Prioritizing Malware Analysis

In early 2012, a backdoor Trojan malware named Flame was discovered in the wild. When fully deployed, Flame proved very hard for malware researchers to analyze. In December of that year, Wired magazine reported that before Flame had been unleashed, samples of the malware had been lurking, undiscovered, in repositories for at least two years. As Wired also reported, this was not an isolated event. Every day, major anti-virus companies and research organizations are inundated with new malware samples.
Although estimates vary, according to an article published in the October 2013 issue of IEEE Spectrum, approximately 150,000 new malware strains are released each day. Not enough manpower exists to manually address the sheer volume of new malware samples that arrive daily in analysts' queues. Malware analysts instead need an approach that allows them to sort out samples in a fundamental way so they can assign priority to the most malicious of binary files. This blog post describes research I am conducting with fellow researchers at the Carnegie Mellon University (CMU) Software Engineering Institute (SEI) and CMU's Robotics Institute. This research is aimed at developing an approach to prioritizing malware samples in an analyst's queue (allowing them to home in on the most destructive malware first) based on the file's execution behavior.
Existing Approaches to Prioritizing Malware Analysis
Before beginning work on developing an approach for prioritizing malware analysis, our team of researchers examined existing approaches and found very few. Most institutions in academia, government, and industry analyze malware by randomly selecting samples, ordering them alphabetically, or analyzing a binary file in response to a request for a specific file based on its MD5 , SHA-1, or SHA-2 cryptographic hash value.
Our team decided to take a systematic approach to malware analysis that takes incoming samples and analyze them using runtime analysis. At a high-level, this approach collects and categorizes salient features. Using a clustering algorithm, our approach then ideally prioritizes the malware sample appropriately in an analyst's queue based on their description of the type of malware they want to analyze upon its arrival to their repository.
A key idea in our approach involved the use of dynamic analysis to measure the maliciousness of a malware sample based on its execution behavior. The assumption is that all malware samples have certain malicious events they must perform to carry out nefarious deeds. The implementation of these deeds is captured at runtime and may prove to be useful assessment characteristics.
Salient and Inferred Features
When we initially began this research, we extracted more than two dozen features that were a mix of
- actual runtime data that could be easily identified as suspicious. An example is modification of a registry key such as Windows\CurrentVersion\Run.
- inferred features that are derived by analyzing the details of one or more actual runtime suspicious data. An example is a malware setting itself up to start at system reboot by analyzing the details of the Windows\CurrentVersion\Run registry key modification and concluding the edit was the malware placing its own file system path in this key assuring it will execute on reboot.
It's important to note that malware doesn't typically commit all of its nefarious deeds with just one running process. In examining features, we also created malware infection trees to gain a better understanding of the processes and files created by the malware. The paper, "Building Malware Infection Trees," which I co-authored, allowed us to view the malware sample as "a directed tree structure" (see Figure 1 below) with each node representing a file or process that the malware had created and each edge representing file creation, process creation, self-replication or dynamic code injection behavior.
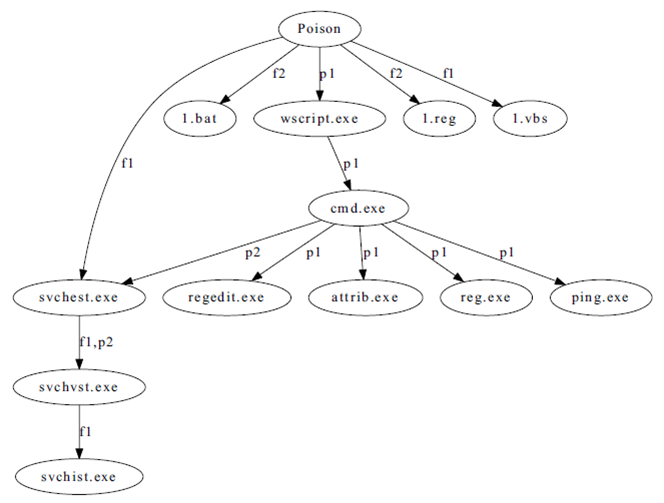
Figure 1. A Malware Infection Tree for Poison Malware.
Our research focused on the following three areas of suspicious behavior, all of these behaviors were recorded for the executing malware process and any related processes in its malware infection tree. We assume these behaviors being performed by a member of the malware infection tree can lead to suspicious behaviors usable in assessing the malware sample:
- File systems. We looked at the typical open, write, create, move, and delete file operations. These are typical behaviors for any executable, but when performed by malware they can occur in greater numbers or target specific files as part of a broader malicious behavior. We also examined instances of self-replication where malware copies itself into a new file or copies itself into an existing file as well as a piece of malware deleting itself from the system. We also considered cases where a child process in the malware infection tree deleted the static file image of an ancestor process which was deemed a possible attempt to avoid detection.
- Networks. We examined domain name service (DNS) queries and reverse DNS (rDNS) queries. Specifically, we searched for high occurrences of DNS and rDNS requests, especially failed requests which indicate that malware may be testing a set of potentially active IP addresses to connect with a command-and-control server or some other malicious server.
We also considered multiple failed Transmission Control Protocol (TCP) connection attempts, specifically cases where a URL was DNS queried multiples times and then, when an attempt was made to connect to the IP address, the attempt failed. This scenario indicates that the malware might be harvesting IP addresses through DNS requests, but the IP addresses it harvests are servers that have not been activated or have been taken down, blocked, removed, or blacklisted. A piece of malware sometimes keeps repeating this action until it connects with an IP address or times out. We also identified use of non-typical network protocols.
- Processes. We primarily looked at whether the malware created a completely new process, deleted an already running process, or started a new process thread. When a malware sample deleted a process, we checked to see if the process that was being deleted belonged to a known piece of anti-malware software. If that was the case, we inferred that the malware was actually trying to disable the system's security measures to ensure its safety and longevity.
Our analysis of processes also included dynamic code injection where the malware process running on a system identifies already existing processes that are likely to be running on any version of the target system. Specifically, we looked at several Windows platform standard processes that start at runtime, such as svchost.exe, winlogon.exe, and taskhost.exe.
In dynamic code injection, the malware process chooses an already running process and writes malicious commands into the process's memory. Next, the malware creates a new thread that will execute the malicious instructions that have just been written to its memory. These steps result in the modified process behaving in non-typical ways. With dynamic code injection, the malware actually delegates malicious acts to other process so that that the system will detect the other process as doing something suspicious and not the original malware that is running on the system. We also examined whether, during our runtime analysis, the malware tried to modify the registry key Windows\CurrentVersion\Run. A modification of this registry key is obviously something that we want to know about because it can be an indicator of malicious behavior.
A Technical Dive into Our Approach
Once we determined the features we wanted to look at, we turned our attention to creating a training set. To do so, our team compiled a set of malware samples classified as advanced persistent threats (APTs), botnets, and Trojans. We also included known malware that was ranked in the Top 5 most dangerous and most persistent in the wild in the past five years, according to Kaspersky's securelist.org website. We submitted, executed, and analyzed each sample in our runtime analysis framework and extracted our chosen features.
Once we created our training set, we assembled 11,000 malware samples that we clustered based on the training set. The training set allowed us to gain an initial understanding about what our algorithms tell us about how we could prioritize the malware. We examined execution behavior at the user and kernel levels for a three-minute, run-time analysis.
We then determined, for the whole set, if behaviors were identified mostly from user- or kernel-level collected data. Next, we created a set of characteristics from the most pervasive observed execution behaviors and repeated our experiment using a larger mixed malware sample set and clustered results based on our set of characteristics. At the end of analysis we collected the feature sets for our training sets and our test set of 11,000 samples, and we submitted them for analysis with various machine learning algorithms to determine which one is best for prioritizing malware samples based on our features.
Collaborations
Dr. Jeff Schneider, a researcher at the Robotics Institute in CMU's School of Computer Science and an expert on classification and clustering, agreed to analyze our feature sets and create a classifier to prioritize malware samples. We are also working with software engineers within the CERT Division's Digital Intelligence and Investigations Directorate Software Engineering group who wrote code for us including the feature extraction code.
Next Steps
The goal of our research was to allow analysts greater efficiency in establishing a priority queue for malware analysis. These priorities can vary based on whether the malware analyst works in the financial industry and is interested in Distributed Denial of Service (DDoS) attacks, botnets, or Trojans, or whether the analyst works in the DoD's cyber command and is interested in APTs and protecting national assets.
If our approach works as planned, we will accelerate efforts to formalize an automated prioritization system using our established set of salient and inferred features that could be integrated into current analysis frameworks using as input a live continuous malware feed.
We welcome your feedback on our approach in the comments section below.
Additional Resources
To listen to the CERT Podcast, Characterizing and Prioritizing Malicious Code with Jose Morales and Julia Allen, please click here.
To read the paper, "Building Malware Infection Trees," by Jose Andre Morales, Michael Main, Weiliang Luo. Shouhuai Xu, and Ravi Sandhu, please visit
https://ieeexplore.ieee.org/Xplore/cookiedetectresponse.jsp
To read about other malware research initiatives at the SEI, please visit/blog/?tag=malware
Written By

More By The Author
Reviewing Formalized DevOps Assessment Findings and Crafting Recommendations: Sixth in a Series
• By Jose A. Morales
More In CERT/CC Vulnerabilities
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In CERT/CC Vulnerabilities
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed