Vulnerability Coordination and Concurrency Modeling

Hi, it's Allen. In addition to building fuzzers to find vulnerabilities (and thinking about adding some concurrency features to BFF in the process), I've been doing some work in the area of cybersecurity information sharing and the ways it can succeed or fail. In both my vulnerability discovery and cybersecurity information sharing work, I've found that I often learn the most by examining the failures -- in part because the successes are often just cases that could have failed, but didn't.
In this blog post I focus on an area of cybersecurity information sharing that's considerably less well understood than incident reporting, malware analysis, or indicator sharing. I'm talking about coordinated vulnerability disclosure and why it's hard.
One of the first things you notice when you start thinking about vulnerability coordination is that there are more ways for it to go wrong than there are for it to go right. But we'll get to that. It all starts with a vulnerability (vul). Let's leave aside how that vul got there. We don't really care. It's simply a given for our model.
Oh, right, we haven't talked about models yet. Well, in this post I'm using Petri nets to demonstrate the coordination process. Petri nets are a way of modeling systems that operate with concurrency, and concurrency is often mentioned as one of the most challenging aspects of modern system engineering.
If you've never seen a Petri net before, here is a quick introduction:
- Petri nets model distributed processes as a network of nodes and arcs.
- Nodes can be either places (circles), or transitions (boxes).
- Arcs (arrows) connect places to transitions and vice versa. Places can't connect to places, and transitions can't connect to transitions.
- Places can hold tokens, which mark the state of a process.
- Transitions represent events that change the state of the process. A transition can fire when all the places immediately upstream of it are occupied by tokens (i.e., when it is enabled). When a transition fires, it consumes tokens from its inputs and places tokens in its outputs.
So back to our modeling. We can start with a place that represents the existence of a vul. We'll also add a few transitions to show how this Petri net stuff works. Let's start with a simple model, in which a vul exists and the public finds out about it. The public might also find out about a fix at the same time.
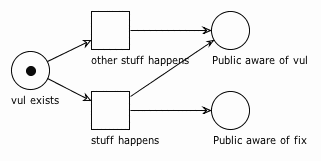
First, notice that there is a token in vul exists. That token represents our vul. From there, two transitions are enabled (ready to fire). If stuff happens, then the public will become aware of the vul and the fix at the same time -- desirable outcome.
However, if other stuff happens, we might wind up in a state where the public is aware of the vul but there is no available fix. This state also serves as a simple definition of a Zero Day Vulnerability. Sometimes that's what happens though, and it's still better than if neither transition fires and we never find out about the vul, right? But what about this "stuff" that happens? That's what we're going to cover next.
Start With a Vendor
In the next scenario, a vendor finds a vul, studies it, fixes it, and publishes both the fix and a document describing it. Here's what our updated Petri net looks like:
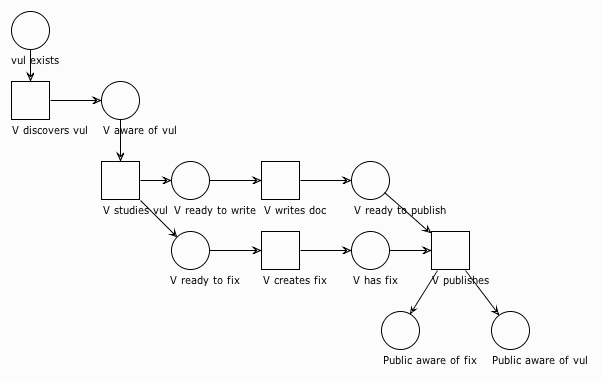
Notice that we start with a token in vul exists. That represents our vul, but the vendor doesn't know about it until the V discovers vul transition fires. Watching the simulation run ahead a bit, we see that we get concurrency when it comes to writing up the report and fixing the vul. Since it's usually easier to write about a vul than actually fix it, we show V writes doc firing first. (Although there's nothing that requires it to happen that way.)
And now we find ourselves waiting for the fix. The vendor usually won't publish until both conditions are satisfied: the document is ready to go AND the fix is ready. Let's assume that happens, and the vendor publishes. Now the public becomes aware of both the vul and the fix at the same time. Yay!
For simplicity I've left out the option for the vendor to publish either the doc or the fix independently of each other. I also omitted the possibility that the vendor just stops work on the vul fix entirely. A more robust model would need to accommodate those possibilities.
Add a Researcher
But that's not the end of our story. The vendor isn't the only game in town. There are other ways for vuls to be discovered and come to a vendor's attention. What if a researcher finds it first? Well, we need to update our model.
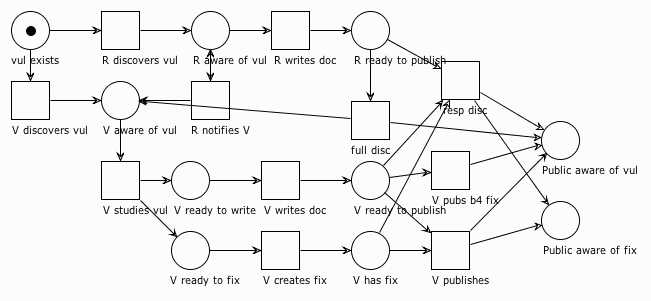
The researcher's basic flow is: Discover vul, write report, publish report. But there's a problem: if the researcher were to publish independent of the vendor, the public would find out about the vul at the same time as the vendor, which means there's no fix and possibly a long wait for it. This flow is basically the full disclosure scenario. But since we're modeling concurrency here, we can add something to gain some time back for the vendor.
In the diagram above, we've added an R notifies V transition earlier in the process. This transition allows for the vendor to start working through its processes while the researcher is preparing the public report. Also, we add a responsible disclosure (aka coordinated disclosure) transition that waits not only for the researcher to be ready, but for the vendor to be ready as well. When the responsible disclosure transition fires, the public will become aware of the vul and the fix at the same time.
Aside: Usage of the term "responsible disclosure" has been mostly supplanted by "coordinated disclosure" in the past few years. While that's a good thing because it removes the implied value judgement embodied in the word "responsible," I've chosen to use the term "responsible disclosure" here because (1) it is still in common use, and (2) it helps to avoid confusion with the coordination section below. However, rest assured that wherever I've used "responsible disclosure" in this post, you can substitute "coordinated disclosure" without loss of generality.
This diagram also highlights some of the possible failure modes of the disclosure process. Notice that the full disc transition is also highlighted. It can happen as soon as R is ready to publish, regardless of the vendor's readiness. If it fires before the vendor is ready, the public will become aware of the vul but not the fix (this is the Zero Day Vulnerability scenario mentioned earlier).
But there's also the possibility that the vendor publishes the doc and/or the fix independent of the researcher. This is certainly the vendor's prerogative. In practice, this is sometimes necessitated when the vendor becomes aware of active exploitation, or if the researcher abandons the disclosure process at any time prior to publishing. Researchers might abandon a vulnerability in coordination for a variety of reasons including higher priority tasks, frustration with the amount of time and effort required, or threatened litigation.
Mix In a Coordinator
So already we have a process in which there are three ways for the public to receive partial information and two ways for them to get the report and the fix simultaneously: (1) vendor publishes independently, or (2) all parties follow responsible disclosure. Because of the concurrency, there are many scenarios in which the researcher is ready to publish long before the vendor. The longer this situation persists, the greater the pressure for the researcher to either go it alone and publish or abandon the vul.
Sometimes researchers or vendors need additional assistance to bring a vul and its fix to the public's attention. This need might arise because the researcher is too overloaded with other tasks to shepherd the vul through a coordinated disclosure process, or perhaps the vendor is having a difficult time understanding the vul and wants an outside opinion. This situation is where a vulnerability coordinator might come into the story.
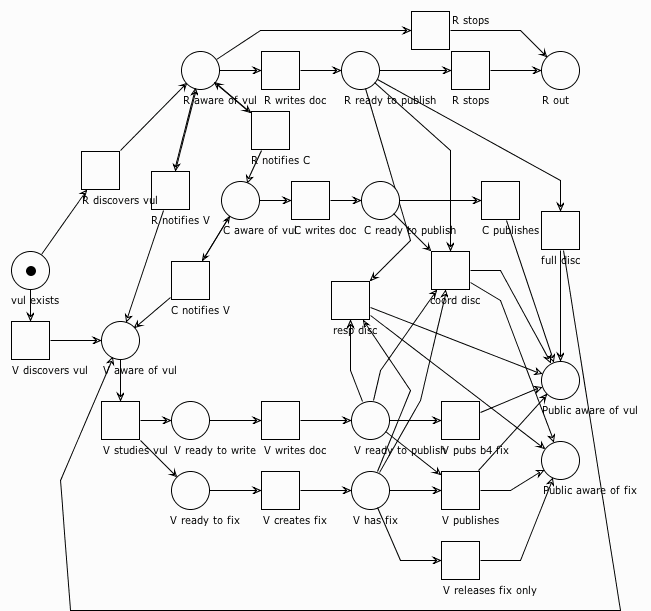
In the diagram above, we've inserted a vul coordinator (C) to the process demonstrate the optimal path where everyone publishes at once. Along the way, the researcher notifies the coordinator, the coordinator notifies the vendor, and all three parties continue with their respective processes. All the paths from our previous models still apply, but now we add four new paths:
- The coordinator publishes at the same time as the vendor and the researcher (coordinated disclosure). The public learns about the vul and the fix at the same time.
- The coordinator publishes with the vendor but does not wait for the researcher. The public learns about the vul and the fix at the same time.
- The coordinator publishes with the researcher but does not wait for vendor. The public learns about the vul, but has to wait for the vendor to publish a fix. This is increasingly rare for established vendors, but still happens often enough that it's not surprising to see a coordinated vulnerability report published without a vendor-supplied fix. Most often it occurs when a vendor has been non-responsive to either the initial report or status requests from either the coordinator or the researcher. Frequently the publication of the vulnerability report is sufficient to motivate the vendor to provide a fix soon thereafter.
- The coordinator publishes alone. This can happen when both the researcher and vendor appear to have abandoned the process prior to publication, but it's fairly rare.
Complicating Factors
The discussion above highlights just a few of the ways the vulnerability disclosure process can fail to deliver its most desirable outcome of simultaneous vul reports and fixes. In general those failures can arise from:
- The researcher publishes before the vendor is ready
- The coordinator publishes before the vendor is ready
- The vendor publishes before the fix is ready
- The vendor publishes the fix without an accompanying report
- The vendor or coordinator publishes before the researcher is ready
In the first three of these scenarios, information about the vul becomes public before an official fix is available. This is usually undesirable, but sometimes appropriate if users (individuals, organizations, and service providers) can deploy viable workarounds to reduce their exposure to the vul while they await the fix.
In scenario #4, we have the opposite problem of silent fixes. A vulnerability that is fixed without notice may not be deployed as readily as a fix whose existence is known.
Scenario #5 can discourage a researcher from working with the vendor or coordinator, resulting in reduced cooperation on future vulnerabilities.
In all five scenarios, there are many circumstances in which a scenario may be the most appropriate result of the disclosure process, even if it is sub-optimal to the ideal of simultaneous fix and report. Knowledge of active exploitation is a common reason for one party to release their information early. Discovery of a leak in a multi-party coordinated disclosure process can also prompt the other participants to release early.
Furthermore, because of the potentially complex interactions involved in even a two-party coordinated disclosure optimal outcomes can be difficult to achieve. This complexity can arise since at least one (and often both) of the parties involved are organizations with many individuals involved in dealing with product vulnerabilities, including researchers, developers, product security teams, incident response, public relations, and legal counsel.
Finally, as complex as the three-party diagram is, it still deals with only a single researcher, a single vendor, and a single coordinator. Here on the Vulnerability Analysis team, we often encounter vul reports that require the coordination of multiple vendors, sometimes involving multiple coordinator organizations as well. Such scenarios typically happen with infrastructure software and services like DNS, SSL, or SNMP, or with third-party libraries that find their way into many vendors' products.
But I think that's better left for a different post.
Conclusion
The CERT/CC Vulnerability Analysis team has participated in and observed all of these scenarios play out over the years with various researchers, vendors, coordinators and vulnerable products. It can be a messy process. We find it works best to start with a presumption of beneficence on the part of all involved parties until they demonstrate otherwise. It's also important to keep in mind that, as 20,000+ Google results told me while working on this post: concurrency is hard.
Acknowledgements
The diagrams in this post were created using the Workflow Petri Net Designer (WoPeD) from https://woped.dhbw-karlsruhe.de/
Written By

More By The Author
Prioritizing Vulnerability Response with a Stakeholder-Specific Vulnerability Categorization
• By Allen D. Householder
More In CERT/CC Vulnerabilities
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In CERT/CC Vulnerabilities
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed