Versioning with Git Tags and Conventional Commits

PUBLISHED IN
Cybersecurity EngineeringWhen performing software development, a basic practice is the versioning and version control of the software. In many models of development, such as DevSecOps, version control includes much more than the source code but also the infrastructure configuration, test suites, documentation and many more artifacts. Multiple DevSecOps maturity models consider version control a basic practice. This includes the OWASP DevSecOps Maturity Model as well as the SEI Platform Independent Model.
The dominant tool for performing version control of source code and other human readable files is git. This is the tool that backs popular source code management platforms, such as GitLab and GitHub. At its most basic use, git is excellent at incorporating changes and allowing movement to different versions or revisions of a project being tracked. However, one downside is the mechanism git uses to name the versions. Git versions or commit IDs are a SHA-1 hash. This problem is not unique to git. Many tools used for source control solve the problem of how to uniquely identify a set of changes from any other in a similar way. In mercurial, another source code management tool a changeset is identified by a 160-bit identifier.
This means to refer to a version in git, one may have to specify an ID such as 521747298a3790fde1710f3aa2d03b55020575aa (or the shorter but no less descriptive 52174729). This is not a good way for developers or users to refer to versions of software. Git understands this and so has tags that allow assignment of human readable names to these versions. This is an extra step after creating a commit message and ideally is based on the changes introduced in the commit. This is duplication of effort and a step that could be missed. This leads to the central question: How can we automate the assignment of versions (through tags)? This blog post explores my work on extending the conventional commit paradigm to enable automatic semantic versioning with git tags to streamline the development and deployment of software products. This automation is intended to save development time and prevent issues with manual versioning.
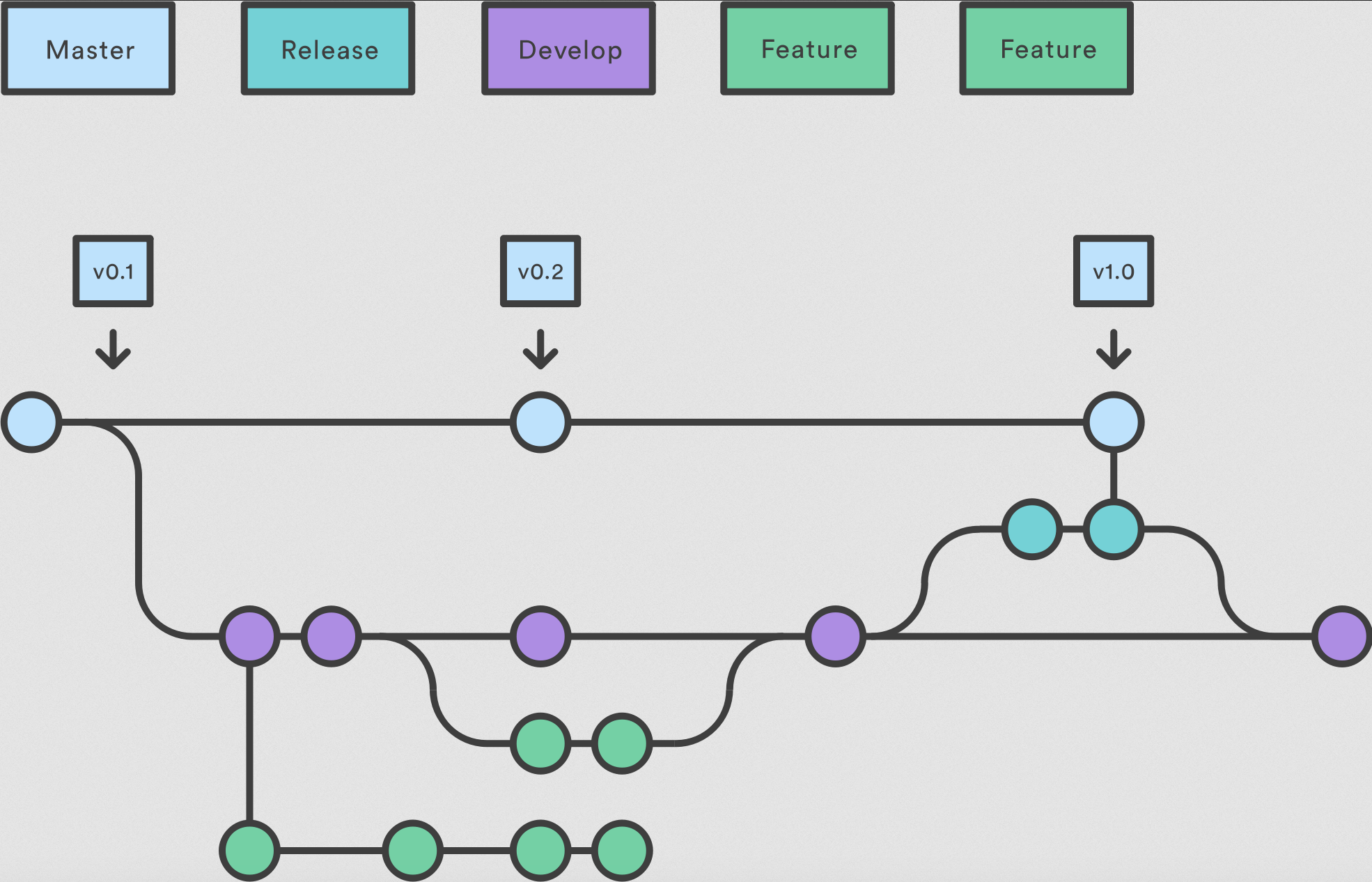
I have recently been working on a project where one template repository was reused in about 100 other repository pipelines. It was important to test and make sure nothing was going to break before pushing out changes on the default branch, which most of the other projects pointed to. However, with supporting so many users of the templates there was inevitably one repository that would break or use the script in a non-conventional way. In a few cases, we needed to revert changes on the branch to enable all repositories to pass their Continuous Integration (CI) checks again. In some cases, failing the CI pipeline would hamper development for the users because it was a requirement to pass the script checks in their CI pipelines before building and other stages. Consequently, some consumers would create a long-lived branch in the template repository I helped maintain. These long-lived branches are separate versions that do not get all of the same updates as the main line of development. These branches are created so that users did not get all the changes rolled out on the default branch right away. Long-lived branches can become stale when they don’t receive updates that have been made to the main line of development. These long-lived, stale branches made it difficult to clean up the repository without also possibly breaking CI pipelines. This became a problem because when reverting the repository to a previous state, I generally had to point to a reference, such as HEAD~3, or the hash of the previous commit before the breaking change was integrated into the default branch. This issue was exacerbated by the fact that the repository was not using git tags to denote new versions.
While there are some arguments for using the latest and greatest version of a new software library or module (often referred to as “live at head,”) this method of operating was not working for this project and user base. We needed better version control in the repository with a way to signal to users if a change would be breaking before they updated.
Conventional Commits
To get a handle on understanding the changes to the repository, the developers decided on adopting and enforcing conventional commits. The conventional commits specification offers rules for creating an explicit commit history on top of commit messages. Also, by breaking up a title and body, the impact of a commit can be more easily deduced from the message (assuming the author understood the change implications). The standard also ties to semantic versioning (more on that in a minute). Finally, by enforcing length requirements, the team hoped to avoid commit messages, such as fixed stuff, Working now, and the automated Updated .gitlab-ci.yml.
For conventional commits the following structure is imposed:
<type> [optional scope]: <description>
[optional body]
[optional footer(s)]
Where <type> is one of fix, feat, BREAKING CHANGE or others. For this project we decided on slightly different terms. The following regex defines the commit message requirements in the project that inspired this blog post:
^(feature|bugfix|refactor|build|major)\/ [a-z ]{20,}(\r\n?|\n)(\r\n?|\n)[a-zA-Z].{20,}$
An example of a conventional commit message is:
feature: Add a new post about git commits
The post explains how to use conventional commits to automatically version a repository
The main motivation behind enforcing conventional commits was to clean up the project’s git history. Being able to understand the changes that a new version brings in through commits alone can speed up code reviews and help when debugging issues or determining when a bug was introduced. It is a good practice to commit early and often, though the balance between committing every failed experiment with the code and not cluttering the history has led to many different git strategies. While the project inspiring this blog post makes no recommendations on how often to commit, it does enforce at least a 20-character title and 20-character body for the commit message. This adherence to conventional commits by the team was foundational to the rest of the work done in the project and described in this blog post. Without the ability to determine what changed and the impact of the change directly in the git history, it would have complicated the effort and potentially driven towards a less portable solution. Enforcing a 20-character minimum may seem arbitrary and a burden for some smaller changes. However, enforcing this minimum is a way to get to informative commit messages that have real meaning for a human that is reviewing them. As noted above this limit can force developers to transform a commit message from ci working to Updated variable X in the ci file to fix build failures with GCC.
Semantic Versioning
As noted, conventional commits tie themselves to the notion of semantic versioning, which semver.org defines as "a simple set of rules and requirements that dictate how version numbers are assigned and incremented." The standard denotes a version number consisting of MAJOR.MINOR.PATCH where MAJOR is any change that is incompatible, MINOR is a backward compatible change with new features, and PATCH is a backward compatible bug fix. While there are other versioning strategies and some noted issues with semantic versioning, this is the convention that the team chose to use. Having versions denoted in this way via git tags allows users to see the impact of the change and update to a new version when ready. Conversely a team could continue to live at head until they run into an issue and then more easily see what versions were available to roll back to.
COTS Solutions
This issue of automatically updating to a new semantic version when a merge request is accepted is not a new idea. There are tools and automations that provide the same functionality but are generally targeted at a specific CI system, such as GitHub Actions, or a specific language, such as Python. As an example, the autosemver python package is able to extract information from git commits to generate a version. The autosemver capability, however, relies on being set up in a setup.py file. Additionally, this project is not extensively used in the Python community. Similarly, there is a semantic-release tool, but this requires Node.js in the build environment, which is less common in some projects and industries. There are also open-source GitHub actions that enable automatic semantic versioning, which is great if the project is hosted on that platform. After evaluating these options though, it did not seem necessary to introduce Node.js as a dependency. The project was not hosted on GitHub, and the project was not Python-based. Due to these limitations, I decided to implement my own minimum viable product (MVP) for this functionality.
Other Implementations
Having decided against off-the-shelf solutions to the problem of versioning the repo, next I turned to a few blog posts on the subject. First a post by Three Dots Labs helped me identify a solution that was oriented toward GitLab, similar to my project. That post, however, left it up to the reader how to determine the next tag version. Marc Rooding expanded the Three Dots Labs post with his own blog post. Here he suggests using merge request labels and pulling those from the API to figure out the version to bump the repository to. This approach had three drawbacks that I identified. First, it seemed like an additional manual step to add the correct tags to the merge request. Second, it relies on the API to get tags from the merge request. Finally, this would not work if a hotfix was committed directly to the default branch. While this last point should be disallowed by policy, the pipeline should still be robust should it happen. Given the likelihood of error in this case of commits directly to main, it’s even more important that tags are generated for rollback and tracking. Given these factors, I decided to settle on using the conventional commit types from the git history to determine the version update needed.
Implementation
This template repository referenced in the introduction uses GitLab as the CI/CD system. Consequently, I wrote a pipeline job to extract the git history for the default branch after being merged. The pipeline job assumes that either (1) there is a single commit, (2) the commits were squashed and that each properly formatted commit message is contained in the squash commit, or (3) a merge commit is generated in the same way (containing all branch commits). This means that the setup proposed here can work with squash-and-merge or rebase-and-fast-forward strategies. It also handles commits directly to the default branch, if anyone would do that. In each case, the assumption is that the commit--whether merger, squash, or regular--still matches the pattern for conventional commits and is written appropriately with the correct conventional commit type (major, feature, etc.). The last commit is stored in a variable LAST_COMMIT as well as the last tag in the repo LAST_TAG.
A quick aside on merging strategies. The solution proposed in this blog post assumes that the repository uses a squash-and-merge strategy for integrating changes. There are several defensible arguments for both a linear history with all intermediate commits represented or for a cleaner history with only a single commit per version. With a full, linear history one can see the development of each feature and all trials and errors a developer had along the way. However, one downside is that not every version of the repository represents a working version of the code. With a squash-and-merge strategy, when a merge is performed, all commits in that merge are condensed into a single commit. This means that there is a one-to-one relationship with commits on the main branch and branches merged into it. This enables reverting to any one commit and having a version of the software that passed through whatever review process is in place for changes going into the trunk or main branch of the repository. The correct strategy should be determined for each project. Many tools that wrap around git, such as GitLab, make the process for either strategy straightforward with settings and configuration options.
With all the conventional commit messages since the last merge to main captured, these commit messages were passed off to the next_version.py Python script. The logic is pretty simple. For inputs there’s the current version number and the last commit message. The script simply looks for the presence of “major” or “feature” as the commit type in the message. It works on the basis that if any commit in the branch’s history is typed as “major” the script is done and outputs the next major version. If not found, the script searches for “minor” and if not found the merge is assumed to be a patch version. In this way the repo is always updated by at least a patch version.
The logic in the Python script is very simple because it was already a dependency in the build environment, and it was clear enough what the script was doing. The same could be rewritten in Bash (e.g., the semver tool), in another scripting language, or as a pipeline of *nix tools.
This code defines a GitLab pipeline with a single stage (release) that has a single job in that stage (tag-release). Rules are specified that the job only runs if the commit reference name is the same as the default branch (usually main). The script portion of the job adds curl and Python to the image. Next it gets the last commit via the git log command and stores it in the LAST_COMMIT variable. It does the same with the last tag. The pipeline then uses the next_version.py script to generate the next tag version and finally pushes a tag with the new version using curl to the GitLab API.
```
stages:
- release
tag-release:
rules:
- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCH
stage: release
script:
- apk add curl git python3
- LAST_COMMIT=$(git log -1 --pretty=%B) # Last commit message
- LAST_TAG=$(git describe --tags --abbrev=0) # Last tag in the repo
- NEXT_TAG=$(python3 next_version.py ${LAST_TAG} ${LAST_COMMIT})
- echo Pushing new version tag ${NEXT_TAG}
- curl -k --request POST --header "PRIVATE-TOKEN:${TAG_TOKEN}" --url "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/repository/tags?tag_name=${NEXT_TAG}&ref=main"
```
The following Python script takes in two arguments, the last tag in the repo and the last commit message. The script then finds the type of commit via the if/elseif/else statements to increment the last tag to the appropriate next tag and prints out the next tag to be consumed by the pipeline.
```
import sys
last_tag = sys.argv[1]
last_commit = sys.argv[2]
next_tag = ""
brokenup_tag = last_tag.split(".")
if "major/" in last_commit:
major_version = int(brokenup_tag[0])
next_tag = str(major_version+1)+".0.0"
elif "feature/" in last_commit:
feature_version = int(brokenup_tag[1])
next_tag = brokenup_tag[0]+"."+str(feature_version+1)+".0"
else:
patch_version = int(brokenup_tag[2])
next_tag = brokenup_tag[0]+"."+brokenup_tag[1]+"."+str(patch_version+1)
print(next_tag)
```
Finally, the last step is to push the new version to the git repository. As mentioned, this project was hosted in GitLab, which provides an API for git tags in the repo. The NEXT_TAG variable was generated by the Python script, and then we used curl to POST a new tag to the repository’s /tags endpoint. Encoded in the URL is the ref to make the tag from. In this case it is main but could be adjusted. The only gotcha here is, as stated previously, that the job runs solely on the default pipeline after the merge takes place. This ensures the last commit (HEAD) on the default branch (main) is tagged. In the above GitLab job, the TAG_TOKEN is a CI variable whose value is a deploy token. This token needs to have the appropriate permissions set up to be able to write to the repository.
Next Steps
Semantic versioning's main motivation is to avoid a situation where a piece of software is in either a state of version lock (the inability to upgrade a package without having to release new versions of every dependent package) or version promiscuity (assuming compatibility with more future versions than is reasonable). Semantic versioning also helps to signal to users and avoid running into issues where an API call is changed or removed, and software will not interoperate. Tracking versions informs users and other software that something has changed. This version number, while helpful, does not let a user know what has changed. The next step, building on both discrete versions and conventional commits, is the ability to condense those changes into a changelog giving developers and users, “a curated, chronologically ordered list of notable changes for each version of a project.” This helps developers and users know what has changed, in addition to the impact.
Having a way to signal to users when a library or other piece of software has changed is important. Even so, it is not necessary to have versioning be a manual process for developers. There are products and free, open source solutions to this issue, but they may not always be a good fit for any particular development environment. When it comes to security-critical software, such as encryption or authentication, it’s a good idea to not roll your own. However, for continuous integration (CI) jobs sometimes commercial off-the shelf (COTS) solutions are excessive and bring significant dependencies with them. In this example, with a 6-line BASH script and a 15-line Python script, one can implement auto-semantic versioning in a pipeline job that (in the deployment tested) runs in ~10 seconds. This example also shows how the process can be minimally tied to a specific build or CI system and not dependent on a specific language or runtime (even if Python was used out of convenience).
Additional Resources
Read the SEI technical report Best Practices for Artifact Versioning in Service-Oriented Systems, which describes some of the challenges of software versioning in an SOA environment and provides guidance on how to meet these challenges by following industry guidelines and recommended practices.
Written By

More By The Author
More In Cybersecurity Engineering
PUBLISHED IN
Cybersecurity EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cybersecurity Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed