GenAI for Code Review of C++ and Java

PUBLISHED IN
Artificial Intelligence EngineeringThis post is also authored by Vedha Avali and Genavieve Chick who performed the code analysis described and summarized below.
Since the release of OpenAI’s ChatGPT, many companies have been releasing their own versions of large language models (LLMs), which can be used by engineers to improve the process of code development. Although ChatGPT is still the most popular for general use cases, we now have models created specifically for programming, such as GitHub Copilot and Amazon Q Developer. Inspired by Mark Sherman’s blog post analyzing the effectiveness of Chat GPT-3.5 for C code analysis, this post details our experiment testing and comparing GPT-3.5 versus 4o for C++ and Java code review.
We collected examples from the SEI CERT Secure Coding standards for C++ and Java. Each rule in the standard contains a title, a description, noncompliant code examples, and compliant solutions. We analyzed whether ChatGPT-3.5 and ChatGPT-4o would correctly identify errors in noncompliant code and correctly recognize compliant code as error-free.
Overall, we found that both the GPT-3.5 and GPT-4o models are better at identifying mistakes in noncompliant code than they are at confirming correctness of compliant code. They can accurately discover and correct many errors but have a hard time identifying compliant code as such. When comparing GPT-3.5 and GPT-4o, we found that 4o had higher correction rates on noncompliant code and hallucinated less when responding to compliant code. Both GPT 3.5 and GPT-4o were more successful in correcting coding errors in C++ when compared to Java. In categories where errors were often missed by both models, prompt engineering improved results by allowing the LLM to focus on specific issues when providing fixes or suggestions for improvement.
Analysis of Responses
We used a script to run all examples from the C++ and Java secure coding standards through GPT-3.5 and GPT-4o with the prompt
What is wrong with this code?
Each case simply included the above phrase as the system prompt and the code example as the user prompt. There are many potential variations of this prompting strategy that would produce different results. For instance, we could have warned the LLMs that the example might be correct or requested a specific format for the outputs. We intentionally chose a nonspecific prompting strategy to discover baseline results and to make the results comparable to the previous analysis of ChatGPT-3.5 on the CERT C secure coding standard.
We ran noncompliant examples through each ChatGPT model to see whether the models were capable of recognizing the errors, and then we ran the compliant examples from the same sections of the coding standards with the same prompts to test each model’s ability to recognize when code is actually compliant and free of errors. Before we present overall results, we want to present the categorization schemes that we created for noncompliant and compliant responses from ChatGPT and provide one illustrative example for each response category. In these illustrative examples, we included responses under different experimental conditions—in both C++ and Java, as well as responses from GPT-3.5 and GPT-4o—for variety. The full set of code examples, responses from both ChatGPT models, and the categories that we assigned to each response, can be found at this link.
Noncompliant Examples
We classified the responses to noncompliant code into the following categories:
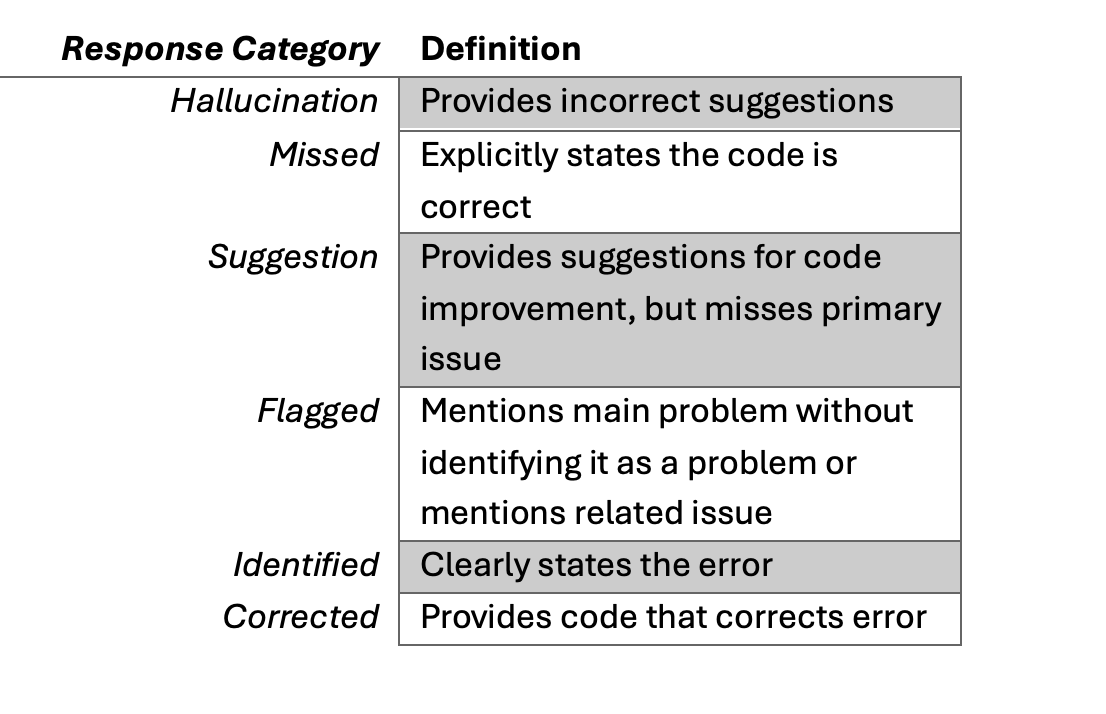
Our first goal was to see if OpenAI’s models would correctly identify and correct errors in code snippets from C++ and Java and bring them into compliance with the SEI coding standard for that language. The following sections provide one representative example for each response category as a window into our analysis.
Example 1: Hallucination
NUM01-J, Ex. 3: Do not perform bitwise and arithmetic operations on the same data.
This Java example uses bitwise operations on negative numbers resulting in the wrong answer for -50/4.

GPT-4o Response

In this example, the reported problem is that the shift is not performed on byte, short, int, or long, but the shift is clearly performed on an int, so we marked this as a hallucination.
Example 2: Missed
ERR59-CPP, Ex. 1: Do not throw an exception across execution boundaries.
This C++ example throws an exception from a library function signifying an error. This can produce strange responses when the library and application have different ABIs.

GPT-4o Response

This response indicates that the code works and handles exceptions correctly, so it is a miss even though it makes other suggestions.
Example 3: Suggestions
DCL55-CPP, Ex. 1: Avoid information leakage when passing a class object across a trust boundary.
In this C++ example, the padding bits of data in kernel space may be copied to user space and then leaked, which can be dangerous if these padding bits contain sensitive information.

GPT-3.5 Response

This response fails to recognize this issue and instead focuses on adding a const declaration to a variable. While this is a valid suggestion, this recommendation does not directly affect the functionality of the code, and the security issue mentioned previously is still present. Other common suggestions include adding import statements, exception handling, missing variable and function definitions, and executing comments.
Example 4: Flagged
MET04-J, Ex. 1: Do not increase the accessibility of overridden or hidden methods
This flagged Java example shows a subclass increasing accessibility of an overriding method.

GPT-3.5 Response

This flagged example recognizes the error pertains to the override, but it does not identify the main issue: the subclasses’ ability to change the accessibility when overriding.
Example 5: Identified
EXP57-CPP, Ex. 1: Do not cast or delete pointers to incomplete classes
This C++ example removes a pointer to an incomplete class type; thus, creating undefined behavior.

GPT-3.5 Response

This response identifies the error of trying to delete a class pointer before defining the class. However, it does not provide the corrected code, so it is labeled as identified.
Example 6: Corrected
DCL00-J, Ex. 2: Prevent class initialization cycles
This simple Java example includes an interclass initialization cycle, which can lead to a mix up in variable values. Both GPT-3.5 and GPT-4o corrected this error.

GPT-4o Response

This snippet from 4o’s response identifies the error and provides a solution like the provided compliant solution.
Compliant Examples
We tested GPT-3.5 and GPT-4o on each of the compliant C++ and Java code snippets to see if they would recognize that there is nothing wrong with them. As with the noncompliant examples, we submitted each compliant example as the user prompt with a system prompts that stated, “What is wrong with this code?” We classified responses to compliant examples into the following categories.

It should be noted that a different prompting strategy could easily improve the results by giving the LLM more specific information. For example, we could have stated that the code snipped might be correct, and if so, that the LLM should explicitly state that it is correct. Our goal in this section is to describe the baseline behavior of the LLM and to remain comparable with the prior results. We explore the effects of refining the prompt in the final section of this post.
This section provides examples of the different types of responses (correct, suggestion, and hallucination) ChatGPT provided. Again, we chose examples from both C++ and Java, and from both ChatGPT models for variety. Interested readers can see the full results for all compliant examples at this link.
Example 1: Hallucination
EXP51-CPP, C. Ex. 1: Do not delete an array through a pointer of the incorrect type
In this compliant C++ example, an array of Derived objects is stored in a pointer with the static type of Derived, which does not result in undefined behavior.

GPT-4o Response

We labeled this response as a hallucination as it brings the compliant code into noncompliance with the standard. The GPT-4o response treats the array of Derived objects as Base objects before deleting it. However, this will result in undefined behavior despite the virtual destructor declaration, and this would also result in pointer arithmetic being performed incorrectly on polymorphic objects.
Example 2: Suggestion
EXP00-J, EX.1: Do not ignore values returned by methods
This compliant Java code demonstrates a way to check values returned by a method.

GPT-4o Response

This response provides valid suggestions for code improvement but does not explicitly state that the code is correct or that it will correctly execute as written.
Example 3: Correct
CTR52-CPP, Ex. 1: Guarantee that library functions do not overflow
The following compliant C++ code copies integer values from the src vector to the dest vector and ensures that overflow will not occur by initializing dest to a sufficient initial capacity.

GPT-3.5 Response

In examples like this one, where the LLM explicitly states that the code has no errors before providing suggestions, we decided to label this as “Correct.”
Results: LLMs Showed Greater Accuracy with Noncompliant Code

First, our analysis showed that the LLMs were far more accurate at identifying flawed code than they were at confirming correct code. To more clearly show this comparison, we combined some of the categories. Thus, for compliant responses suggestion and hallucination became incorrect. For noncompliant code samples, corrected and identified counted towards correct and the rest incorrect. In the graph above, GPT-4o (the more accurate model, as we discuss below) correctly found the errors 83.6 percent of the time for noncompliant code, but it only identified 22.5 percent of compliant examples as correct. This trend was constant across Java and C++ for both LLMs. The LLMs were very reluctant to recognize compliant code as valid and almost always made suggestions even after stating, “this code is correct.”
GPT-4o Out-performed GPT-3.5

Overall, the results also showed that GPT-4o performed significantly better than GPT-3.5. First, for the noncompliant code examples, GPT-4o had a higher rate of correction or identification and lower rates of missed errors and hallucinations. The above figure shows exact results for Java, and we saw similar results for the C++ examples with an identification/correction rate of 63.0 percent for GPT-3.5 versus a significantly higher rate of 83.6 percent for GPT-4o.
The following Java example demonstrates the contrast between GPT-3.5 and GPT-4o. This noncompliant code snippet contains a race condition in the getSum() method because it is not thread safe. In this example, we submitted the noncompliant code on the left to each LLM as the user prompt, again with the system prompt stating, “What is wrong with this code?”
VNA02-J, Ex. 4: Ensure that compound operations on shared variables are atomic

GPT-3.5 Response

GPT-4o Response

GPT-3.5 stated there were no problems with the code while GPT-4o caught and fixed three potential issues, including the thread safety issue. GPT-4o did go beyond the compliant solution, which synchronizes the getSum() and setValues() methods, to make the class immutable. In practice, developers would have the opportunity to interact with the LLM if they did not desire this change of intent.

With the complaint code examples, we generally saw lower rates of hallucinations, but GPT 4o’s responses were much wordier and provided many suggestions, making the model less likely to cleanly identify the Java code as correct. We saw this trend of lower hallucinations in the C++ examples as well, as GPT-3.5 hallucinated 53.6 percent of the time on the compliant C++ code, but only 16.3 percent of the time when using GPT-4o.
The following Java example demonstrates this tendency for GPT-3.5 to hallucinate while GPT-4o offers suggestions while being reluctant to confirm correctness. This compliant function clones the date object before returning it to ensure that the original internal state within the class is not mutable. As before, we submitted the compliant code to each LLM as the user prompt, with the system prompt, “What is wrong with this code?”
OBJ-05, Ex 1: Do not return references to private mutable class members

GPT-3.5 Response

GPT-3.5’s response states that the clone method is not defined for the Date class, but this statement is incorrect as the Date class will inherit the clone method from the Object class.
GPT-4o Response

GPT-4o’s response still does not identify the function as correct, but the potential issues described are valid suggestions, and it even provides a suggestion to make the program thread-safe.
LLMs Were More Accurate for C++ Code than for Java Code
This graph shows the distribution of responses from GPT-4o for both Java and C++ noncompliant examples.
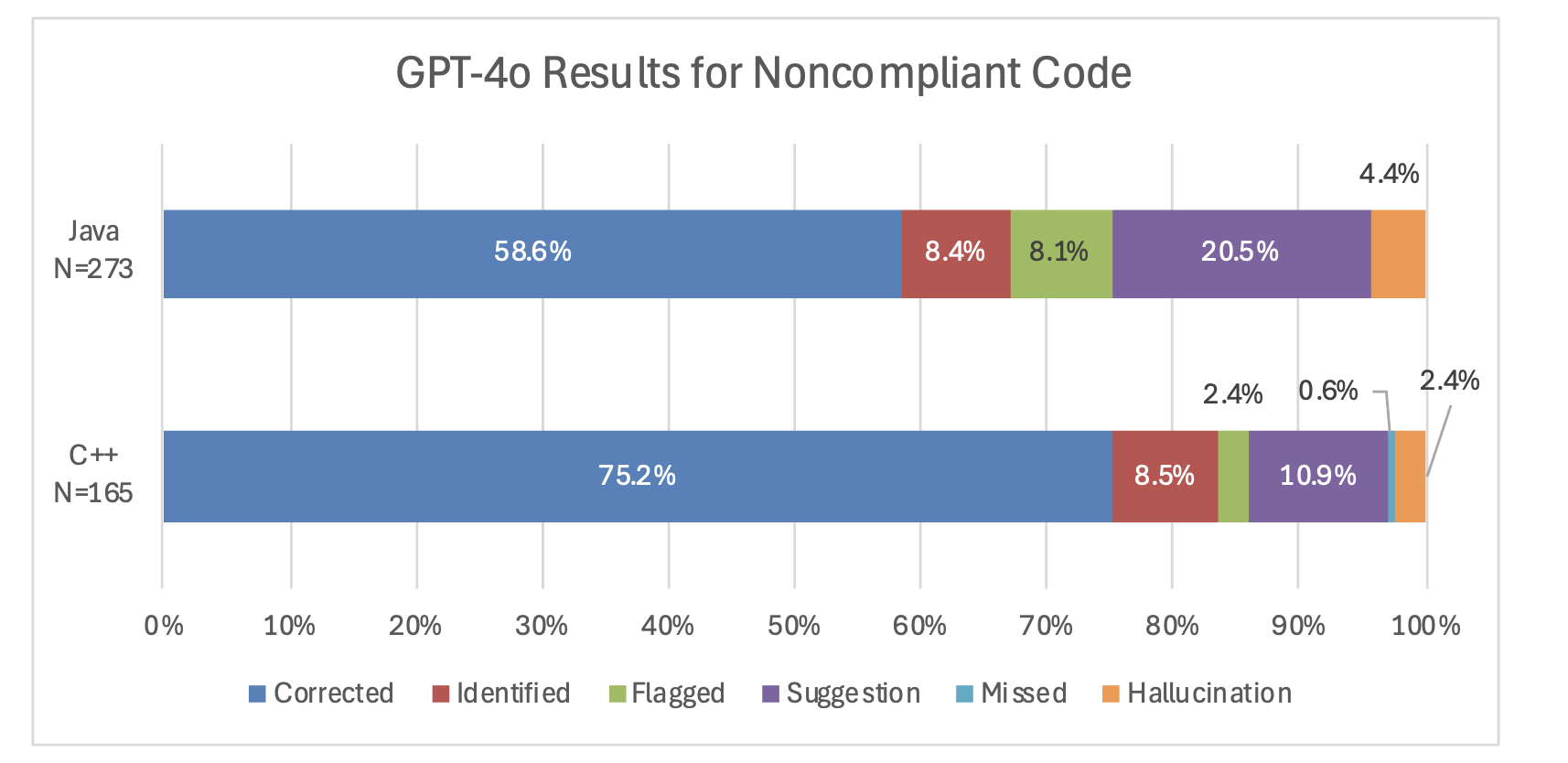
GPT-4o consistently performed better on C++ examples compared to java examples. It corrected 75.2 percent of code samples compared to 58.6 percent of Java code samples. This pattern was also consistent in GPT-3.5’s responses. Although there are differences between the rule categories discussed in the C++ and Java standards, GPT-4o performed better on the C++ code compared to the Java code in almost all of the common categories: expressions, characters and strings, object orientation/object-oriented programming, exceptional behavior/exceptions, and error handling, input/output. The one exception was the Declarations and Initializations Category, where GPT-4o identified 80 percent of the errors in the Java code (four out of five), but only 78 percent of the C++ examples (25 out of 32). However, this difference could be attributed to the low sample size, and the models still overall perform better on the C++ examples. Note that it is difficult to understand exactly why the OpenAI LLMs perform better on C++ compared to java, as our task falls under the domain of reasoning, which is an emergent LLM ability. ( See the article “Emergent Abilities of Large Language Models,” by Jason Wei et al. (2022) for a discussion of emergent LLM abilities.)
The Impact of Prompt Engineering
Thus far, we have learned that LLMs have some capability to evaluate C++ and Java code when provided with minimal up-front instruction. But, one could easily imagine ways to improve performance by providing more details about the required task. To test this most efficiently, we chose code samples that the LLMs struggled to identify correctly rather than re-evaluating the hundreds of examples we previously summarized. In our initial experiments, we noticed the LLMs struggled on section 15 - Platform Security, so we gathered the compliant and noncompliant examples from Java in that section to run through GPT-4o, the better performing model of the two, as a case study. We changed the prompt to ask specifically for platform security issues and requested that it ignore minor issues like import statements. The new prompt became
Are there any platform security issues in this code snippet, if so please correct them? Please ignore any issues related to exception handling, import statements, and missing variable or function definitions. If there are no issues, please state the code is correct.
Updated Prompt Improves Performance for Noncompliant Code
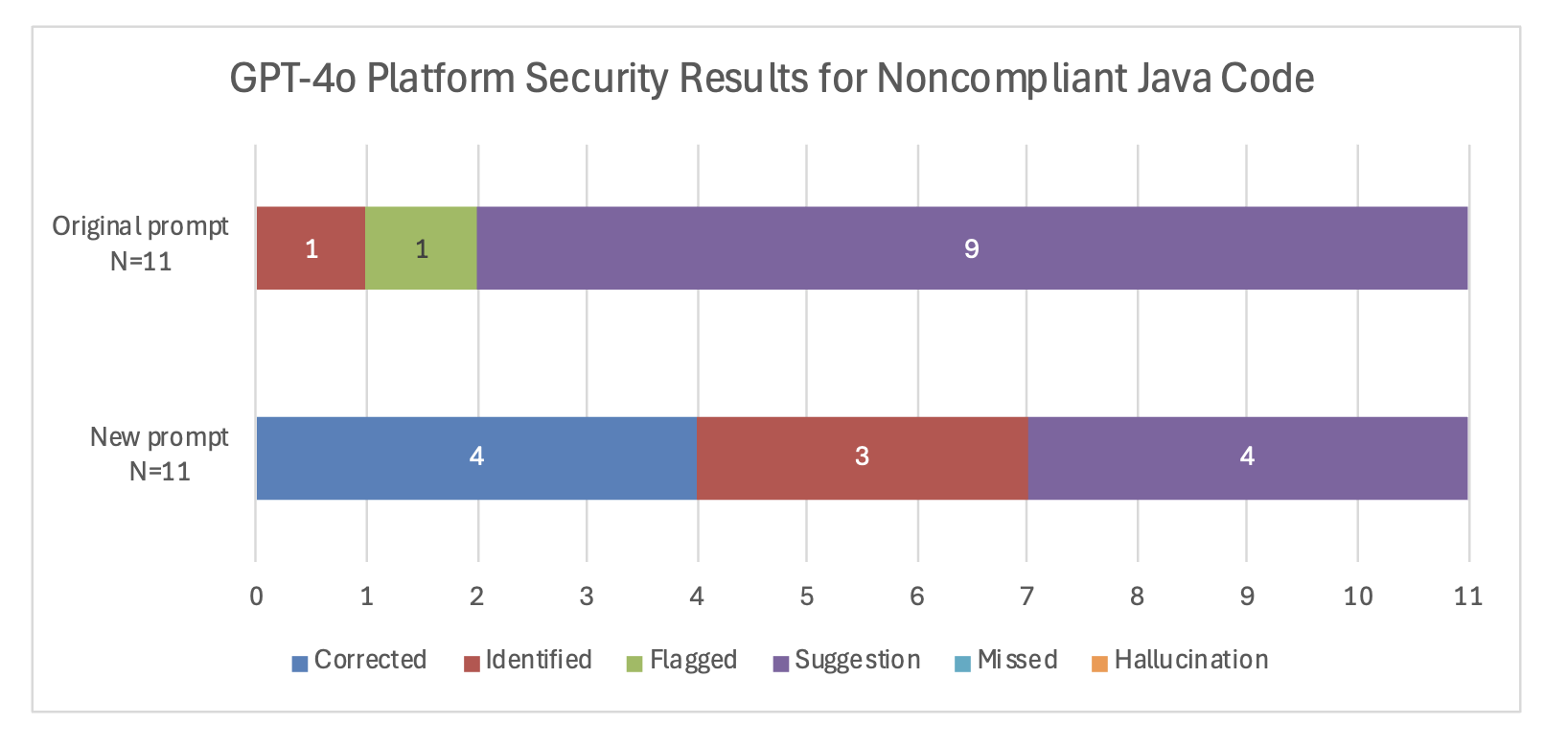
The updated prompt resulted in a clear improvement in GPT-4o’s responses. Under the original prompt, GPT-4o was not able to correct any platform security errort, but with the more specific prompt it corrected 4 of 11. With the more specific prompt, GPT-4o also identified an additional 3 errors versus only 1 of under the original prompt. If we consider the corrected and identified categories to be the most useful, then the improved prompt reduced the number of non-useful responses from 10 of 11 down to 4 of 11.
The following responses show an example of how the revised prompt led to an improvement in model performance.
In the Java code below, the zeroField() method uses reflection to access private members of the FieldExample class. This may leak information about field names through exceptions or may increase accessibility of sensitive data that is visible to zeroField().
SEC05-J, Ex.1: Do not use reflection to increase accessibility of classes, methods, or fields

To bring this code into compliance, the zeroField() method may be declared private, or access can be provided to the same fields without using reflection.


In the original solution, GPT-4o makes trivial suggestions, such as adding an import statement and implementing exception handling where the code was marked with the comment “//Report to handler.” Since the zeroField() method is still accessible to hostile code, the solution is noncompliant. The new solution eliminates the use of reflection altogether and instead provides methods that can zero i and j without reflection.
Performance with New Prompt is Mixed on Compliant Code

With an updated prompt, we saw a slight improvement on one additional example in GPT-4o’s ability to identify correct code as such, but it also hallucinated on two others that only resulted in suggestions under the original prompt. In other words, on a few examples, prompting the LLM to look for platform security issues caused it to respond affirmatively, whereas under the original less-specific prompt it would have offered more general suggestions without stating that there was an error. The suggestions with the new prompt also ignored trivial errors such as exception handling, import statements, and missing definitions. They became a little more focused on platform security as seen in the example below.
SEC01-J, Ex.2: Do not allow tainted variables in privileged blocks

GPT-4o Response to new prompt

Implications for Using LLMs to Fix C++ and Java Errors
As we went through the responses, we realized that some responses did not just miss the error but provided false information, while others were not wrong but made trivial recommendations. We added hallucination and suggestions to our categories to represent these meaningful gradations in responses. The results show the GPT-4o hallucinates less than GPT-3.5; however, its responses are more verbose (though we could have potentially addressed this by adjusting the prompt). Consequently, GPT-4o makes more suggestions than GPT-3.5, especially on compliant code. In general, both LLMs performed better on noncompliant code for both languages, although they did correct a higher percentage of the C++ examples. Finally, prompt engineering greatly improved results on the noncompliant code, but really only improved the focus of the suggestions for the compliant examples. If we were to continue this work, we would experiment more with various prompts, focusing on improving the compliant results. This could possibly include adding few-shot examples of compliant and noncompliant code to the prompt. We would also explore fine tuning the LLMs to see how much the results improve.
Additional Resources
Using ChatGPT to Analyze Your Code? Not So Fast by Mark Sherman
Written By

More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed