and severe weather (Robustness, specifically environmental tolerance)
- System-internal faults such as hardware and software defects (Robustness, specifically fault tolerance)
- Safety hazards (Safety)
- Cybersecurity threats and vulnerabilities (Cybersecurity and Anti-Tamper)
- Military threats and vulnerabilities (Survivability)
- Excessive loads (Capacity)
- Excessive age and wear (Longevity)
- Degraded communications (Interoperability)
Note that anti-tamper (AT) is a special case that, at first glance, might appear to be unrelated to resilience. The goal of AT is to prevent an adversary from reverse-engineering critical program information (CPI) such as classified software. Anti-tamper experts typically assume that an adversary will obtain physical possession of the system containing the CPI to be reverse engineered in which case, ensuring that the system continues to function despite tampering would be irrelevant. However, tampering can also be attempted remotely (i.e., without first acquiring possession of the system). In situations where the adversary does not have access, an AT countermeasure might be to detect an adversary's remote attempt to access and copy the CPI and then respond by zeroizing the CPI, at which point the system would no longer be operational. Thus, remote tampering does have resilience ramifications.
Wrapping Up and Looking Ahead
This first post on system resilience provides a detailed and nuanced definition of the system resilience quality attribute. In the second post in this series, I will explain how this definition clarifies how system resilience relates to other closely-related quality attributes.
Additional Resources
Read the second post in this series on system resilience, How System Resilience Relates to Other Quality Attributes.
Read the third post in this series on system resilience, Engineering System Requirements.
[Caralli et al. 2016] Richard A. Caralli, Julia H. Allen, David W. White, Lisa R. Young, Nader Mehravari, Pamela D. Curtis, CERT® Resilience Management Model, Version 1.2, Resilient Technical Solution Engineering, SEI, February 2016.
[Firesmith 2003] Donald G. Firesmith, Common Concepts Underlying Safety, Security, and Survivability Engineering, Technical Note CMU/SEI-2003-TN-033, Software Engineering Institute, Pittsburgh, Pennsylvania, December 2003, 75 pages.
[ISO/IEC 25010:2011] Systems and Software Engineering -- Systems and Software Quality Requirements and Evaluation (SQuaRE) -- System and Software Quality Models
[ISO/IEC 15026-1:2013] Systems and software engineering -- Systems and software assurance -- Part 1: Concepts and vocabulary
[ISO/IEC/IEEE 24765:2017] Systems and software engineering -- Vocabulary
[MITRE 2019] John S. Brtis, Michael A. McEvilley, System Engineering for Resilience, MITRE, July 2019
Written By

More By The Author
More In Cybersecurity Engineering
PUBLISHED IN
Cybersecurity EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cybersecurity Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed