Improving Automated Retraining of Machine-Learning Models

Machine learning (ML) models are increasingly used to support mission and business goals, ranging from determining reorder points for supplies, to event triaging, to suggesting courses of action. However, ML models degrade in performance after being put into production, and must be retrained, either automatically or manually, to account for changes in operational data with respect to training data. Manual retraining is effective, but costly, time consuming, and dependent on the availability of trained data scientists. Current industry practice offers MLOps as a potential solution to achieve automatic retraining. These industry MLOps pipelines do achieve faster retraining time, but pose a greater range of future prediction errors because they simply offer a refitting of the old model to new data instead of analyzing for changes in the data. In this blog post, I describe an SEI project that sought to improve representative MLOps pipelines by adding automated exploratory data-analysis tasks.
Improved MLOps pipelines can
- reduce manual model retraining time and cost by automating initial steps of the retraining process
- provide immediate, repeatable input to later steps of the retraining process so that data scientists can spend time on tasks that are more critical to improving model performance
The goal of this work was to extend an MLOps pipeline with improved automated data analysis so that ML systems can adapt models more quickly to operational data changes and reduce instances of poor model performance in mission-critical settings. As the SEI leads a national initiative to advance the emergent discipline of AI engineering, the scalability of AI, and specifically machine learning, this is crucial to realizing operational AI capabilities.
Proposed Improvements to Current Practice
Current practice for refitting of an old model to new data has several limitations: It assumes that new training data should be treated the same as the initial training data, and that model parameters are constant and should be the same as those identified with the initial training data. Refitting is also not based on any information about why the model was performing poorly; and there is no informed procedure for how to combine the operational dataset with the original training dataset into a new training dataset.
An MLOps process that relies on automatic retraining based on these assumptions and informational shortcomings cannot guarantee that its assumptions will hold and that the new retrained model will perform well. The consequence for systems relying on models retrained with such limitations is potentially poor model performance, which may lead to reduced trust in the model or system.
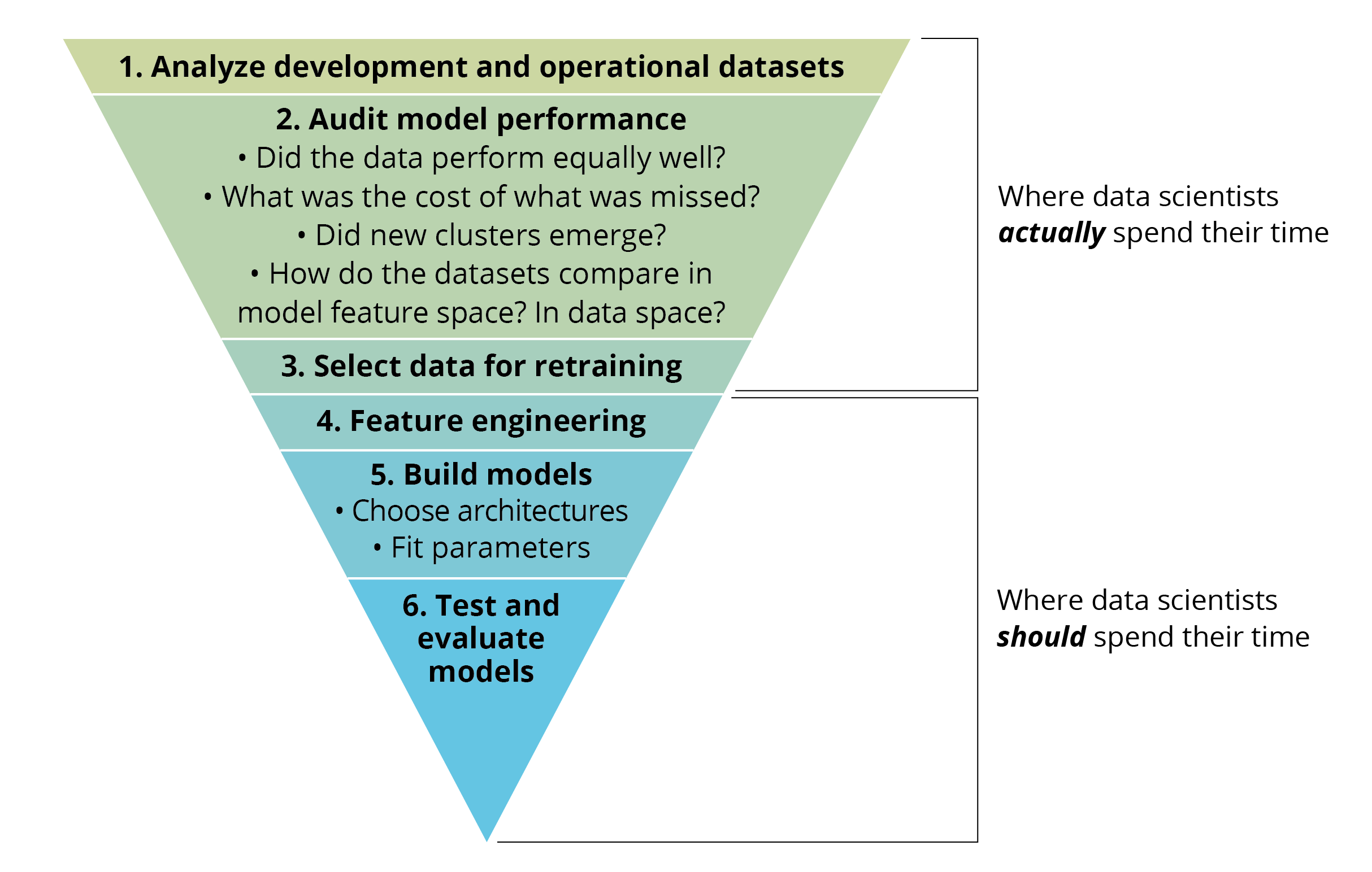
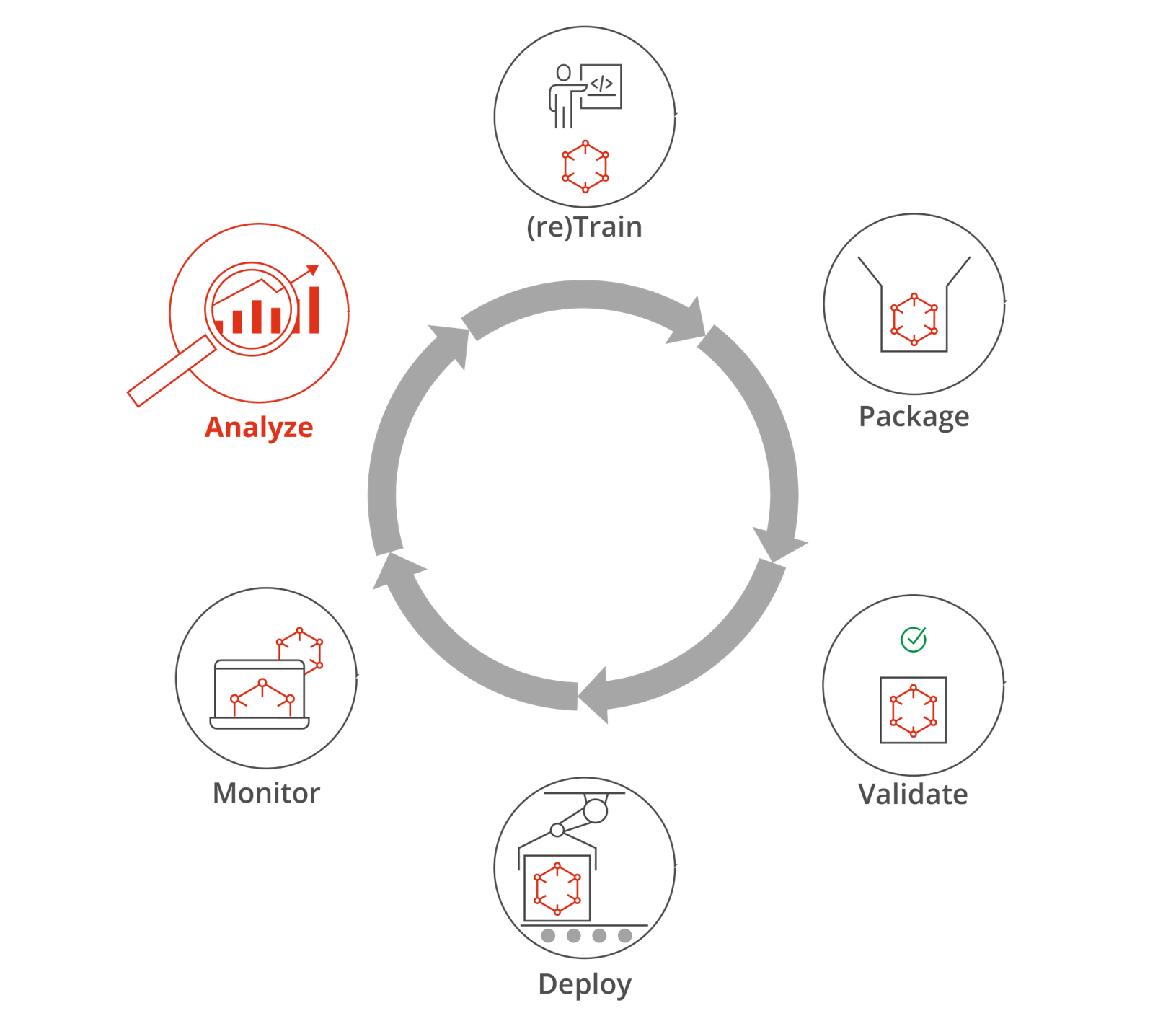
The automated data-analysis tasks that our team of researchers at the SEI developed to add to an MLOps pipeline are analogous to manual tests and analyses done by data scientists during model retraining, shown in Figure 1. Specifically, the goal was to automate Steps 1 to 3—analyze, audit, select—which is where data scientists spend much of their time. In particular, we built an extension for a typical MLOps pipeline—a model operational analysis step—that executes after the monitor model step of an MLOps pipeline signals a need for retraining, as shown in Figure 2.
Approach for Retraining in MLOps Pipelines
The goal of our project was to develop a model operational analysis module to automate and inform retraining in MLOps pipelines. To build this module, we answered the following research questions:
- What data must be extracted from the production system (i.e., operational environment) to automate “analyze, audit, and select”?
- What is the best way to store this data?
- What statistical tests, analyses, and adaptations on this data best serve as input for automated or semi-automated retraining?
- In what order must tests be run to minimize the number of tests to execute?
We followed an iterative and experimental process to answer these research questions:
Model and dataset generation—We developed datasets and models for inducing common retraining triggers, such as general data drift and emergence of new data classes. The datasets used for this task were (1) a simple color dataset (continuous data) with models such as decision trees and k-means, and (2) the public fashion Modified National Institute of Standards and Technology (MNIST) dataset (image data) with deep neural-network models. The output of this task was the models, and the corresponding training and evaluation.
Identification of statistical tests and analyses—Using the performance of evaluation datasets on the models generated in the previous task, we determined the statistical tests and analyses required to collect the information for automated retraining, the data from the operational environment, and how this data should be stored. This was an iterative process to determine what statistical tests and analyses must be executed to maximize the information gained yet minimize the number of tests performed. An additional artifact created in the execution of this task was a testing pipeline to determine (1) differences between the development and operational datasets, (2) where the deployed ML model was lacking in performance, and (3) what data should be used for retraining.
Implementation of model operational analysis module—We implemented the model operational analysis module by developing and automating (1) data collection and storage, (2) identified tests and analyses, and (3) generation of results and recommendations to inform the next retraining steps.
Integration of model operational analysis model into an MLOps pipeline—Here we integrated the module into an MLOps pipeline to observe and validate the end-to-end process from the retraining trigger to the generation of recommendations for retraining to the deployment of the retrained model.
Outputs of This Project
Our goal was to demonstrate the integration of the data analyses, testing, and retraining recommendations that would be done manually by a data scientist into an MLOps pipeline, both to improve automated retraining and to speed up and focus manual retraining efforts. We produced the following artifacts:
- statistical tests and analyses that inform the automated retraining process with respect to operational data changes
- prototype implementation of tests and analyses in a model operational analysis module
- extension of an MLOps pipeline with model operational analysis
Further Development
If you are interested in further developing, implementing, or evaluating our extended MLOps pipeline, we would be happy to work with you. Please contact us at info@sei.cmu.edu.
Additional Resources
Read the SEI blog post, Software Engineering for Machine Learning: Characterizing and Detecting Mismatch in Machine-Learning Systems.
Read other SEI blog posts about artificial intelligence and machine learning.
Read the National AI Engineering Initiative report, Scalable AI.
Written By

More In Artificial Intelligence Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed