Domain Blocking: The Problem of a Googol of Domains
Hi all, this is Jonathan Spring. I've written a bit about some challenges with blocklisting, such as about the dynamics of domain take-down: why e-crime pays (domains are so cheap it almost always pays) and comparisons among blocklists (they are largely disjoint, calling into question comprehensiveness).
Perhaps because I'm too busy planning FloCon, it seems I have never written about why domain names are so cheap and why blocklists have such a hard time being comprehensive. It's a basic tenet in economics; the larger the supply of a commodity, the lower the price. Just how many domain names are there? Per the RFC, the maximum size of a label in a Domain Name System (DNS) zone is 63 bytes, which is 63 ASCII characters. In www.example.com, "www" "example" and "com" are all labels.
There are lots of places to register a DNS name, where you get a label in the zone. There are common generic top-level domains (TLDs), such as .com and uncommon country-code TLDs such as .su for the Soviet Union. There are pseudo-TLDs that are not directly responsible to the Internet Corporation for Assigned Names and Numbers (ICANN) but still effectively provide registrations, such as dynamic DNS providers and Central-NIC domains such as .com.de. It's not worth counting them closely, as I'll demonstrate shortly.
How many labels are available in one zone? That is, what is the potential supply? Ignoring branding issues where a company's name is going to severely limit the supply of relevant names, we're asking what the total supply of usable labels is if you are, for example, writing a botnet and don't need the names to be pretty or memorable. You just need them to get around a blocklist. What is the supply of those kinds of names?
Well, as the RFC tells us, there are 63 available characters. The permissible characters are any ASCII letter a to z, any number 0 to 9, or a dash (-). The dash cannot be the first or the last character, and although DNS should preserve case, registration of domains is case insensitive so we don't have to worry about the difference between "A" and "a."
So for the first and the last characters, there are 36 possible characters, and for everything else there are 37. Thus we can calculate all the possible 5-character labels there are by looking at how many options one has for each character in the label. For a 5-character label, there are 36 * 37 * 37 * 37 * 36, or 362 * 373 labels, or 65,646,288. For longer labels, just add the appropriate number of 37's into the equation.
To calculate the total possible labels, we just need to sum how many possible labels there are for each length label between 1 and 63, since 63 is the max label length.
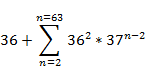
This calculation produces a very large number, about 1.65 * 1097. Precisely, it is this number: 164667415374710866869114679441923833937126081914296567454440
36616780226089691664715576322299094132.
But it makes no matter. Let's just call it 1097 and round off most of it, because 1097 is a quadrillion times the number of atoms estimated to exist in the universe. Since there are roughly a thousand locations in which you can register a name, there are a full googol (10100) of possible effective second-level domains you could go register right now. This number is incomprehensibly large.
This is the problem both for blocklists and for economics. If the supply of a commodity is one googol, no wonder the cost is nearly free. The price falls as the supply increases. Likewise, no wonder blocklisting fails. Computers can hold in memory a few billion (that is, gigabytes) of names to check, maybe. But the adversary can always just move to another one. A googol less a few billion names is still near enough to one googol as to make no matter.
For comparison, the total number of IPv4 addresses is around 4 billion, or 4 * 109. Security folks often complain about the difficulty of routing and maintaining block lists for IPv6, which has 2128 or 3 * 1038 addresses. We can handle that okay with specialized software. Domains could break any specialized software if we had to list all possible strings. The number of potential domains makes the number of IPv6 addresses look miniscule.
What does all this mean? Foremost, I think it indicates that using primarily reactive blocklisting is not sustainable. What to do about that is another matter. Allowlisting and graylisting need to be considered as well as more sophisticated predictive techniques and more detailed network reputation data-limiting network actions. There are still plenty of problems besides this over-supply, but if blocklists are infeasible, an organization has to seriously consider all options to supplement their defenses.
More By The Author
CERT/CC Comments on Standards and Guidelines to Enhance Software Supply Chain Security
• By Jonathan Spring
Adversarial ML Threat Matrix: Adversarial Tactics, Techniques, and Common Knowledge of Machine Learning
• By Jonathan Spring
More In CERT/CC Vulnerabilities
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In CERT/CC Vulnerabilities
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed