Forking and Joining Python Coroutines to Collect Coverage Data
In this post I'll explain how to expand on David Beazley's cobroadcast pattern by adding a join capability that can bring multiple forked coroutine paths back together. I'll apply this technique to create a modular Python script that uses gcov, readelf, and other common unix command line utilities to gather code coverage information for an application that is being tested. Along the way I'll use ImageMagick under Ubuntu 12.04 as a running example.
Coroutines
In the Python programming language, coroutines are an extension of the generator language construct that enables programmers to write clean, efficient code for data processing, concurrency, and other common tasks. You can read more about coroutines in PEP 342 and David Beazley's Curious Course on Coroutines. Once you become comfortable with coroutine conventions they can be quite useful.
Measuring Code Coverage with gcov
There are several useful GUI tools built on top of the GNU coverage testing tool (gcov), such as ggcov and lcov. In this blog post I'll write a new non-GUI gcov wrapper script to motivate the application of coroutines and the new Broadcaster pattern. I'll start by briefly discussing how gcov works.
To use gcov, first you compile the target application with flags that cause application executions to produce coverage information. See the gcov documentation for more info on compilation flags.
$ apt-get source imagemagick
$ cd imagemagick-6.6.9.7/
$ ./configure CFLAGS="-fprofile-arcs -ftest-coverage -g -O0" \
CXXFLAGS="-g -O0 -pthread" && makeThen, you run the application to generate coverage information:
$ wget http://www.kb.cert.org/registration/cert_logo.gif
$ ./utilities/convert cert_logo.gif cert_logo.png
lt-convert: UnableToOpenConfigureFile `delegates.xml' @ warning/configure.c/GetConfigureOptions/589.Note that in this example we run only one invocation of a program. A more realistic application of this technique would include running a test suite against the program, running multiple randomized tests against the program (as with the CERT Basic Fuzzing Framework [BFF]), or applying some other more thorough testing scheme.
Regardless, at this point every object file that was used during execution now has a corresponding .gcda file that contains coverage information about the execution. gcov takes a gcda file and a source file as input and describes the coverage for that source file with respect to the gcda file. For example, first we find a gcda file:
$ find . -name "*.gcda" | head -n 2
./utilities/convert.gcda
./wand/.libs/wand_libMagickWand_la-display.gcdaThen we pick one, along with the correspond source file (explained below), and get coverage information for the source file with gcov:
$ gcov -o ./wand/.libs/wand_libMagickWand_la-display.o ./wand/display.c
File 'wand/display.c'
Lines executed:0.00% of 1098
wand/display.c:creating 'display.c.gcov'
File './magick/string-private.h'
Lines executed:0.00% of 2
./magick/string-private.h:creating 'string-private.h.gcov'Normally a developer will know which source files correspond to which object files, but for someone unfamiliar with the code it can be tricky. For example, there is no "wand_libMagickWand_la-display" .c file in the ImageMagick source tree:
$ find . -name "wand_libMagickWand_la-display*.c"
$One way quick-and-dirty way to determine which source files a gcda file corresponds to is to examine the debug information of the object file that corresponds to a gcda file via readelf.
$ readelf --debug-dump ./wand/.libs/wand_libMagickWand_la-display.o | \
grep -A50 "The File Name Table"
The File Name Table:
Entry Dir Time Size Name
1 1 0 0 string-private.h
2 2 0 0 display.c
3 3 0 0 stddef.h
4 4 0 0 types.h
...Next, we can find a source file by looking for a filename match in the parent directory of the .o file:
$ find . -name "display.c"
./utilities/display.c
./wand/display.c # <--- in the nearest parent directory
./magick/display.cNow we are ready to run gcov on a source file, as described above:
$ gcov -o ./wand/.libs/wand_libMagickWand_la-display.o ./wand/display.c
File 'wand/display.c'
Lines executed:0.00% of 1098
wand/display.c:creating 'display.c.gcov'
File './magick/string-private.h'
Lines executed:0.00% of 2
./magick/string-private.h:creating 'string-private.h.gcov'Using Python to Automate Collecting Code Coverage Information
We can automate the process above for all files in the ImageMagick directory using Python. Here we write a crude first attempt that uses nested loops:
$ cat > nestcov.py
$ cat > nestcov.py
import re, os
from collections import namedtuple
FileCoverage = namedtuple("FileCoverage", ["filename", "percentage", "lines"])
def call(cmd):
import subprocess, shlex
return subprocess.check_output(shlex.split(cmd))
srcdir = os.getcwd()
coverage = []
gcda_filenames = call("find %s -name \"*.gcda\"" % srcdir)
for gcda_filename in gcda_filenames.splitlines():
obj_filename = gcda_filename.replace(".gcda", ".o")
instr = call("readelf --debug-dump %s" % obj_filename)
# get filenames from readelf output
outstr = instr[instr.find("The File Name Table"):]
outstr = outstr[:outstr.find("\n\n")]
outlines = outstr.splitlines()[2:]
c_files = []
for line in outlines:
filename = line.split()[4]
if re.match(".*\.c$|.*\.c..$", filename):
src_filename = call("find %s -name %s" % (srcdir, filename)).splitlines()[0]
gcov_out = call("gcov -no %s %s" % (gcda_filename, src_filename))
filename = None
for gline in gcov_out.splitlines():
if filename:
m = re.match("^Lines executed:(\d+\.\d\d)% of (\d+)$", gline)
if not m:
raise RuntimeError("Failure parsing gcov output; 'Lines' doesn't follow 'Files'")
percent, lines = m.groups()
coverage.append(FileCoverage(filename, float(percent), int(lines)))
filename = None
continue
m = re.match("^File '(.*)'$", gline)
if not m:
filename = None
continue
filename = m.groups()[0]
total_lines = sum([fc.lines for fc in coverage])
total_covered = sum([fc.percentage*fc.lines/100 for fc in coverage])
total_percentage = total_covered / total_lines
print total_percentage
<CTRL-D>We can then run the script and play with the results:
$ python -i nestcov.py
0.0552162336542
>>> for fc in coverage:
... if fc.percentage > 0:
... print fc.filename, fc.percentage
...
utilities/convert.c 100.0
wand/mogrify.c 2.35
./magick/monitor-private.h 60.0
./wand/mogrify-private.h 57.14
wand/convert.c 2.31
coders/xbm.c 5.49
...Cleaning Up the Script with Coroutines
The code above works, but it somewhat difficult to read and is not easily unit tested. We can use coroutines to modularize the code above without introducing any additional loop iterations into the algorithm. Roughly speaking, you can use coroutines like you would use pipes in bash. We can implement something like the bash command below directly via coroutines:
$ find . -name "*.gcda" | sed s/".gcda$"/".o"To accomplish this, we can first implement all of the "functions" we used in our algorithm as coroutines. First, we should get David Beazley's handy coroutine decorator:
$ wget http://dabeaz.com/coroutines/coroutine.pyThen we can implement our functions:
$ cat > cocov.py
import re, os
from collections import namedtuple
from coroutine import coroutine
FileCoverage = namedtuple("FileCoverage", ["filename", "percentage", "lines"])
def call(cmd):
import subprocess, shlex
return subprocess.check_output(shlex.split(cmd))
def gcdas(srcdir, target):
'''
Finds all gcda files in srcdir and sends them to target.
'''
gcda_filenames = call("find %s -name \"*.gcda\"" % srcdir)
for gcda_filename in gcda_filenames.splitlines():
target.send(gcda_filename)
@coroutine
def objfile(target):
'''
Converts the received gcda filemame to its corresponding object filename (see
gcov docs) and sends it to target.
'''
while True:
target.send(re.sub("\.gcda$", ".o", (yield)))
@coroutine
def readelf(target):
'''
Sends the debug file table section of the received elf file to target.
'''
while True:
instr = call("readelf --debug-dump %s" % (yield))
outstr = instr[instr.find("The File Name Table"):]
outstr = outstr[:outstr.find("\n\n")]
target.send(outstr.splitlines()[2:])
@coroutine
def filenames(srcdir, target):
'''
Gets filenames from received filetable and searches up the path of
the received gcda_filename for a path for each respective filename.
When a path is found, it is sent to target.
More generally, this coroutine takes in the file table section from
the readelf command and produces a path for the file on the filesystem
that most likely matches the file, respectively.
'''
while True:
c_files = []
gcda_filename, filetable = (yield)
for line in filetable:
filename = line.split()[4]
if re.match(".*\.c$|.*\.c..$", filename):
searchdir = gcda_filename
while searchdir != srcdir:
searchdir = os.path.dirname(searchdir)
found = call("find %s -name %s" % (searchdir, filename))
if found:
target.send((gcda_filename, found.splitlines()[0]))
break
@coroutine
def gcov(target):
'''
Reads the gcov output for the received gcda_filename and src_filename.
Produces a FileCoverage object for each entry in the gcov output and sends
it to target.
'''
while True:
gcda_filename, src_filename = (yield)
gcov_out = call("gcov -no %s %s" % (gcda_filename, src_filename))
filename = None
for gline in gcov_out.splitlines():
if filename:
m = re.match("^Lines executed:(\d+\.\d\d)% of (\d+)$", gline)
if not m:
raise RuntimeError("Failure parsing gcov output; 'Lines' "
"doesn't follow 'Files'")
percent, lines = m.groups()
target.send(FileCoverage(filename, float(percent), int(lines)))
filename = None
continue
m = re.match("^File '(.*)'$", gline)
if not m:
filename = None
continue
filename = m.groups()[0]
@coroutine
def printer():
while True:
print (yield)
@coroutine
def merger(coverage):
seen = []
while True:
file_coverage = (yield)
if file_coverage.filename in seen:
# coverage defined in multiple files
continue
seen.append(file_coverage.filename)
coverage.append(file_coverage)
<CTRL-D>We can then implement the bash command from the beginning of this section in Python, like so:
$ python -i cocov.py
>> gcdas(os.getcwd(), objfile(printer()))
/home/user0/blog/imagemagick-6.6.9.7/utilities/convert.o
/home/user0/blog/imagemagick-6.6.9.7/wand/.libs/wand_libMagickWand_la-display.o
/home/user0/blog/imagemagick-6.6.9.7/wand/.libs/wand_libMagickWand_la-magick-wand.o
...Forking and Joining Pipelines
Now we have all of the basic coroutines that we need to implement our script, however, there is one issue with the algorithm above that isn't handled well by pipes. In the nested version of the algorithm, the outermost loop iterates over all of the gcda filenames in the current directory. The current filename, gcda_filename, is used immediately inside the loop to determine the object filename for the gcda file:
obj_filename = gcda_filename.replace(".gcda", ".o")And gcda_filename ia nested loop to get the gcov output
gcov_out = call("gcov -no %s %s" % (gcda_filename, src_filename))If we represented the algorithm as an activity diagram, it might look like this:
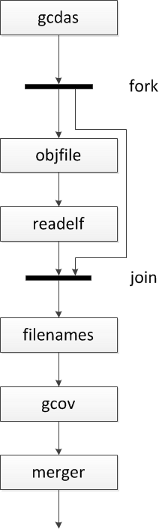
Unfortunately, using the pipe pattern from bash does not allow information to bypass a function and be merged into the input to another downstream function. David Beazley has implemented a cobroadcast pattern that accomplishes the fanning out of input from coroutines:
@coroutine
def broadcast(targets):
while True:
item = (yield)
for target in targets:
target.send(item)This pattern is useful in that it lets one fan out a coroutine's output into several pipes.
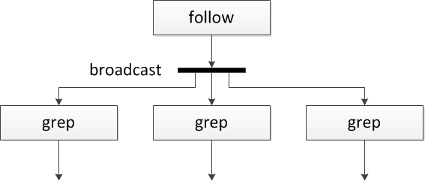
However, it does not allow for merging information back into the same pipeline as we require for our algorithm above. I have expanded David's code to support this functionality. We can tack it onto his coroutine implementation like so:
$ cat >> coroutine.py
class Broadcaster(object):
'''
Allows users to broadcast output of a coroutine to multiple callees and then
serialize results further down the call stream.
WARNING: This design assumes that coroutines have one (yield) and one send().
'''
def __init__(self):
self.serial = []
@coroutine
def fork(self, children, target):
'''
Copies output sent to this coroutine to all coroutines in children.
Results subsequently sent to Broadcaster.join() will be serialized (as a
list) and sent to target.
'''
self.nchildren = len(children)
self.target = target
while True:
item = (yield)
for c in children:
c.send(item)
@coroutine
def join(self):
'''
Results sent to this coroutine are stored. When all of the children passed
to Broacaster.fork have sent results, a list of the results is sent to
the target passed to Broadcaster.fork.
'''
while True:
result = (yield)
self.serial.append(result)
if len(self.serial) == self.nchildren:
self.target.send(self.serial)
self.serial = []
<CTRL-D>We can use an instance of this class to fan out input from the gcda(..) coroutine and the merge it back into the gcov(..) coroutine. Here is what the code for our coverage pipeline might look like:
$ cat >> cocov.py
from coroutine import Broadcaster
def get_coverage(srcdir):
coverage = []
bcast = Broadcaster()
gcdas(srcdir,
bcast.fork(
[bcast.join(),
objfile(readelf(bcast.join()))],
filenames(srcdir, gcov(merger(coverage)))))
return coverage
<CTRL-D>The bcast.fork(..) call fans out the data from gcdas(..) and the bcast.join() calls terminate each pipe and merge the result into filenames(..). Note that it is possible to use this pattern with many pipes of varying lengths!
Finally, we can use this code to gather coverage information for all ImageMagick source files and play with the result. Note that the total percentage covered (printed below) is slightly different than the number printed by the nested-loop implementation. This is due to the updated merging logic that is included in the coroutine version.
$ cat >> cocov.py
coverage = get_coverage(os.getcwd())
total_lines = sum([fc.lines for fc in coverage])
total_covered = sum([fc.percentage*fc.lines/100 for fc in coverage])
total_percentage = total_covered / total_lines
print total_percentage
<CTRL-D>
$python -i cocov.py
0.0560876868276
>>> for fc in coverage:
... if fc.percentage > 0:
... print fc.filename, fc.percentage
...
utilities/convert.c 100.0
wand/mogrify.c 2.35
./wand/mogrify-private.h 57.14
wand/convert.c 2.31
...Conclusion
In this post, I've explained how to apply a new Broadcaster pattern extended from the cobroadcast pattern in David Beazley's Curious Course on Coroutines to create a usable code coverage gathering script. Along the way I've also showed how applying coroutines can advance a monolithic, nested-loop algorithm implementation to a modular pipeline pipline that promotes maintainability and testability. Thanks for reading!
More By The Author
More In CERT/CC Vulnerabilities
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In CERT/CC Vulnerabilities
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed