Deep Learning: Going Deeper toward Meaningful Patterns in Complex Data

PUBLISHED IN
Artificial Intelligence EngineeringIn a previous blog post, we addressed how machine learning is becoming ever more useful in cybersecurity and introduced some basic terms, techniques, and workflows that are essential for those who work in machine learning. Although traditional machine learning methods are already successful for many problems, their success often depends on choosing and extracting the right features from a dataset, which can be hard for complex data. For instance, what kinds of features might be useful, or possible to extract, in all the photographs on Google Images, all the tweets on Twitter, all the sounds of a spoken language, or all the positions in the board game Go? This post introduces deep learning, a popular and quickly-growing subfield of machine learning that has had great success on problems about these datasets, and on many other problems where picking the right features for the job is hard or impossible.
Complexity out of simplicity
A mathematical description of a dataset, with certain properties that can be adjusted to make the description more accurately represent the data, is called a model. All machine learning techniques have the goal of finding the best model, where the meaning of "best" can vary by context (easiest to understand, most accurate representation, or least likely to make costly mistakes, to name a few). Observable characteristics in the data, which can be given as input to a model, are called features, and a model's ability to perform well always depends on finding features that represent the data well.
Deep learning refers to a family of machine learning techniques whose models extract important features by iteratively transforming the data, "going deeper" toward meaningful patterns in the dataset with each transformation. Unlike traditional machine learning methods, in which the creator of the model has to choose and encode features ahead of time, deep learning enables a model to automatically learn features that matter. In this way, a deep learning model learns a representation of the dataset, making deep learning part of the larger field of representation learning.
This post focuses on a subset of deep learning models that are popular in today's research: artificial neural networks. An artificial neural network, or just "neural network," is a mathematical function, loosely modeled after the human brain, that chains together a great number of simple transformations to perform a complex transformation. Each simple transformation is done by an artificial neuron, or just "neuron," which does the following:
- Receive a list of numbers as input.
- Multiply each number in the list by another number, called a weight. Each number in the list gets its own weight, and each neuron has its own set of weights.
- Add up all of the results from (2) to get a single number.
- Apply a non-linear function, called an activation function, to the result of (3). One common choice of this function is the rectified linear unit, which keeps the number the same if it's 0 or greater, and turns the number into 0 if it's less than 0.
This is a severe oversimplification of the way that a real biological neuron in the human brain works.
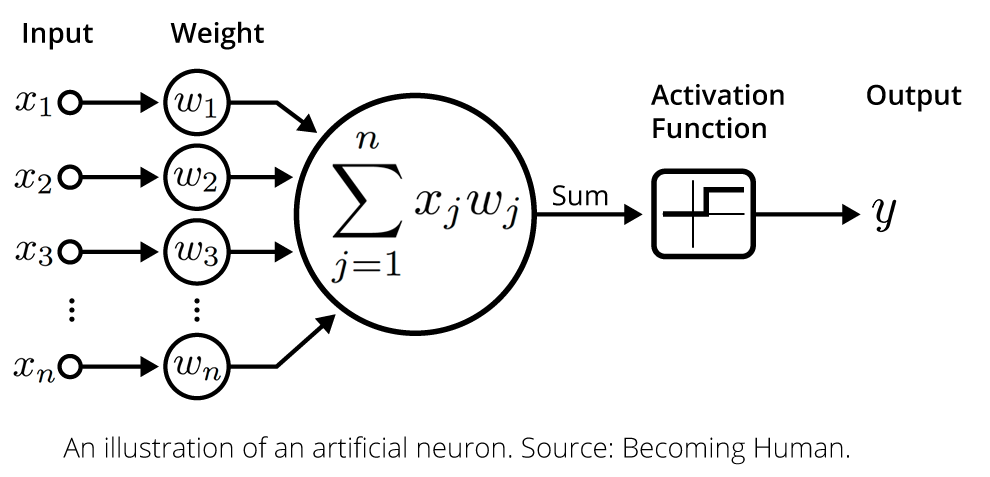
An illustration of an artificial neuron. Source: Becoming Human.
When you chain a huge number of artificial neurons together, feeding the output of hundreds of neurons as input to hundreds of other neurons, over and over, you get an artificial neural network. Truly giant networks are common: one popular network, AlexNet, has 650,000 neurons and 60 million weights. A multitude of simple calculations combine to create a calculation that is far from simple. For example, AlexNet, which solves the problem of image recognition, takes a photograph as input and attempts to output an English-language label that describes the subject of that photograph, such as "cockroach," "motor scooter," or "mushroom." Both the input and the output are encoded in a way that neurons can compute: the photograph is represented by the list of red, green, and blue intensity values from 0 to 255 in every pixel, and the neural network mathematically converts this into a number from 1 to 21,841, the number of labels that have been defined in an image-label dataset.
Getting it Right
Once a neural network model's structure has been decided by choosing which neurons connect to which other neurons, the properties that can be adjusted in the model are its weights, and finding the right weights is key for the accuracy of its representation. For example, you can model the total cost of a length of yarn with a tiny neural network made of a single neuron:
Total cost (output) = weight * desired length (input)
Here, if the weight is 0 or negative, you will have either an incorrect model or an unusually generous craft store pricing policy. The most accurate model will have weight equal to the price per yard of yarn. To have a good computational model, it is crucial to find the weights that lead to the most accurate results.
How are the correct weights found? Especially when your computational model has thousands of neurons and millions of weights, it is not easy to reason about what the right weights should be--you could just ask the store how much each yard of yarn costs, but there is no equivalent query to make for image recognition. Instead, we use a data-driven approach, relying on experience in the form of data--sample inputs and correct answers--to tell us how correct our model is. A simple procedure to find good weights in any neural network, no matter how large, boils down to this:
- Set all the weights to small random numbers.
- Select a random data point input, feed it to the network, and observe the network's output.
- Compare the network's output to the known correct answer.
- Adjust all the weights slightly, so that if you give that input to the network again, the output will be slightly closer to the correct answer.
- Loop (2)-(4) until the network's outputs are close enough to the correct answers, or until the network's outputs don't appear to be changing.
This procedure is called training, and the data used during training is called the training dataset. To get a feel for how training helps a neural network improve its predictions, see this interactive demo.
In practice, deep learning models often require millions of rounds of training, which can take anywhere from hours to weeks to complete, depending on the number of weights in the network and the difficulty of the task. Similarly, a huge amount of training data is usually necessary to get good performance, because it is important that the training data contains all of the details, nuances, structural patterns, and sources of error that could be present in any conceivable input. For example, for AlexNet to be able to recognize photos of cockroaches that are taken from a variety of angles, it needs to be shown images from those angles during training. Depending on the task, this could contain from thousands to millions of data points, occupying gigabytes or terabytes of storage.
Training is computationally-intensive enough that it can often only be done on tractable timescales if graphics processing unit (GPU) hardware is dedicated to the task. GPUs are extremely fast at performing the kinds of calculations necessary for training, but it is only relatively recently, since about 2007 when Nvidia released the GPU development toolkit CUDA, that GPUs have been wieldy for use by non-specialists. Soon after, deep learning became viable for wide study and research, and since then, deep learning has become an immensely popular experimental approach for problems in many fields with an abundance of training data. New hardware specifically designed for deep learning, called tensor processing units (TPUs), are still emerging, and leading to even greater computational improvements.
Learning What Cannot be Designed
In spite of the need for heroic computational resources and vast stores of data, the major strength of deep learning lies in the fact that humans don't need to figure out a way to convey complicated knowledge about the structure of their data to the computer. For example, human researchers never need to tell their computers that most cockroaches have six legs connected to a body--they need only show the computer thousands of accurately-labeled images of cockroaches, and thousands of accurately-labeled images of things that are not cockroaches. The network may then learn that images of cockroaches have six linear regions, bent in the middle, connected to an elliptical region. Deep learning reduces the need for challenging feature engineering, the methods used to extract useful information from data, that can lead to significant difficulties when applying more traditional statistics or machine-learning techniques.
As another example, the tools that your email client uses to determine whether an email is spam are powered by machine learning. Traditionally, some of the features that these systems use are the number of times that each word appears in an email, the total number of words, or the number of times that common, meaningful suffixes appear, and researchers need to create programs that can extract these features from an email before they are ready to be given to any algorithms. In a system powered purely by deep learning, none of these features need to be extracted beforehand. Instead, researchers feed a neural network thousands of accurately-labeled email examples of both spam and non-spam, and the algorithm that extracts important features becomes encoded in the network's weights, through the iterative adjustment during training.
This freedom from feature engineering is both a blessing and a curse. It is still an open area of research to figure out why a neural network produces the outputs that it does, which is not only philosophically interesting, but critical during development, testing, and debugging. Since the feature extraction algorithm becomes hidden in a neural network's weights, it is almost always impossible to tell directly what features the neural network ends up using for its computation, and the debugging process is usually ad hoc. As in other fields, visualization is an informal, but useful way to develop intuition about why a model does what it does.
The advantage of deep learning's opaque route to feature extraction, however, is that it can be used on datasets that might have features that are hard to describe. Imagine how challenging it might be to represent important features, or even figure out what the important features are, in the dataset of all photographs on Google Images, or the dataset of all tweets on Twitter. Deep learning solutions have successfully managed to extract information from datasets like these and many other challenging, complex datasets from the real world.
Difficulties
There are a variety of challenges that deep learning researchers face. As in any data-driven approach, training datasets must be both large and representative of the data that will be presented to each model after it is finished being trained (commonly called "data in the wild"). Otherwise, their models will contain a bias, making predictions based on patterns in the dataset that are not relevant to the true meaning underlying the data.
For example, these researchers attempted to use traditional statistics techniques to identify malicious software. Their initial results appeared to be successful, but when they used their technique on a new dataset collected from a different source, they saw poor performance. They eventually concluded that in their original dataset, most of the non-malicious software examples came from the Windows operating system, so their model predicted that any file that wasn't a Windows file was malicious. Since deep learning models are not told which patterns to look for in the data, they may pick up on patterns that researchers didn't even know existed, so they may be especially susceptible to bias. Careful consideration is required to create a dataset that does not introduce bias to a model.
Additionally, deep learning models often make mistakes that can be hard to understand. Part of the reason for this problem is that it is hard to know for certain what features a deep learning model is identifying, as noted above. Furthermore, deep learning models are vulnerable to a family of attacks that "fool" the model into making incorrect predictions. In one example, images that appear to humans as noise (think: TV static) are predicted with high confidence as belonging to various classes in the image-label dataset (e.g. "robin" or "cheetah").
In another example, corrupting just one pixel of a photograph can result in a high-confidence prediction of a totally unrelated class, causing an image-recognition network to change its prediction from "airplane" to "dog." The fact that neural networks can make mistakes in unintuitive ways motivates the need for those who include neural networks in critical or attack-prone systems to think carefully about their decisions. A one-pixel difference must not allow a weapons guidance system to mistake a civilian residence for a military base.
The fact that mistakes have consequences, and that some mistakes are worse than others, necessitates a system that can admit its own uncertainty about a prediction. At least two cases can create a situation where uncertainty can arise and should be communicated: (1) if the network is presented with an ambiguous input, such as an image that might be a deer or might be a dog or (2) if the network is presented with an input that is different from any of the data it was given during training, such as an image of an airplane given to a network that was only ever trained on images of animals. These problems have both been addressed, with varying implementations and to varying degrees of success, but these solutions have yet to be accepted widely, and improving on these solutions is an active area of research.
Accomplishments and Current Work
Deep learning has demonstrated success on a world of hard problems, including:
- Image recognition: Identify objects in an image. AlexNet, mentioned above, was an early and popular success at this task. In the fall of 2017, the SEI participated in the IARPA Functional Map of the World Challenge, which is a variant of this problem that involves identifying the use of a patch of land (with labels such as "airport," "solar farm," and "military facility" that would be useful for national intelligence) from satellite photographs.
- Image segmentation: Given an image, determine the outline of all the objects in the image, and label the objects. Solving this problem has applications for self-driving vehicles, which need to be able to label objects in their field of view as "road" or "person," because only one of these can be traveled through safely. One successful implementation of road image segmentation is SegNet. Another application is medical imaging, predicting the location and shape of lesions in three-dimensional brain scans, implemented as DeepMedic. As long as you've got the data, there is no reason your images can't occupy more than 2 dimensions!
- Machine translation: Given a sentence in one language, translate it into another language. In 2016, Google released a deep-learning-based translation system that reduced errors by 60 percent when compared to their previous model.
- Playing games. The board game Go was long considered a significant challenge in artificial intelligence. In 2015, the computer Go program AlphaGo, powered in part by deep learning, beat a world champion human Go player.
In a future blog post, we will further describe the SEI's work in deep learning for defense, intelligence, and cybersecurity, including our participation in the IARPA Functional Map of the World Challenge, and our research into the effectiveness of deep learning for problems in cybersecurity.
The Wild West of Research
If you take anything away from this post, I hope it's this: that deep learning is a new and active enough field of research that knowledge is generated and communicated in nontraditional ways, by people you might not expect. It is important that those who work in industry or defense be aware of the following, because their competitors, opponents, and adversaries certainly are:
- The field is still figuring out what it is, and isn't, good at. While researchers have realized some success with deep learning in image recognition, other problem classes have yet to be explored. However, ample motivation to explore the problem space comes from companies and government agencies, who have problems, data, and cash to give to researchers. Often, this research is crowd-sourced through competitions, such as those hosted on the data science competition site Kaggle. These competitions create high-performance algorithms for the sponsoring organizations, offer fame and wealth to the winners, and advance knowledge for everyone in the field.
- There are few barriers to communication. New ideas in deep learning are discovered and communicated almost every day. These discoveries come from a great variety of people--some are long-established researchers in the field, publishing through traditional academic channels; some are less-renowned, publishing on blogs of major companies; and some are "just people," interested and curious hobbyists who discover something exciting and let people see their results on GitHub, publishing informally through blog posts. Instead of traditional peer review, credibility is encouraged by people downloading someone's code, running it, and commenting that it works or doesn't work. This contributes to a "Wild West" atmosphere of deep learning research.
- It pays to keep current. As in any field of research, success favors those with up-to-date knowledge on new problems and new techniques to solve them, access to computational resources, intuition, creativity, and wherewithal to experiment, and luck.
Additional Resources
If you're interested in deep learning and want to read an excellent tutorial, I highly recommend the notes for Stanford University's course, Convolutional Neural Networks for Visual Recognition. These notes provide motivation and intuition for the basic concepts necessary to understand deep learning, and they give enough attention to mathematical detail and rigor that they don't sweep very much under the rug.
A collection of interesting results in deep learning for cybersecurity research can be found here.
Written By

More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed